 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposite Sketch+Text Queries for Retrieving Objects with Elusive Names and Complex Interactions
Feb 12, 2025
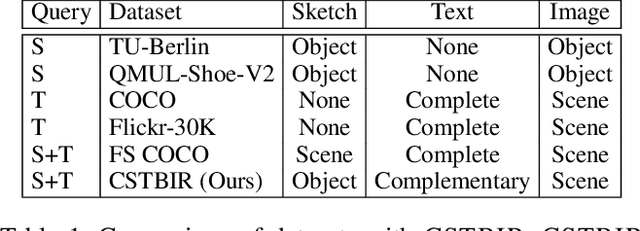

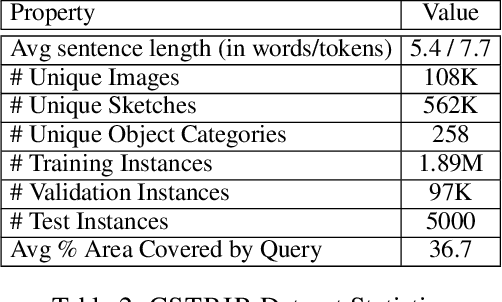
Non-native speakers with limited vocabulary often struggle to name specific objects despite being able to visualize them, e.g., people outside Australia searching for numbats. Further, users may want to search for such elusive objects with difficult-to-sketch interactions, e.g., numbat digging in the ground. In such common but complex situations, users desire a search interface that accepts composite multimodal queries comprising hand-drawn sketches of difficult-to-name but easy-to-draw objects and text describing difficult-to-sketch but easy-to-verbalize object attributes or interaction with the scene. This novel problem statement distinctly differs from the previously well-researched TBIR (text-based image retrieval) and SBIR (sketch-based image retrieval) problems. To study this under-explored task, we curate a dataset, CSTBIR (Composite Sketch+Text Based Image Retrieval), consisting of approx. 2M queries and 108K natural scene images. Further, as a solution to this problem, we propose a pretrained multimodal transformer-based baseline, STNET (Sketch+Text Network), that uses a hand-drawn sketch to localize relevant objects in the natural scene image, and encodes the text and image to perform image retrieval. In addition to contrastive learning, we propose multiple training objectives that improve the performance of our model. Extensive experiments show that our proposed method outperforms several state-of-the-art retrieval methods for text-only, sketch-only, and composite query modalities. We make the dataset and code available at our project website.
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025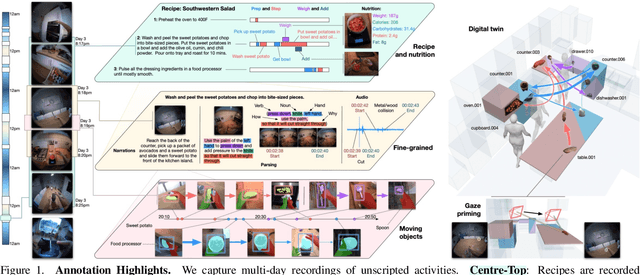
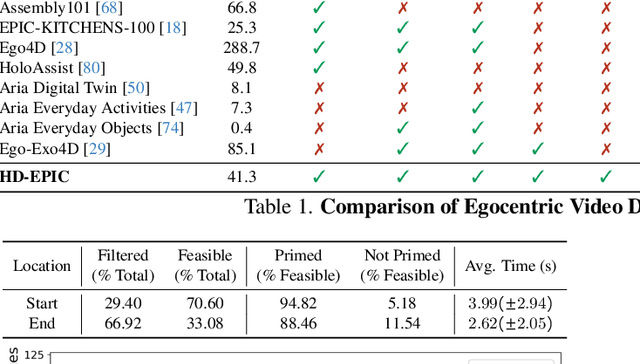

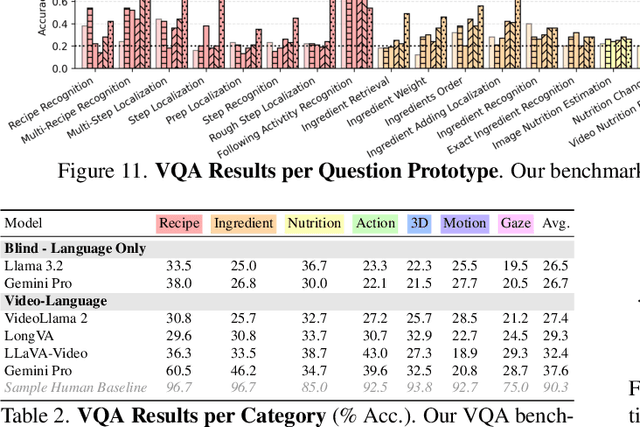
We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
Towards Making Flowchart Images Machine Interpretable
Jan 29, 2025Computer programming textbooks and software documentations often contain flowcharts to illustrate the flow of an algorithm or procedure. Modern OCR engines often tag these flowcharts as graphics and ignore them in further processing. In this paper, we work towards making flowchart images machine-interpretable by converting them to executable Python codes. To this end, inspired by the recent success in natural language to code generation literature, we present a novel transformer-based framework, namely FloCo-T5. Our model is well-suited for this task,as it can effectively learn semantics, structure, and patterns of programming languages, which it leverages to generate syntactically correct code. We also used a task-specific pre-training objective to pre-train FloCo-T5 using a large number of logic-preserving augmented code samples. Further, to perform a rigorous study of this problem, we introduce theFloCo dataset that contains 11,884 flowchart images and their corresponding Python codes. Our experiments show promising results, and FloCo-T5 clearly outperforms related competitive baselines on code generation metrics. We make our dataset and implementation publicly available.
ShowHowTo: Generating Scene-Conditioned Step-by-Step Visual Instructions
Dec 02, 2024



The goal of this work is to generate step-by-step visual instructions in the form of a sequence of images, given an input image that provides the scene context and the sequence of textual instructions. This is a challenging problem as it requires generating multi-step image sequences to achieve a complex goal while being grounded in a specific environment. Part of the challenge stems from the lack of large-scale training data for this problem. The contribution of this work is thus three-fold. First, we introduce an automatic approach for collecting large step-by-step visual instruction training data from instructional videos. We apply this approach to one million videos and create a large-scale, high-quality dataset of 0.6M sequences of image-text pairs. Second, we develop and train ShowHowTo, a video diffusion model capable of generating step-by-step visual instructions consistent with the provided input image. Third, we evaluate the generated image sequences across three dimensions of accuracy (step, scene, and task) and show our model achieves state-of-the-art results on all of them. Our code, dataset, and trained models are publicly available.
Towards Scene-Text to Scene-Text Translation
Aug 06, 2023In this work, we study the task of ``visually" translating scene text from a source language (e.g., English) to a target language (e.g., Chinese). Visual translation involves not just the recognition and translation of scene text but also the generation of the translated image that preserves visual features of the text, such as font, size, and background. There are several challenges associated with this task, such as interpolating font to unseen characters and preserving text size and the background. To address these, we introduce VTNet, a novel conditional diffusion-based method. To train the VTNet, we create a synthetic cross-lingual dataset of 600K samples of scene text images in six popular languages, including English, Hindi, Tamil, Chinese, Bengali, and German. We evaluate the performance of VTnet through extensive experiments and comparisons to related methods. Our model also surpasses the previous state-of-the-art results on the conventional scene-text editing benchmarks. Further, we present rigorous qualitative studies to understand the strengths and shortcomings of our model. Results show that our approach generalizes well to unseen words and fonts. We firmly believe our work can benefit real-world applications, such as text translation using a phone camera and translating educational materials. Code and data will be made publicly available.
COFAR: Commonsense and Factual Reasoning in Image Search
Oct 16, 2022

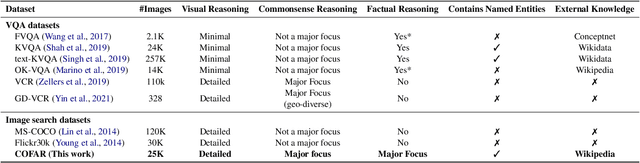
One characteristic that makes humans superior to modern artificially intelligent models is the ability to interpret images beyond what is visually apparent. Consider the following two natural language search queries - (i) "a queue of customers patiently waiting to buy ice cream" and (ii) "a queue of tourists going to see a famous Mughal architecture in India." Interpreting these queries requires one to reason with (i) Commonsense such as interpreting people as customers or tourists, actions as waiting to buy or going to see; and (ii) Fact or world knowledge associated with named visual entities, for example, whether the store in the image sells ice cream or whether the landmark in the image is a Mughal architecture located in India. Such reasoning goes beyond just visual recognition. To enable both commonsense and factual reasoning in the image search, we present a unified framework, namely Knowledge Retrieval-Augmented Multimodal Transformer (KRAMT), that treats the named visual entities in an image as a gateway to encyclopedic knowledge and leverages them along with natural language query to ground relevant knowledge. Further, KRAMT seamlessly integrates visual content and grounded knowledge to learn alignment between images and search queries. This unified framework is then used to perform image search requiring commonsense and factual reasoning. The retrieval performance of KRAMT is evaluated and compared with related approaches on a new dataset we introduce - namely COFAR. We make our code and dataset available at https://vl2g.github.io/projects/cofar