 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrime and Reach: Synthesising Body Motion for Gaze-Primed Object Reach
Dec 18, 2025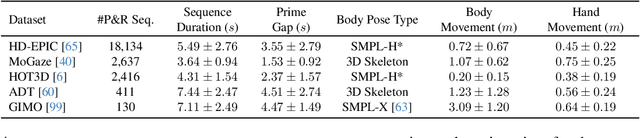



Human motion generation is a challenging task that aims to create realistic motion imitating natural human behaviour. We focus on the well-studied behaviour of priming an object/location for pick up or put down -- that is, the spotting of an object/location from a distance, known as gaze priming, followed by the motion of approaching and reaching the target location. To that end, we curate, for the first time, 23.7K gaze-primed human motion sequences for reaching target object locations from five publicly available datasets, i.e., HD-EPIC, MoGaze, HOT3D, ADT, and GIMO. We pre-train a text-conditioned diffusion-based motion generation model, then fine-tune it conditioned on goal pose or location, on our curated sequences. Importantly, we evaluate the ability of the generated motion to imitate natural human movement through several metrics, including the 'Reach Success' and a newly introduced 'Prime Success' metric. On the largest dataset, HD-EPIC, our model achieves 60% prime success and 89% reach success when conditioned on the goal object location.
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025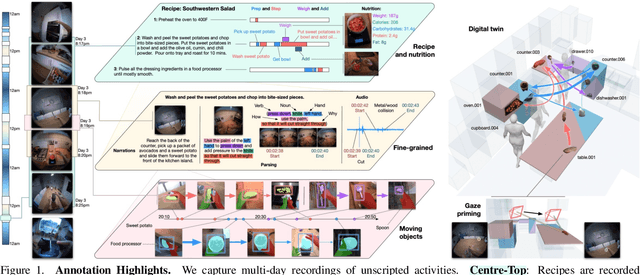
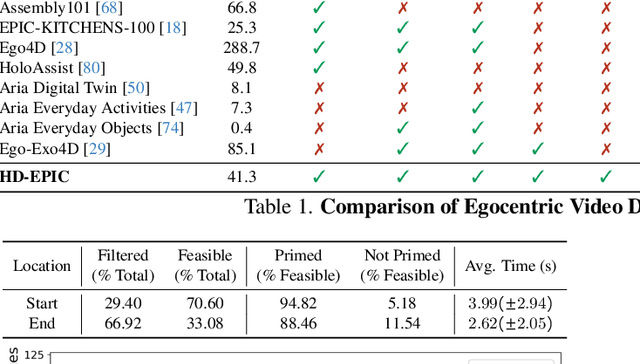

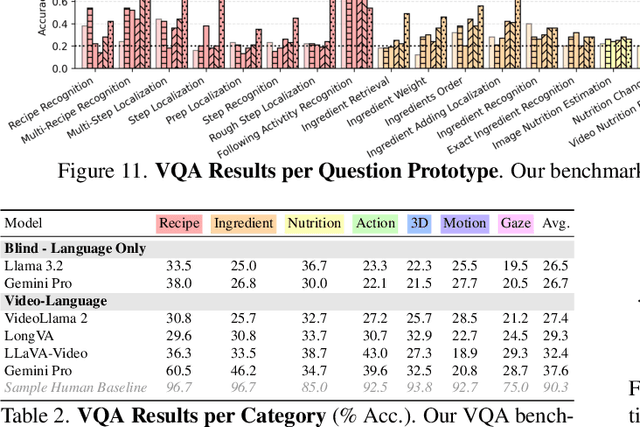
We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
Every Shot Counts: Using Exemplars for Repetition Counting in Videos
Mar 26, 2024



Video repetition counting infers the number of repetitions of recurring actions or motion within a video. We propose an exemplar-based approach that discovers visual correspondence of video exemplars across repetitions within target videos. Our proposed Every Shot Counts (ESCounts) model is an attention-based encoder-decoder that encodes videos of varying lengths alongside exemplars from the same and different videos. In training, ESCounts regresses locations of high correspondence to the exemplars within the video. In tandem, our method learns a latent that encodes representations of general repetitive motions, which we use for exemplar-free, zero-shot inference. Extensive experiments over commonly used datasets (RepCount, Countix, and UCFRep) showcase ESCounts obtaining state-of-the-art performance across all three datasets. On RepCount, ESCounts increases the off-by-one from 0.39 to 0.56 and decreases the mean absolute error from 0.38 to 0.21. Detailed ablations further demonstrate the effectiveness of our method.
MILA: Memory-Based Instance-Level Adaptation for Cross-Domain Object Detection
Sep 03, 2023
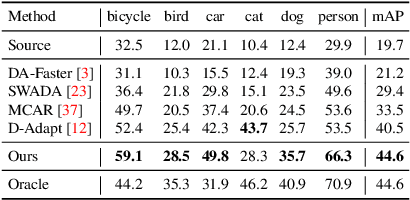
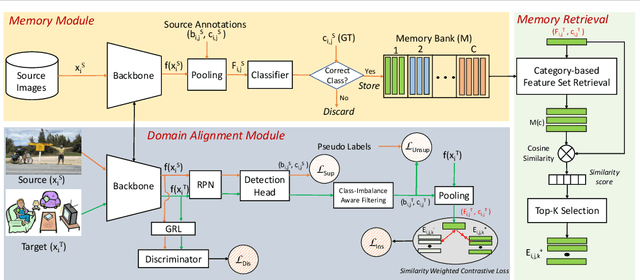
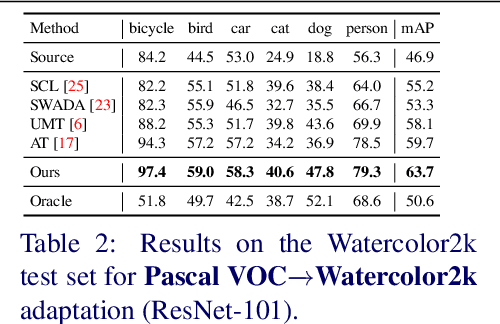
Cross-domain object detection is challenging, and it involves aligning labeled source and unlabeled target domains. Previous approaches have used adversarial training to align features at both image-level and instance-level. At the instance level, finding a suitable source sample that aligns with a target sample is crucial. A source sample is considered suitable if it differs from the target sample only in domain, without differences in unimportant characteristics such as orientation and color, which can hinder the model's focus on aligning the domain difference. However, existing instance-level feature alignment methods struggle to find suitable source instances because their search scope is limited to mini-batches. Mini-batches are often so small in size that they do not always contain suitable source instances. The insufficient diversity of mini-batches becomes problematic particularly when the target instances have high intra-class variance. To address this issue, we propose a memory-based instance-level domain adaptation framework. Our method aligns a target instance with the most similar source instance of the same category retrieved from a memory storage. Specifically, we introduce a memory module that dynamically stores the pooled features of all labeled source instances, categorized by their labels. Additionally, we introduce a simple yet effective memory retrieval module that retrieves a set of matching memory slots for target instances. Our experiments on various domain shift scenarios demonstrate that our approach outperforms existing non-memory-based methods significantly.
Use Your Head: Improving Long-Tail Video Recognition
Apr 03, 2023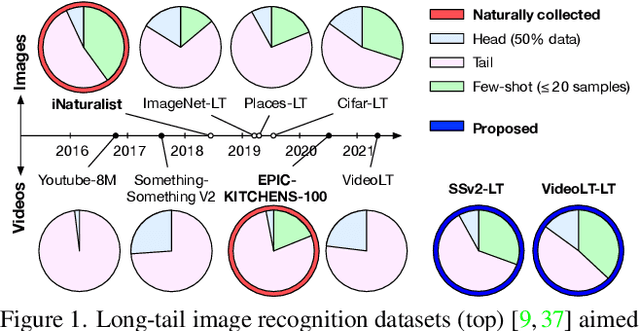
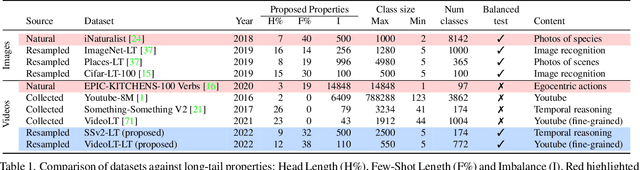
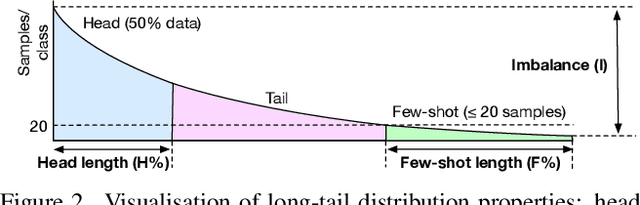

This paper presents an investigation into long-tail video recognition. We demonstrate that, unlike naturally-collected video datasets and existing long-tail image benchmarks, current video benchmarks fall short on multiple long-tailed properties. Most critically, they lack few-shot classes in their tails. In response, we propose new video benchmarks that better assess long-tail recognition, by sampling subsets from two datasets: SSv2 and VideoLT. We then propose a method, Long-Tail Mixed Reconstruction, which reduces overfitting to instances from few-shot classes by reconstructing them as weighted combinations of samples from head classes. LMR then employs label mixing to learn robust decision boundaries. It achieves state-of-the-art average class accuracy on EPIC-KITCHENS and the proposed SSv2-LT and VideoLT-LT. Benchmarks and code at: tobyperrett.github.io/lmr
Difficulty-Net: Learning to Predict Difficulty for Long-Tailed Recognition
Sep 07, 2022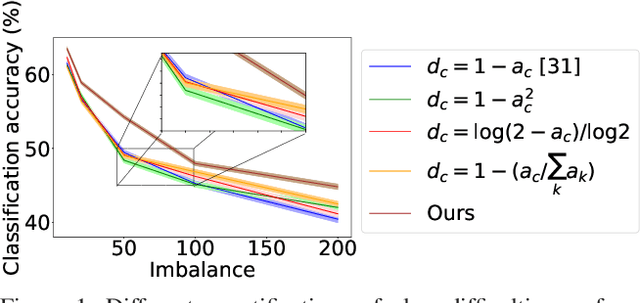

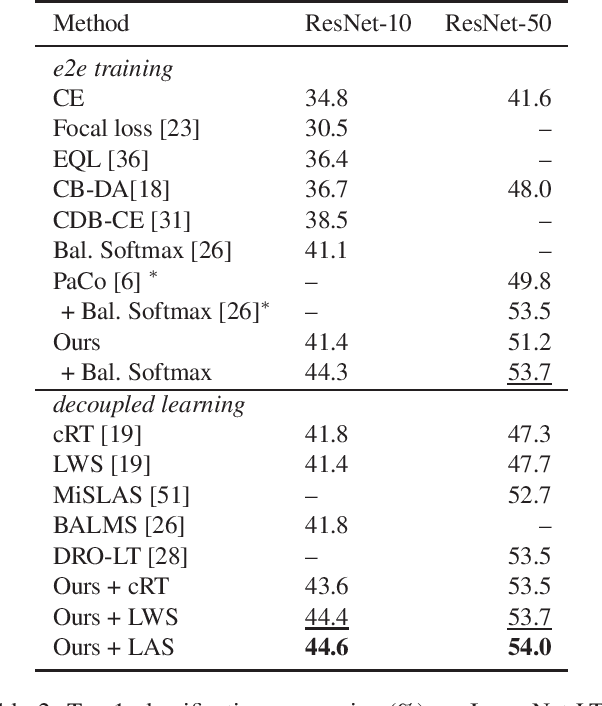
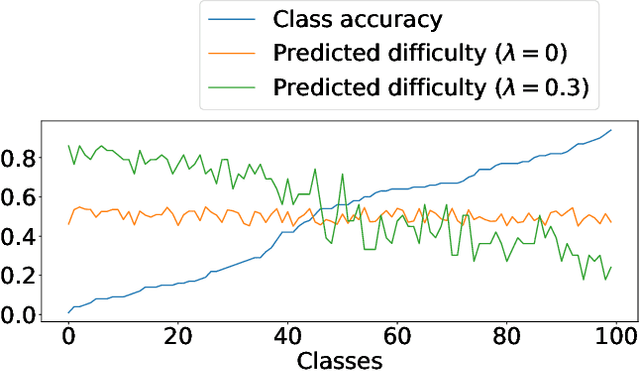
Long-tailed datasets, where head classes comprise much more training samples than tail classes, cause recognition models to get biased towards the head classes. Weighted loss is one of the most popular ways of mitigating this issue, and a recent work has suggested that class-difficulty might be a better clue than conventionally used class-frequency to decide the distribution of weights. A heuristic formulation was used in the previous work for quantifying the difficulty, but we empirically find that the optimal formulation varies depending on the characteristics of datasets. Therefore, we propose Difficulty-Net, which learns to predict the difficulty of classes using the model's performance in a meta-learning framework. To make it learn reasonable difficulty of a class within the context of other classes, we newly introduce two key concepts, namely the relative difficulty and the driver loss. The former helps Difficulty-Net take other classes into account when calculating difficulty of a class, while the latter is indispensable for guiding the learning to a meaningful direction. Extensive experiments on popular long-tailed datasets demonstrated the effectiveness of the proposed method, and it achieved state-of-the-art performance on multiple long-tailed datasets.
Class-Difficulty Based Methods for Long-Tailed Visual Recognition
Jul 29, 2022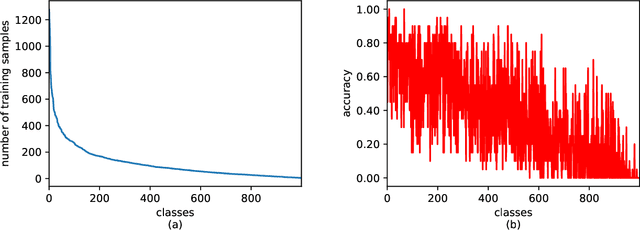
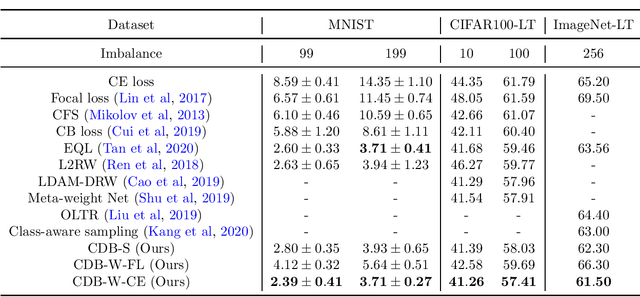
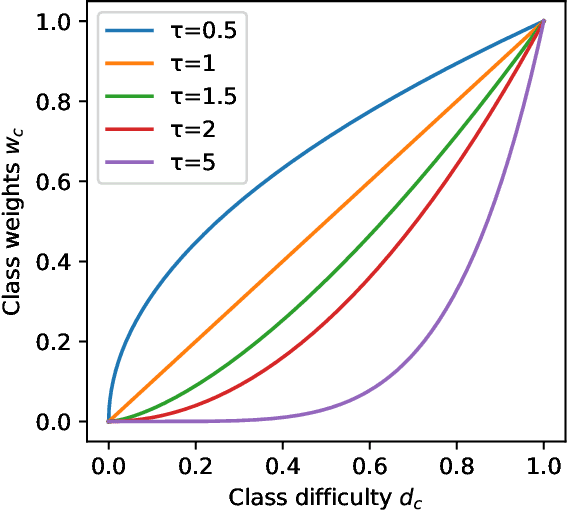

Long-tailed datasets are very frequently encountered in real-world use cases where few classes or categories (known as majority or head classes) have higher number of data samples compared to the other classes (known as minority or tail classes). Training deep neural networks on such datasets gives results biased towards the head classes. So far, researchers have come up with multiple weighted loss and data re-sampling techniques in efforts to reduce the bias. However, most of such techniques assume that the tail classes are always the most difficult classes to learn and therefore need more weightage or attention. Here, we argue that the assumption might not always hold true. Therefore, we propose a novel approach to dynamically measure the instantaneous difficulty of each class during the training phase of the model. Further, we use the difficulty measures of each class to design a novel weighted loss technique called `class-wise difficulty based weighted (CDB-W) loss' and a novel data sampling technique called `class-wise difficulty based sampling (CDB-S)'. To verify the wide-scale usability of our CDB methods, we conducted extensive experiments on multiple tasks such as image classification, object detection, instance segmentation and video-action classification. Results verified that CDB-W loss and CDB-S could achieve state-of-the-art results on many class-imbalanced datasets such as ImageNet-LT, LVIS and EGTEA, that resemble real-world use cases.
Class-Wise Difficulty-Balanced Loss for Solving Class-Imbalance
Oct 05, 2020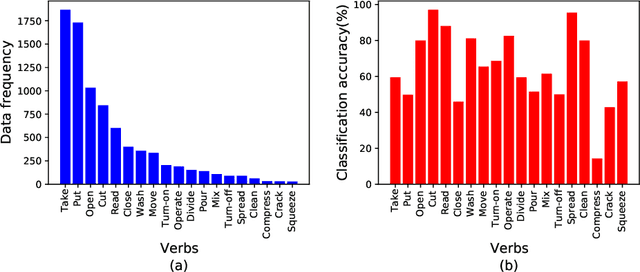
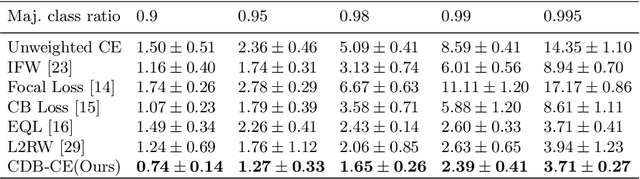
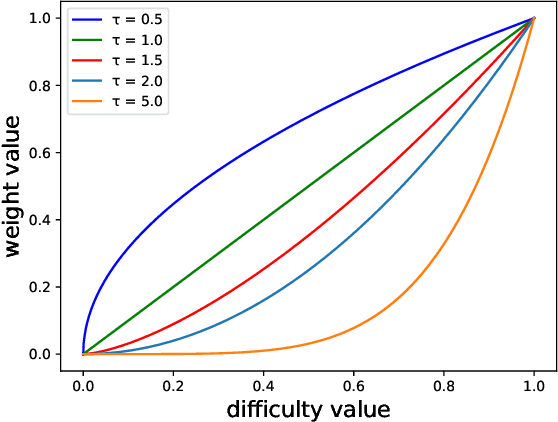
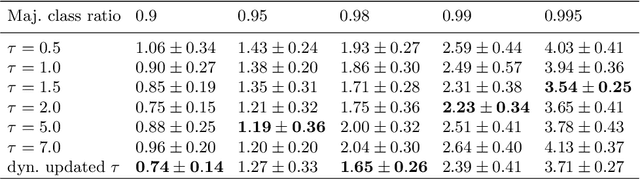
Class-imbalance is one of the major challenges in real world datasets, where a few classes (called majority classes) constitute much more data samples than the rest (called minority classes). Learning deep neural networks using such datasets leads to performances that are typically biased towards the majority classes. Most of the prior works try to solve class-imbalance by assigning more weights to the minority classes in various manners (e.g., data re-sampling, cost-sensitive learning). However, we argue that the number of available training data may not be always a good clue to determine the weighting strategy because some of the minority classes might be sufficiently represented even by a small number of training data. Overweighting samples of such classes can lead to drop in the model's overall performance. We claim that the 'difficulty' of a class as perceived by the model is more important to determine the weighting. In this light, we propose a novel loss function named Class-wise Difficulty-Balanced loss, or CDB loss, which dynamically distributes weights to each sample according to the difficulty of the class that the sample belongs to. Note that the assigned weights dynamically change as the 'difficulty' for the model may change with the learning progress. Extensive experiments are conducted on both image (artificially induced class-imbalanced MNIST, long-tailed CIFAR and ImageNet-LT) and video (EGTEA) datasets. The results show that CDB loss consistently outperforms the recently proposed loss functions on class-imbalanced datasets irrespective of the data type (i.e., video or image).