 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIND: Toward Multimodal Financial Reasoning and Question Answering for Indic Languages
May 13, 2026Financial decision-making in multilingual settings demands accurate numerical reasoning grounded in diverse modalities, yet existing benchmarks largely overlook this high-stakes, real-world challenge, especially for Indic languages. We introduce FinVQA, a benchmark for evaluating financial numerical and multimodal reasoning in multilingual Indic contexts. FinVQA spans English, Hindi, Bengali, Marathi, Gujarati, and Tamil, and comprises 18,900 samples across 14 financial domains. The dataset captures diverse reasoning paradigms under realistic constraints, and is structured across three difficulty levels (easy, moderate, hard) and four question formats: multiple choice, fill-in-the-blank, table matching, and true/false. To address these challenges, we propose FIND, a framework that combines supervised fine-tuning with constraint-aware decoding to promote faithful numerical reasoning, robust multimodal grounding, and structured decision-making. Together, FinVQA and FIND establish a rigorous evaluation and modeling paradigm for high-stakes multilingual multimodal financial reasoning.
DocQAC: Adaptive Trie-Guided Decoding for Effective In-Document Query Auto-Completion
Apr 20, 2026Query auto-completion (QAC) has been widely studied in the context of web search, yet remains underexplored for in-document search, which we term DocQAC. DocQAC aims to enhance search productivity within long documents by helping users craft faster, more precise queries, even for complex or hard-to-spell terms. While global historical queries are available to both WebQAC and DocQAC, DocQAC uniquely accesses document-specific context, including the current document's content and its specific history of user query interactions. To address this setting, we propose a novel adaptive trie-guided decoding framework that uses user query prefixes to softly steer language models toward high-quality completions. Our approach introduces an adaptive penalty mechanism with tunable hyperparameters, enabling a principled trade-off between model confidence and trie-based guidance. To efficiently incorporate document context, we explore retrieval-augmented generation (RAG) and lightweight contextual document signals such as titles, keyphrases, and summaries. When applied to encoder-decoder models like T5 and BART, our trie-guided framework outperforms strong baselines and even surpasses much larger instruction-tuned models such as LLaMA-3 and Phi-3 on seen queries across both seen and unseen documents. This demonstrates its practicality for real-world DocQAC deployments, where efficiency and scalability are critical. We evaluate our method on a newly introduced DocQAC benchmark derived from ORCAS, enriched with query-document pairs. We make both the DocQAC dataset (https://bit.ly/3IGEkbH) and code (https://github.com/rahcode7/DocQAC) publicly available.
Text2Arch: A Dataset for Generating Scientific Architecture Diagrams from Natural Language Descriptions
Apr 16, 2026Communicating complex system designs or scientific processes through text alone is inefficient and prone to ambiguity. A system that automatically generates scientific architecture diagrams from text with high semantic fidelity can be useful in multiple applications like enterprise architecture visualization, AI-driven software design, and educational content creation. Hence, in this paper, we focus on leveraging language models to perform semantic understanding of the input text description to generate intermediate code that can be processed to generate high-fidelity architecture diagrams. Unfortunately, no clean large-scale open-access dataset exists, implying lack of any effective open models for this task. Hence, we contribute a comprehensive dataset, \system, comprising scientific architecture images, their corresponding textual descriptions, and associated DOT code representations. Leveraging this resource, we fine-tune a suite of small language models, and also perform in-context learning using GPT-4o. Through extensive experimentation, we show that \system{} models significantly outperform existing baseline models like DiagramAgent and perform at par with in-context learning-based generations from GPT-4o. We make the code, data and models publicly available.
Fractional Rotation, Full Potential? Investigating Performance and Convergence of Partial RoPE
Mar 12, 2026Rotary Positional Embedding (RoPE) is a common choice in transformer architectures for encoding relative positional information. Although earlier work has examined omitting RoPE in specific layers, the effect of varying the fraction of hidden dimensions that receive rotary transformations remains largely unexplored. This design choice can yield substantial memory savings, which becomes especially significant at long context lengths. We find up to 10x memory savings over the standard RoPE cache, while achieving comparable final loss. In this work, we present a systematic study examining the impact of partial RoPE on training dynamics and convergence across architectures and datasets. Our findings uncover several notable patterns: (1) applying RoPE to only a small fraction of dimensions (around 10%) achieves convergence comparable to using full RoPE; (2) these trends hold consistently across model size, sequence lengths and datasets of varying quality and architectures, with higher-quality data resulting in lower overall loss and similar benchmark performance; and (3) some models trained with NoPE (No Positional Encoding) showcase unstable learning trajectories, which can be alleviated through minimal RoPE application or QK-Norm which converges to a higher loss. Together, these results offer practical guidance for model designers aiming to balance efficiency and training stability, while emphasizing the previously overlooked importance of partial RoPE.
In Agents We Trust, but Who Do Agents Trust? Latent Source Preferences Steer LLM Generations
Feb 17, 2026Agents based on Large Language Models (LLMs) are increasingly being deployed as interfaces to information on online platforms. These agents filter, prioritize, and synthesize information retrieved from the platforms' back-end databases or via web search. In these scenarios, LLM agents govern the information users receive, by drawing users' attention to particular instances of retrieved information at the expense of others. While much prior work has focused on biases in the information LLMs themselves generate, less attention has been paid to the factors that influence what information LLMs select and present to users. We hypothesize that when information is attributed to specific sources (e.g., particular publishers, journals, or platforms), current LLMs exhibit systematic latent source preferences- that is, they prioritize information from some sources over others. Through controlled experiments on twelve LLMs from six model providers, spanning both synthetic and real-world tasks, we find that several models consistently exhibit strong and predictable source preferences. These preferences are sensitive to contextual framing, can outweigh the influence of content itself, and persist despite explicit prompting to avoid them. They also help explain phenomena such as the observed left-leaning skew in news recommendations in prior work. Our findings advocate for deeper investigation into the origins of these preferences, as well as for mechanisms that provide users with transparency and control over the biases guiding LLM-powered agents.
A Deep Multi-Modal Method for Patient Wound Healing Assessment
Feb 10, 2026Hospitalization of patients is one of the major factors for high wound care costs. Most patients do not acquire a wound which needs immediate hospitalization. However, due to factors such as delay in treatment, patient's non-compliance or existing co-morbid conditions, an injury can deteriorate and ultimately lead to patient hospitalization. In this paper, we propose a deep multi-modal method to predict the patient's risk of hospitalization. Our goal is to predict the risk confidently by collectively using the wound variables and wound images of the patient. Existing works in this domain have mainly focused on healing trajectories based on distinct wound types. We developed a transfer learning-based wound assessment solution, which can predict both wound variables from wound images and their healing trajectories, which is our primary contribution. We argue that the development of a novel model can help in early detection of the complexities in the wound, which might affect the healing process and also reduce the time spent by a clinician to diagnose the wound.
* 4 pages, 2 figures
Linguistic properties and model scale in brain encoding: from small to compressed language models
Feb 07, 2026Recent work has shown that scaling large language models (LLMs) improves their alignment with human brain activity, yet it remains unclear what drives these gains and which representational properties are responsible. Although larger models often yield better task performance and brain alignment, they are increasingly difficult to analyze mechanistically. This raises a fundamental question: what is the minimal model capacity required to capture brain-relevant representations? To address this question, we systematically investigate how constraining model scale and numerical precision affects brain alignment. We compare full-precision LLMs, small language models (SLMs), and compressed variants (quantized and pruned) by predicting fMRI responses during naturalistic language comprehension. Across model families up to 14B parameters, we find that 3B SLMs achieve brain predictivity indistinguishable from larger LLMs, whereas 1B models degrade substantially, particularly in semantic language regions. Brain alignment is remarkably robust to compression: most quantization and pruning methods preserve neural predictivity, with GPTQ as a consistent exception. Linguistic probing reveals a dissociation between task performance and brain predictivity: compression degrades discourse, syntax, and morphology, yet brain predictivity remains largely unchanged. Overall, brain alignment saturates at modest model scales and is resilient to compression, challenging common assumptions about neural scaling and motivating compact models for brain-aligned language modeling.
How does longer temporal context enhance multimodal narrative video processing in the brain?
Feb 07, 2026Understanding how humans and artificial intelligence systems process complex narrative videos is a fundamental challenge at the intersection of neuroscience and machine learning. This study investigates how the temporal context length of video clips (3--12 s clips) and the narrative-task prompting shape brain-model alignment during naturalistic movie watching. Using fMRI recordings from participants viewing full-length movies, we examine how brain regions sensitive to narrative context dynamically represent information over varying timescales and how these neural patterns align with model-derived features. We find that increasing clip duration substantially improves brain alignment for multimodal large language models (MLLMs), whereas unimodal video models show little to no gain. Further, shorter temporal windows align with perceptual and early language regions, while longer windows preferentially align higher-order integrative regions, mirrored by a layer-to-cortex hierarchy in MLLMs. Finally, narrative-task prompts (multi-scene summary, narrative summary, character motivation, and event boundary detection) elicit task-specific, region-dependent brain alignment patterns and context-dependent shifts in clip-level tuning in higher-order regions. Together, our results position long-form narrative movies as a principled testbed for probing biologically relevant temporal integration and interpretable representations in long-context MLLMs.
Router-Suggest: Dynamic Routing for Multimodal Auto-Completion in Visually-Grounded Dialogs
Jan 09, 2026Real-time multimodal auto-completion is essential for digital assistants, chatbots, design tools, and healthcare consultations, where user inputs rely on shared visual context. We introduce Multimodal Auto-Completion (MAC), a task that predicts upcoming characters in live chats using partially typed text and visual cues. Unlike traditional text-only auto-completion (TAC), MAC grounds predictions in multimodal context to better capture user intent. To enable this task, we adapt MMDialog and ImageChat to create benchmark datasets. We evaluate leading vision-language models (VLMs) against strong textual baselines, highlighting trade-offs in accuracy and efficiency. We present Router-Suggest, a router framework that dynamically selects between textual models and VLMs based on dialog context, along with a lightweight variant for resource-constrained environments. Router-Suggest achieves a 2.3x to 10x speedup over the best-performing VLM. A user study shows that VLMs significantly excel over textual models on user satisfaction, notably saving user typing effort and improving the quality of completions in multi-turn conversations. These findings underscore the need for multimodal context in auto-completions, leading to smarter, user-aware assistants.
LoRA on the Go: Instance-level Dynamic LoRA Selection and Merging
Nov 10, 2025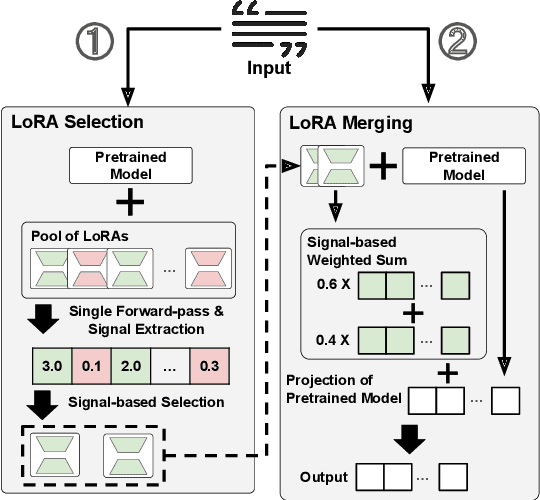
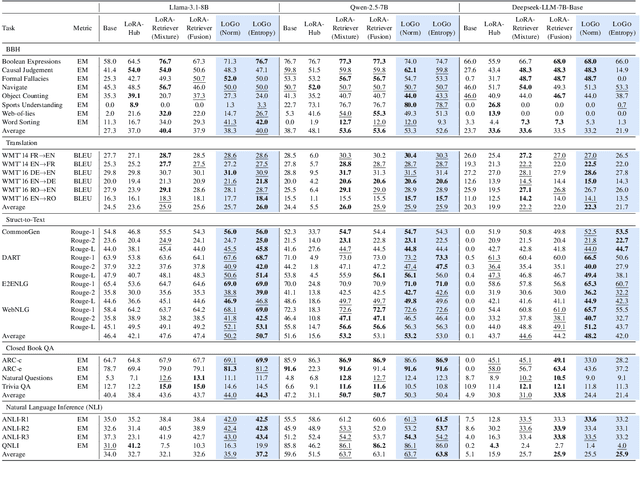
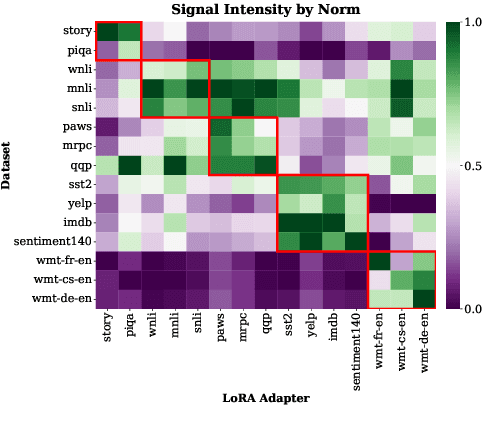
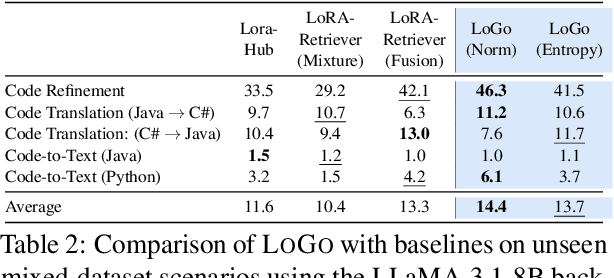
Low-Rank Adaptation (LoRA) has emerged as a parameter-efficient approach for fine-tuning large language models.However, conventional LoRA adapters are typically trained for a single task, limiting their applicability in real-world settings where inputs may span diverse and unpredictable domains. At inference time, existing approaches combine multiple LoRAs for improving performance on diverse tasks, while usually requiring labeled data or additional task-specific training, which is expensive at scale. In this work, we introduce LoRA on the Go (LoGo), a training-free framework that dynamically selects and merges adapters at the instance level without any additional requirements. LoGo leverages signals extracted from a single forward pass through LoRA adapters, to identify the most relevant adapters and determine their contributions on-the-fly. Across 5 NLP benchmarks, 27 datasets, and 3 model families, LoGo outperforms training-based baselines on some tasks upto a margin of 3.6% while remaining competitive on other tasks and maintaining inference throughput, highlighting its effectiveness and practicality.