 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisually Similar Pair Alignment for Robust Cross-Domain Object Detection
Apr 09, 2025Domain gaps between training data (source) and real-world environments (target) often degrade the performance of object detection models. Most existing methods aim to bridge this gap by aligning features across source and target domains but often fail to account for visual differences, such as color or orientation, in alignment pairs. This limitation leads to less effective domain adaptation, as the model struggles to manage both domain-specific shifts (e.g., fog) and visual variations simultaneously. In this work, we demonstrate for the first time, using a custom-built dataset, that aligning visually similar pairs significantly improves domain adaptation. Based on this insight, we propose a novel memory-based system to enhance domain alignment. This system stores precomputed features of foreground objects and background areas from the source domain, which are periodically updated during training. By retrieving visually similar source features for alignment with target foreground and background features, the model effectively addresses domain-specific differences while reducing the impact of visual variations. Extensive experiments across diverse domain shift scenarios validate our method's effectiveness, achieving 53.1 mAP on Foggy Cityscapes and 62.3 on Sim10k, surpassing prior state-of-the-art methods by 1.2 and 4.1 mAP, respectively.
Data Cleansing for GANs
Apr 01, 2025As the application of generative adversarial networks (GANs) expands, it becomes increasingly critical to develop a unified approach that improves performance across various generative tasks. One effective strategy that applies to any machine learning task is identifying harmful instances, whose removal improves the performance. While previous studies have successfully estimated these harmful training instances in supervised settings, their approaches are not easily applicable to GANs. The challenge lies in two requirements of the previous approaches that do not apply to GANs. First, previous approaches require that the absence of a training instance directly affects the parameters. However, in the training for GANs, the instances do not directly affect the generator's parameters since they are only fed into the discriminator. Second, previous approaches assume that the change in loss directly quantifies the harmfulness of the instance to a model's performance, while common types of GAN losses do not always reflect the generative performance. To overcome the first challenge, we propose influence estimation methods that use the Jacobian of the generator's gradient with respect to the discriminator's parameters (and vice versa). Such a Jacobian represents the indirect effect between two models: how removing an instance from the discriminator's training changes the generator's parameters. Second, we propose an instance evaluation scheme that measures the harmfulness of each training instance based on how a GAN evaluation metric (e.g., Inception score) is expected to change by the instance's removal. Furthermore, we demonstrate that removing the identified harmful instances significantly improves the generative performance on various GAN evaluation metrics.
MILA: Memory-Based Instance-Level Adaptation for Cross-Domain Object Detection
Sep 03, 2023
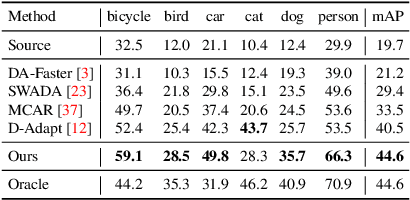
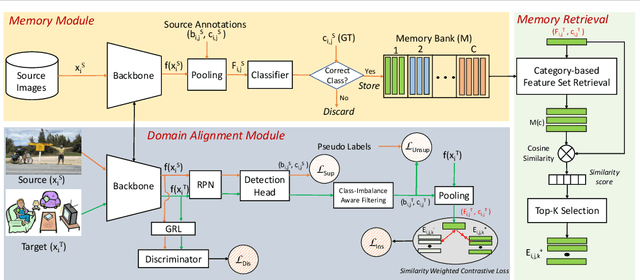
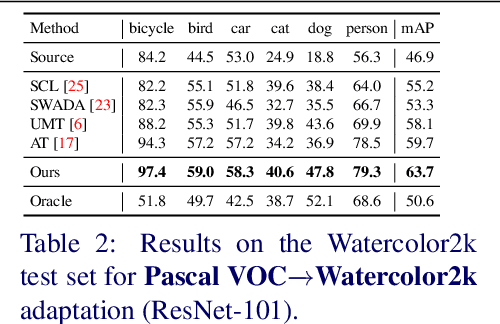
Cross-domain object detection is challenging, and it involves aligning labeled source and unlabeled target domains. Previous approaches have used adversarial training to align features at both image-level and instance-level. At the instance level, finding a suitable source sample that aligns with a target sample is crucial. A source sample is considered suitable if it differs from the target sample only in domain, without differences in unimportant characteristics such as orientation and color, which can hinder the model's focus on aligning the domain difference. However, existing instance-level feature alignment methods struggle to find suitable source instances because their search scope is limited to mini-batches. Mini-batches are often so small in size that they do not always contain suitable source instances. The insufficient diversity of mini-batches becomes problematic particularly when the target instances have high intra-class variance. To address this issue, we propose a memory-based instance-level domain adaptation framework. Our method aligns a target instance with the most similar source instance of the same category retrieved from a memory storage. Specifically, we introduce a memory module that dynamically stores the pooled features of all labeled source instances, categorized by their labels. Additionally, we introduce a simple yet effective memory retrieval module that retrieves a set of matching memory slots for target instances. Our experiments on various domain shift scenarios demonstrate that our approach outperforms existing non-memory-based methods significantly.
Prompter: Utilizing Large Language Model Prompting for a Data Efficient Embodied Instruction Following
Nov 07, 2022Embodied Instruction Following (EIF) studies how mobile manipulator robots should be controlled to accomplish long-horizon tasks specified by natural language instructions. While most research on EIF are conducted in simulators, the ultimate goal of the field is to deploy the agents in real life. As such, it is important to minimize the data cost required for training an agent, to help the transition from sim to real. However, many studies only focus on the performance and overlook the data cost -- modules that require separate training on extra data are often introduced without a consideration on deployability. In this work, we propose FILM++ which extends the existing work FILM with modifications that do not require extra data. While all data-driven modules are kept constant, FILM++ more than doubles FILM's performance. Furthermore, we propose Prompter, which replaces FILM++'s semantic search module with language model prompting. Unlike FILM++'s implementation that requires training on extra sets of data, no training is needed for our prompting based implementation while achieving better or at least comparable performance. Prompter achieves 42.64% and 45.72% on the ALFRED benchmark with high-level instructions only and with step-by-step instructions, respectively, outperforming the previous state of the art by 6.57% and 10.31%.
Difficulty-Net: Learning to Predict Difficulty for Long-Tailed Recognition
Sep 07, 2022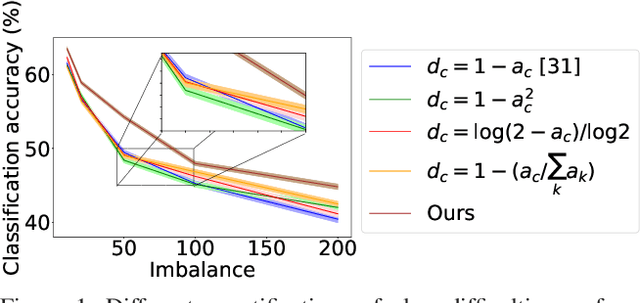

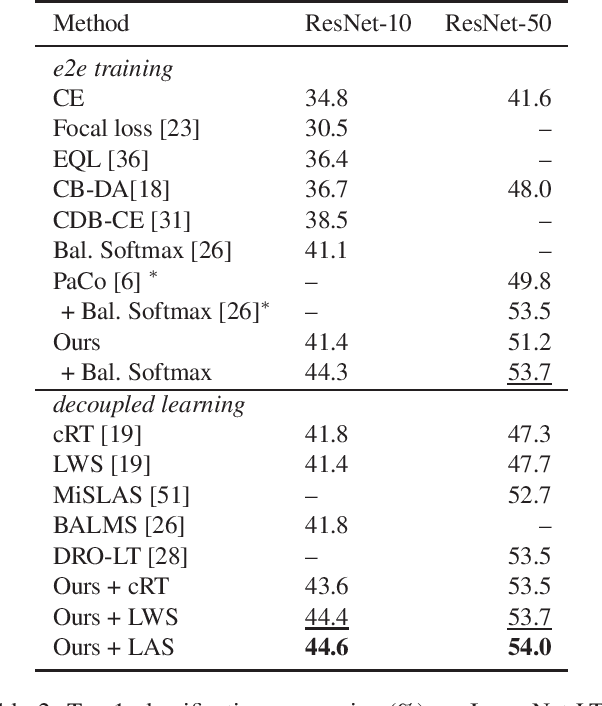
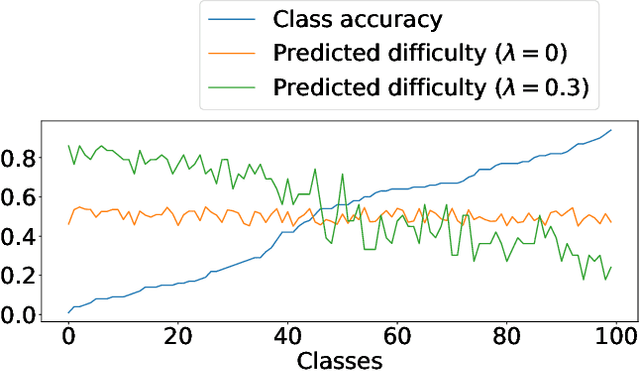
Long-tailed datasets, where head classes comprise much more training samples than tail classes, cause recognition models to get biased towards the head classes. Weighted loss is one of the most popular ways of mitigating this issue, and a recent work has suggested that class-difficulty might be a better clue than conventionally used class-frequency to decide the distribution of weights. A heuristic formulation was used in the previous work for quantifying the difficulty, but we empirically find that the optimal formulation varies depending on the characteristics of datasets. Therefore, we propose Difficulty-Net, which learns to predict the difficulty of classes using the model's performance in a meta-learning framework. To make it learn reasonable difficulty of a class within the context of other classes, we newly introduce two key concepts, namely the relative difficulty and the driver loss. The former helps Difficulty-Net take other classes into account when calculating difficulty of a class, while the latter is indispensable for guiding the learning to a meaningful direction. Extensive experiments on popular long-tailed datasets demonstrated the effectiveness of the proposed method, and it achieved state-of-the-art performance on multiple long-tailed datasets.
Class-Difficulty Based Methods for Long-Tailed Visual Recognition
Jul 29, 2022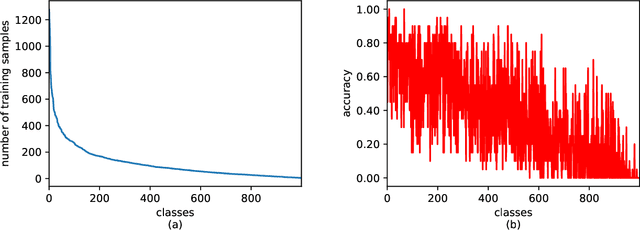
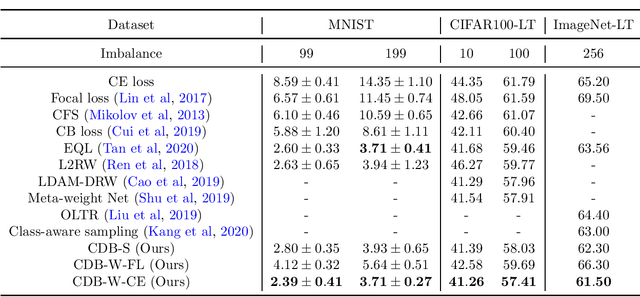
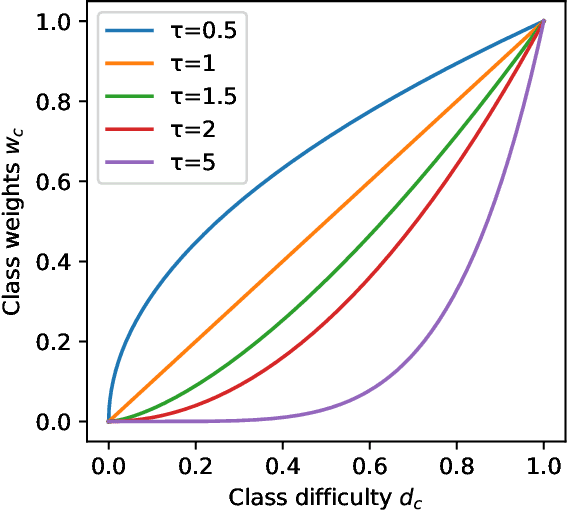

Long-tailed datasets are very frequently encountered in real-world use cases where few classes or categories (known as majority or head classes) have higher number of data samples compared to the other classes (known as minority or tail classes). Training deep neural networks on such datasets gives results biased towards the head classes. So far, researchers have come up with multiple weighted loss and data re-sampling techniques in efforts to reduce the bias. However, most of such techniques assume that the tail classes are always the most difficult classes to learn and therefore need more weightage or attention. Here, we argue that the assumption might not always hold true. Therefore, we propose a novel approach to dynamically measure the instantaneous difficulty of each class during the training phase of the model. Further, we use the difficulty measures of each class to design a novel weighted loss technique called `class-wise difficulty based weighted (CDB-W) loss' and a novel data sampling technique called `class-wise difficulty based sampling (CDB-S)'. To verify the wide-scale usability of our CDB methods, we conducted extensive experiments on multiple tasks such as image classification, object detection, instance segmentation and video-action classification. Results verified that CDB-W loss and CDB-S could achieve state-of-the-art results on many class-imbalanced datasets such as ImageNet-LT, LVIS and EGTEA, that resemble real-world use cases.
Human-error-potential Estimation based on Wearable Biometric Sensors
Nov 15, 2021
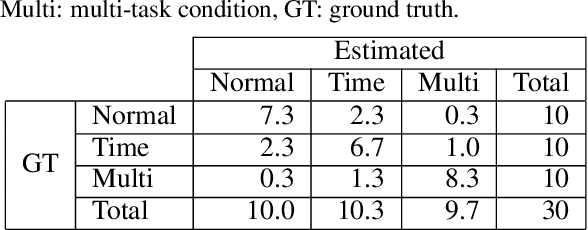

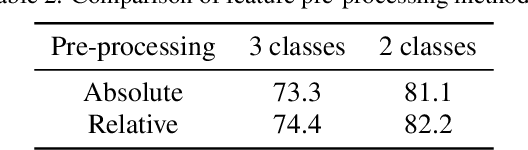
This study tackles on a new problem of estimating human-error potential on a shop floor on the basis of wearable sensors. Unlike existing studies that utilize biometric sensing technology to estimate people's internal state such as fatigue and mental stress, we attempt to estimate the human-error potential in a situation where a target person does not stay calm, which is much more difficult as sensor noise significantly increases. We propose a novel formulation, in which the human-error-potential estimation problem is reduced to a classification problem, and introduce a new method that can be used for solving the classification problem even with noisy sensing data. The key ideas are to model the process of calculating biometric indices probabilistically so that the prior knowledge on the biometric indices can be integrated, and to utilize the features that represent the movement of target persons in combination with biometric features. The experimental analysis showed that our method effectively estimates the human-error potential.
Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention
Sep 07, 2021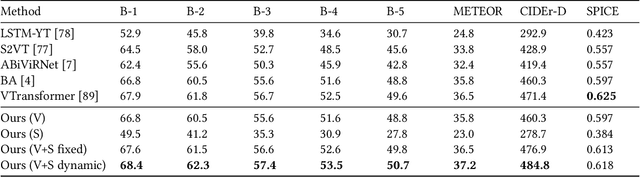


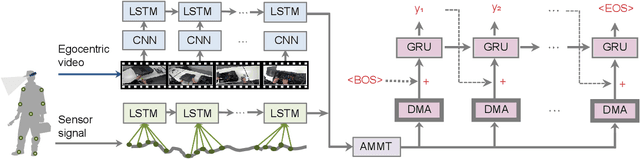
Automatically describing video, or video captioning, has been widely studied in the multimedia field. This paper proposes a new task of sensor-augmented egocentric-video captioning, a newly constructed dataset for it called MMAC Captions, and a method for the newly proposed task that effectively utilizes multi-modal data of video and motion sensors, or inertial measurement units (IMUs). While conventional video captioning tasks have difficulty in dealing with detailed descriptions of human activities due to the limited view of a fixed camera, egocentric vision has greater potential to be used for generating the finer-grained descriptions of human activities on the basis of a much closer view. In addition, we utilize wearable-sensor data as auxiliary information to mitigate the inherent problems in egocentric vision: motion blur, self-occlusion, and out-of-camera-range activities. We propose a method for effectively utilizing the sensor data in combination with the video data on the basis of an attention mechanism that dynamically determines the modality that requires more attention, taking the contextual information into account. We compared the proposed sensor-fusion method with strong baselines on the MMAC Captions dataset and found that using sensor data as supplementary information to the egocentric-video data was beneficial, and that our proposed method outperformed the strong baselines, demonstrating the effectiveness of the proposed method.
QPIC: Query-Based Pairwise Human-Object Interaction Detection with Image-Wide Contextual Information
Mar 09, 2021
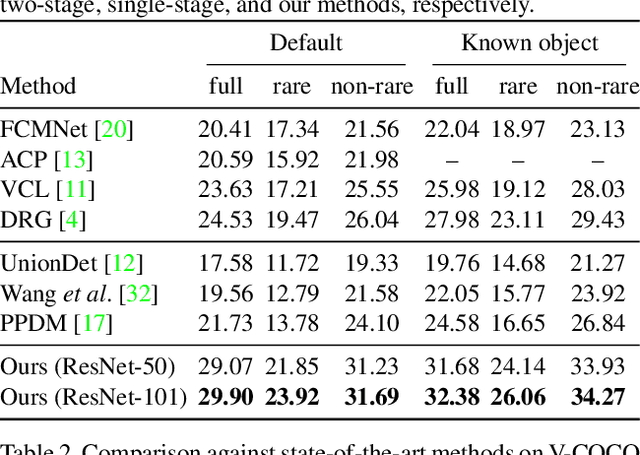
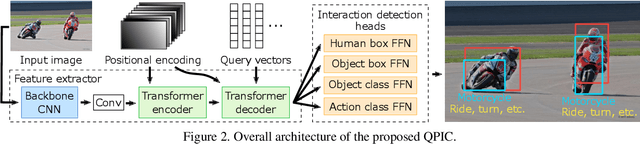

We propose a simple, intuitive yet powerful method for human-object interaction (HOI) detection. HOIs are so diverse in spatial distribution in an image that existing CNN-based methods face the following three major drawbacks; they cannot leverage image-wide features due to CNN's locality, they rely on a manually defined location-of-interest for the feature aggregation, which sometimes does not cover contextually important regions, and they cannot help but mix up the features for multiple HOI instances if they are located closely. To overcome these drawbacks, we propose a transformer-based feature extractor, in which an attention mechanism and query-based detection play key roles. The attention mechanism is effective in aggregating contextually important information image-wide, while the queries, which we design in such a way that each query captures at most one human-object pair, can avoid mixing up the features from multiple instances. This transformer-based feature extractor produces so effective embeddings that the subsequent detection heads may be fairly simple and intuitive. The extensive analysis reveals that the proposed method successfully extracts contextually important features, and thus outperforms existing methods by large margins (5.37 mAP on HICO-DET, and 5.7 mAP on V-COCO). The source codes are available at $\href{https://github.com/hitachi-rd-cv/qpic}{\text{this https URL}}$.
Influence Estimation for Generative Adversarial Networks
Jan 20, 2021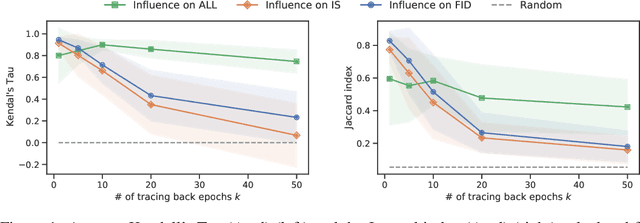

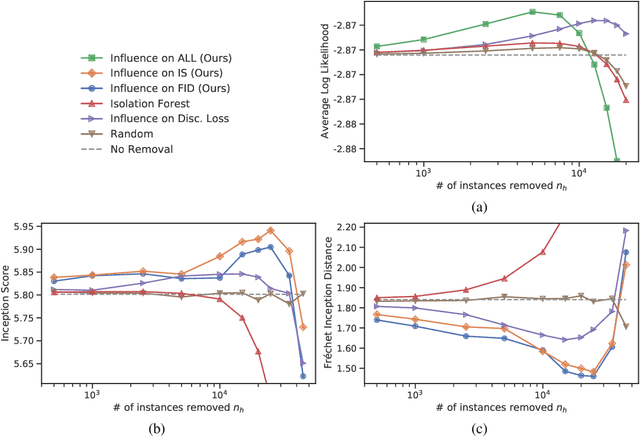

Identifying harmful instances, whose absence in a training dataset improves model performance, is important for building better machine learning models. Although previous studies have succeeded in estimating harmful instances under supervised settings, they cannot be trivially extended to generative adversarial networks (GANs). This is because previous approaches require that (1) the absence of a training instance directly affects the loss value and that (2) the change in the loss directly measures the harmfulness of the instance for the performance of a model. In GAN training, however, neither of the requirements is satisfied. This is because, (1) the generator's loss is not directly affected by the training instances as they are not part of the generator's training steps, and (2) the values of GAN's losses normally do not capture the generative performance of a model. To this end, (1) we propose an influence estimation method that uses the Jacobian of the gradient of the generator's loss with respect to the discriminator's parameters (and vice versa) to trace how the absence of an instance in the discriminator's training affects the generator's parameters, and (2) we propose a novel evaluation scheme, in which we assess harmfulness of each training instance on the basis of how GAN evaluation metric (e.g., inception score) is expect to change due to the removal of the instance. We experimentally verified that our influence estimation method correctly inferred the changes in GAN evaluation metrics. Further, we demonstrated that the removal of the identified harmful instances effectively improved the model's generative performance with respect to various GAN evaluation metrics.