 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceiving University Student's Opinions from Google App Reviews
Dec 10, 2023Google app market captures the school of thought of users from every corner of the globe via ratings and text reviews, in a multilinguistic arena. The potential information from the reviews cannot be extracted manually, due to its exponential growth. So, Sentiment analysis, by machine learning and deep learning algorithms employing NLP, explicitly uncovers and interprets the emotions. This study performs the sentiment classification of the app reviews and identifies the university student's behavior towards the app market via exploratory analysis. We applied machine learning algorithms using the TP, TF, and TF IDF text representation scheme and evaluated its performance on Bagging, an ensemble learning method. We used word embedding, Glove, on the deep learning paradigms. Our model was trained on Google app reviews and tested on Student's App Reviews(SAR). The various combinations of these algorithms were compared amongst each other using F score and accuracy and inferences were highlighted graphically. SVM, amongst other classifiers, gave fruitful accuracy(93.41%), F score(89%) on bigram and TF IDF scheme. Bagging enhanced the performance of LR and NB with accuracy of 87.88% and 86.69% and F score of 86% and 78% respectively. Overall, LSTM on Glove embedding recorded the highest accuracy(95.2%) and F score(88%).
* Accepted in Concurrency and Computation Practice and Experience
Comparative Sentiment Analysis of App Reviews
Jun 17, 2020
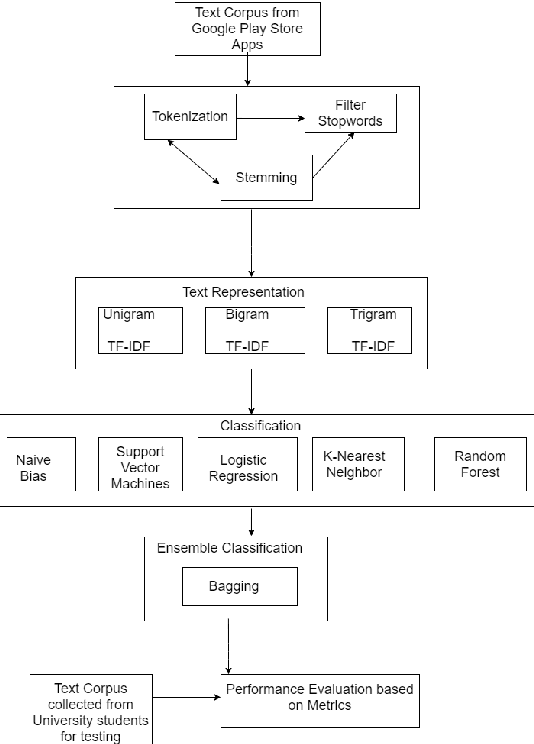

Google app market captures the school of thought of users via ratings and text reviews. The critique's viewpoint regarding an app is proportional to their satisfaction level. Consequently, this helps other users to gain insights before downloading or purchasing the apps. The potential information from the reviews can't be extracted manually, due to its exponential growth. Sentiment analysis, by machine learning algorithms employing NLP, is used to explicitly uncover and interpret the emotions. This study aims to perform the sentiment classification of the app reviews and identify the university students' behavior towards the app market. We applied machine learning algorithms using the TF-IDF text representation scheme and the performance was evaluated on the ensemble learning method. Our model was trained on Google reviews and tested on students' reviews. SVM recorded the maximum accuracy(93.37\%), F-score(0.88) on tri-gram + TF-IDF scheme. Bagging enhanced the performance of LR and NB with accuracy of 87.80\% and 85.5\% respectively.