 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Early Encoding to Late Suppression: Interpreting LLMs on Character Counting Tasks
Apr 01, 2026Large language models (LLMs) exhibit failures on elementary symbolic tasks such as character counting in a word, despite excelling on complex benchmarks. Although this limitation has been noted, the internal reasons remain unclear. We use character counting (e.g., "How many p's are in apple?") as a minimal, controlled probe that isolates token-level reasoning from higher-level confounds. Using this setting, we uncover a consistent phenomenon across modern architectures, including LLaMA, Qwen, and Gemma: models often compute the correct answer internally yet fail to express it at the output layer. Through mechanistic analysis combining probing classifiers, activation patching, logit lens analysis, and attention head tracing, we show that character-level information is encoded in early and mid-layer representations. However, this information is attenuated by a small set of components in later layers, especially the penultimate and final layer MLP. We identify these components as negative circuits: subnetworks that downweight correct signals in favor of higher-probability but incorrect outputs. Our results lead to two contributions. First, we show that symbolic reasoning failures in LLMs are not due to missing representations or insufficient scale, but arise from structured interference within the model's computation graph. This explains why such errors persist and can worsen under scaling and instruction tuning. Second, we provide evidence that LLM forward passes implement a form of competitive decoding, in which correct and incorrect hypotheses coexist and are dynamically reweighted, with final outputs determined by suppression as much as by amplification. These findings carry implications for interpretability and robustness: simple symbolic reasoning exposes weaknesses in modern LLMs, underscoring need for design strategies that ensure information is encoded and reliably used.
Multi-modal brain encoding models for multi-modal stimuli
May 26, 2025Despite participants engaging in unimodal stimuli, such as watching images or silent videos, recent work has demonstrated that multi-modal Transformer models can predict visual brain activity impressively well, even with incongruent modality representations. This raises the question of how accurately these multi-modal models can predict brain activity when participants are engaged in multi-modal stimuli. As these models grow increasingly popular, their use in studying neural activity provides insights into how our brains respond to such multi-modal naturalistic stimuli, i.e., where it separates and integrates information across modalities through a hierarchy of early sensory regions to higher cognition. We investigate this question by using multiple unimodal and two types of multi-modal models-cross-modal and jointly pretrained-to determine which type of model is more relevant to fMRI brain activity when participants are engaged in watching movies. We observe that both types of multi-modal models show improved alignment in several language and visual regions. This study also helps in identifying which brain regions process unimodal versus multi-modal information. We further investigate the contribution of each modality to multi-modal alignment by carefully removing unimodal features one by one from multi-modal representations, and find that there is additional information beyond the unimodal embeddings that is processed in the visual and language regions. Based on this investigation, we find that while for cross-modal models, their brain alignment is partially attributed to the video modality; for jointly pretrained models, it is partially attributed to both the video and audio modalities. This serves as a strong motivation for the neuroscience community to investigate the interpretability of these models for deepening our understanding of multi-modal information processing in brain.
* 26 pages, 15 figures, The Thirteenth International Conference on Learning Representations, ICLR-2025, Singapore. https://openreview.net/pdf?id=0dELcFHig2
IndicSentEval: How Effectively do Multilingual Transformer Models encode Linguistic Properties for Indic Languages?
Oct 03, 2024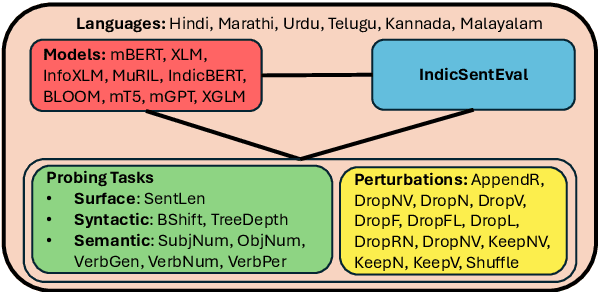
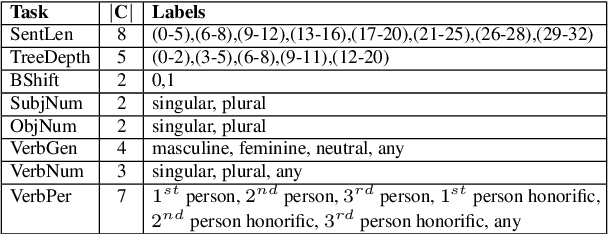
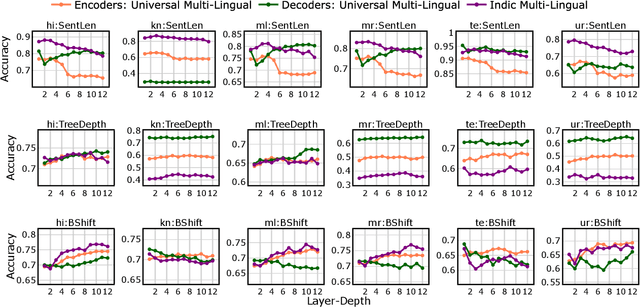
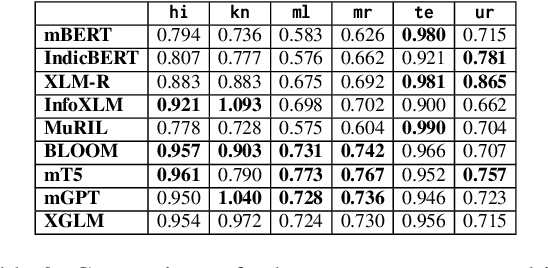
Transformer-based models have revolutionized the field of natural language processing. To understand why they perform so well and to assess their reliability, several studies have focused on questions such as: Which linguistic properties are encoded by these models, and to what extent? How robust are these models in encoding linguistic properties when faced with perturbations in the input text? However, these studies have mainly focused on BERT and the English language. In this paper, we investigate similar questions regarding encoding capability and robustness for 8 linguistic properties across 13 different perturbations in 6 Indic languages, using 9 multilingual Transformer models (7 universal and 2 Indic-specific). To conduct this study, we introduce a novel multilingual benchmark dataset, IndicSentEval, containing approximately $\sim$47K sentences. Surprisingly, our probing analysis of surface, syntactic, and semantic properties reveals that while almost all multilingual models demonstrate consistent encoding performance for English, they show mixed results for Indic languages. As expected, Indic-specific multilingual models capture linguistic properties in Indic languages better than universal models. Intriguingly, universal models broadly exhibit better robustness compared to Indic-specific models, particularly under perturbations such as dropping both nouns and verbs, dropping only verbs, or keeping only nouns. Overall, this study provides valuable insights into probing and perturbation-specific strengths and weaknesses of popular multilingual Transformer-based models for different Indic languages. We make our code and dataset publicly available [https://tinyurl.com/IndicSentEval}].
USDC: A Dataset of $\underline{U}$ser $\underline{S}$tance and $\underline{D}$ogmatism in Long $\underline{C}$onversations
Jun 24, 2024Identifying user's opinions and stances in long conversation threads on various topics can be extremely critical for enhanced personalization, market research, political campaigns, customer service, conflict resolution, targeted advertising, and content moderation. Hence, training language models to automate this task is critical. However, to train such models, gathering manual annotations has multiple challenges: 1) It is time-consuming and costly; 2) Conversation threads could be very long, increasing chances of noisy annotations; and 3) Interpreting instances where a user changes their opinion within a conversation is difficult because often such transitions are subtle and not expressed explicitly. Inspired by the recent success of large language models (LLMs) for complex natural language processing (NLP) tasks, we leverage Mistral Large and GPT-4 to automate the human annotation process on the following two tasks while also providing reasoning: i) User Stance classification, which involves labeling a user's stance of a post in a conversation on a five-point scale; ii) User Dogmatism classification, which deals with labeling a user's overall opinion in the conversation on a four-point scale. The majority voting on zero-shot, one-shot, and few-shot annotations from these two LLMs on 764 multi-user Reddit conversations helps us curate the USDC dataset. USDC is then used to finetune and instruction-tune multiple deployable small language models for the 5-class stance and 4-class dogmatism classification tasks. We make the code and dataset publicly available [https://anonymous.4open.science/r/USDC-0F7F].
On Robustness of Finetuned Transformer-based NLP Models
May 23, 2023



Transformer-based pretrained models like BERT, GPT-2 and T5 have been finetuned for a large number of natural language processing (NLP) tasks, and have been shown to be very effective. However, while finetuning, what changes across layers in these models with respect to pretrained checkpoints is under-studied. Further, how robust are these models to perturbations in input text? Does the robustness vary depending on the NLP task for which the models have been finetuned? While there exists some work on studying robustness of BERT finetuned for a few NLP tasks, there is no rigorous study which compares this robustness across encoder only, decoder only and encoder-decoder models. In this paper, we study the robustness of three language models (BERT, GPT-2 and T5) with eight different text perturbations on the General Language Understanding Evaluation (GLUE) benchmark. Also, we use two metrics (CKA and STIR) to quantify changes between pretrained and finetuned language model representations across layers. GPT-2 representations are more robust than BERT and T5 across multiple types of input perturbation. Although models exhibit good robustness broadly, dropping nouns, verbs or changing characters are the most impactful. Overall, this study provides valuable insights into perturbation-specific weaknesses of popular Transformer-based models which should be kept in mind when passing inputs.
Syntactic Structure Processing in the Brain while Listening
Feb 16, 2023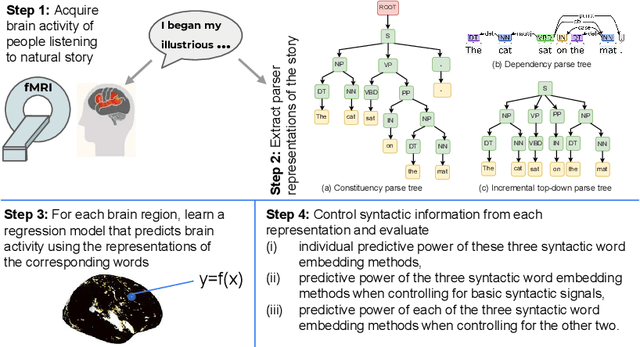
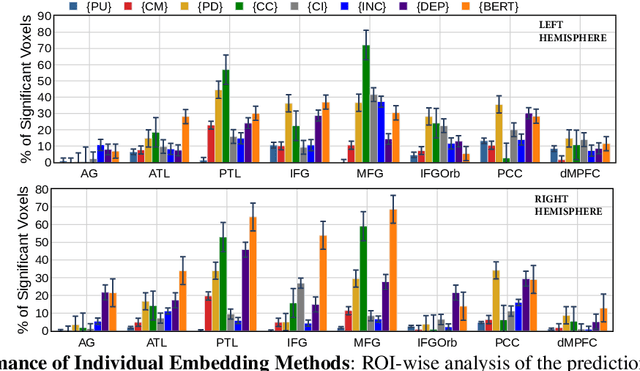
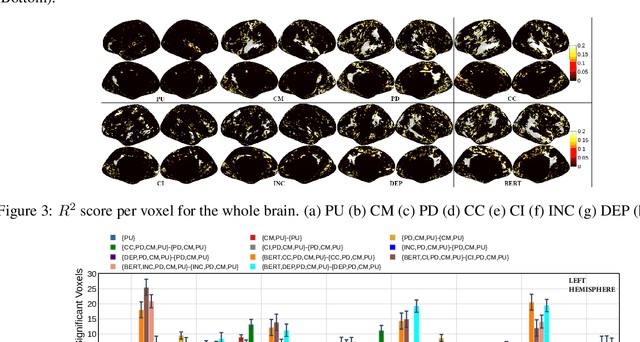
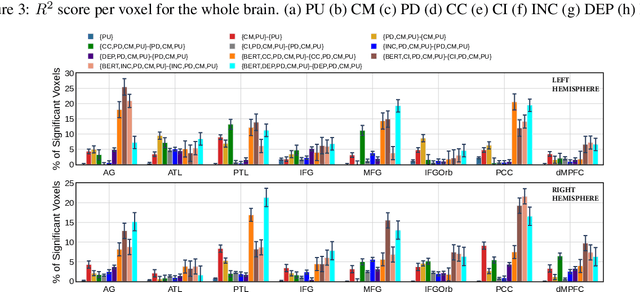
Syntactic parsing is the task of assigning a syntactic structure to a sentence. There are two popular syntactic parsing methods: constituency and dependency parsing. Recent works have used syntactic embeddings based on constituency trees, incremental top-down parsing, and other word syntactic features for brain activity prediction given the text stimuli to study how the syntax structure is represented in the brain's language network. However, the effectiveness of dependency parse trees or the relative predictive power of the various syntax parsers across brain areas, especially for the listening task, is yet unexplored. In this study, we investigate the predictive power of the brain encoding models in three settings: (i) individual performance of the constituency and dependency syntactic parsing based embedding methods, (ii) efficacy of these syntactic parsing based embedding methods when controlling for basic syntactic signals, (iii) relative effectiveness of each of the syntactic embedding methods when controlling for the other. Further, we explore the relative importance of syntactic information (from these syntactic embedding methods) versus semantic information using BERT embeddings. We find that constituency parsers help explain activations in the temporal lobe and middle-frontal gyrus, while dependency parsers better encode syntactic structure in the angular gyrus and posterior cingulate cortex. Although semantic signals from BERT are more effective compared to any of the syntactic features or embedding methods, syntactic embedding methods explain additional variance for a few brain regions.
GAE-ISumm: Unsupervised Graph-Based Summarization of Indian Languages
Dec 25, 2022Document summarization aims to create a precise and coherent summary of a text document. Many deep learning summarization models are developed mainly for English, often requiring a large training corpus and efficient pre-trained language models and tools. However, English summarization models for low-resource Indian languages are often limited by rich morphological variation, syntax, and semantic differences. In this paper, we propose GAE-ISumm, an unsupervised Indic summarization model that extracts summaries from text documents. In particular, our proposed model, GAE-ISumm uses Graph Autoencoder (GAE) to learn text representations and a document summary jointly. We also provide a manually-annotated Telugu summarization dataset TELSUM, to experiment with our model GAE-ISumm. Further, we experiment with the most publicly available Indian language summarization datasets to investigate the effectiveness of GAE-ISumm on other Indian languages. Our experiments of GAE-ISumm in seven languages make the following observations: (i) it is competitive or better than state-of-the-art results on all datasets, (ii) it reports benchmark results on TELSUM, and (iii) the inclusion of positional and cluster information in the proposed model improved the performance of summaries.
Neural Language Taskonomy: Which NLP Tasks are the most Predictive of fMRI Brain Activity?
May 03, 2022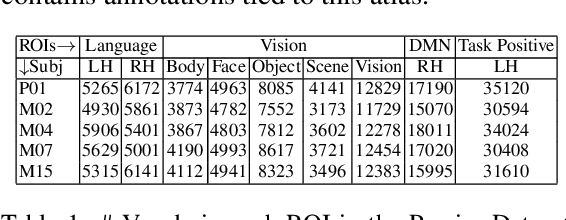
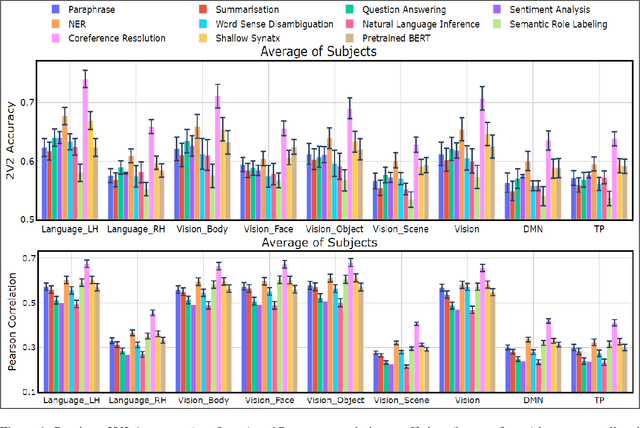
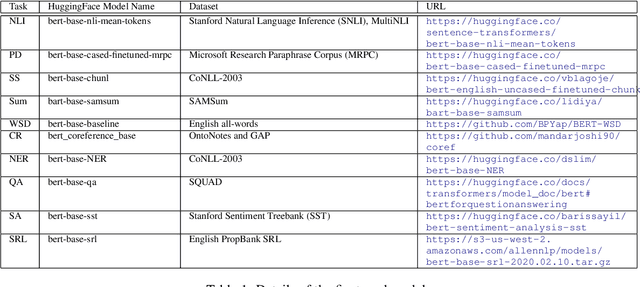
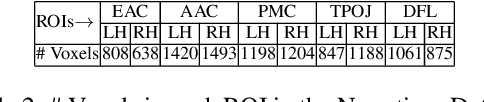
Several popular Transformer based language models have been found to be successful for text-driven brain encoding. However, existing literature leverages only pretrained text Transformer models and has not explored the efficacy of task-specific learned Transformer representations. In this work, we explore transfer learning from representations learned for ten popular natural language processing tasks (two syntactic and eight semantic) for predicting brain responses from two diverse datasets: Pereira (subjects reading sentences from paragraphs) and Narratives (subjects listening to the spoken stories). Encoding models based on task features are used to predict activity in different regions across the whole brain. Features from coreference resolution, NER, and shallow syntax parsing explain greater variance for the reading activity. On the other hand, for the listening activity, tasks such as paraphrase generation, summarization, and natural language inference show better encoding performance. Experiments across all 10 task representations provide the following cognitive insights: (i) language left hemisphere has higher predictive brain activity versus language right hemisphere, (ii) posterior medial cortex, temporo-parieto-occipital junction, dorsal frontal lobe have higher correlation versus early auditory and auditory association cortex, (iii) syntactic and semantic tasks display a good predictive performance across brain regions for reading and listening stimuli resp.
Multi-Task Text Classification using Graph Convolutional Networks for Large-Scale Low Resource Language
May 02, 2022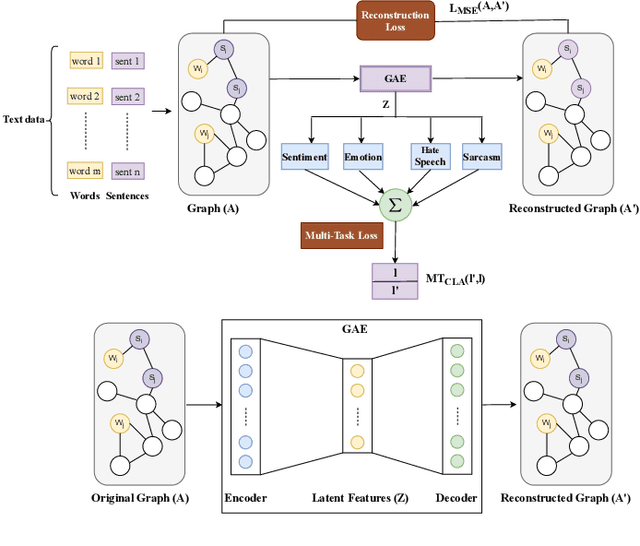

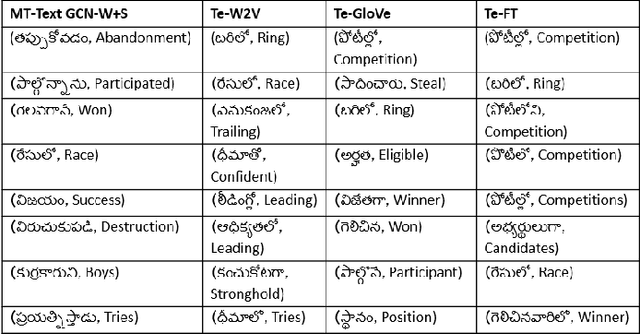
Graph Convolutional Networks (GCN) have achieved state-of-art results on single text classification tasks like sentiment analysis, emotion detection, etc. However, the performance is achieved by testing and reporting on resource-rich languages like English. Applying GCN for multi-task text classification is an unexplored area. Moreover, training a GCN or adopting an English GCN for Indian languages is often limited by data availability, rich morphological variation, syntax, and semantic differences. In this paper, we study the use of GCN for the Telugu language in single and multi-task settings for four natural language processing (NLP) tasks, viz. sentiment analysis (SA), emotion identification (EI), hate-speech (HS), and sarcasm detection (SAR). In order to evaluate the performance of GCN with one of the Indian languages, Telugu, we analyze the GCN based models with extensive experiments on four downstream tasks. In addition, we created an annotated Telugu dataset, TEL-NLP, for the four NLP tasks. Further, we propose a supervised graph reconstruction method, Multi-Task Text GCN (MT-Text GCN) on the Telugu that leverages to simultaneously (i) learn the low-dimensional word and sentence graph embeddings from word-sentence graph reconstruction using graph autoencoder (GAE) and (ii) perform multi-task text classification using these latent sentence graph embeddings. We argue that our proposed MT-Text GCN achieves significant improvements on TEL-NLP over existing Telugu pretrained word embeddings, and multilingual pretrained Transformer models: mBERT, and XLM-R. On TEL-NLP, we achieve a high F1-score for four NLP tasks: SA (0.84), EI (0.55), HS (0.83) and SAR (0.66). Finally, we show our model's quantitative and qualitative analysis on the four NLP tasks in Telugu.
Affect in Tweets Using Experts Model
Mar 20, 2019
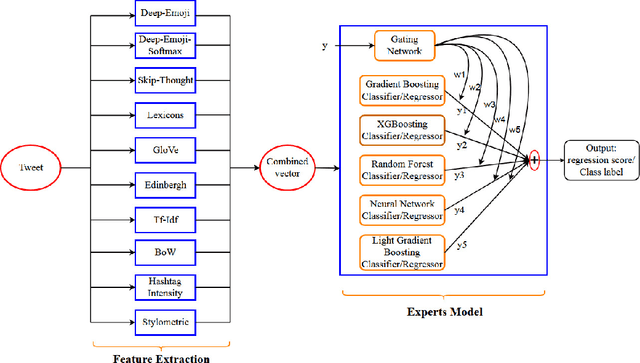
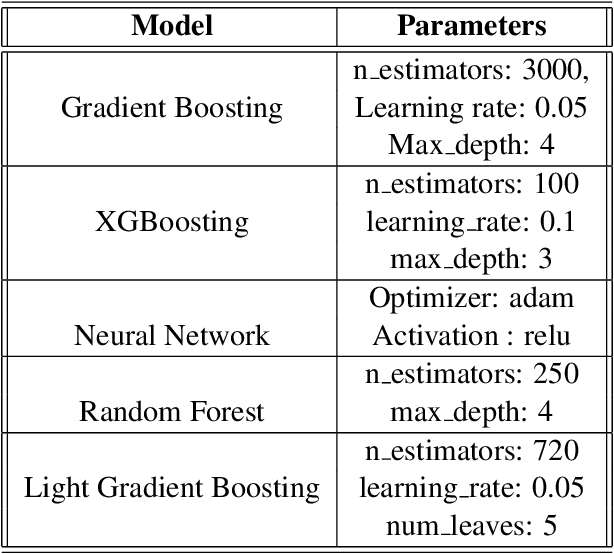
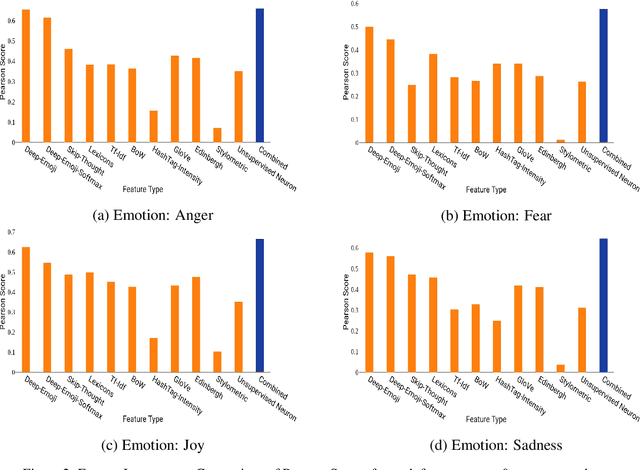
Estimating the intensity of emotion has gained significance as modern textual inputs in potential applications like social media, e-retail markets, psychology, advertisements etc., carry a lot of emotions, feelings, expressions along with its meaning. However, the approaches of traditional sentiment analysis primarily focuses on classifying the sentiment in general (positive or negative) or at an aspect level(very positive, low negative, etc.) and cannot exploit the intensity information. Moreover, automatically identifying emotions like anger, fear, joy, sadness, disgust etc., from text introduces challenging scenarios where single tweet may contain multiple emotions with different intensities and some emotions may even co-occur in some of the tweets. In this paper, we propose an architecture, Experts Model, inspired from the standard Mixture of Experts (MoE) model. The key idea here is each expert learns different sets of features from the feature vector which helps in better emotion detection from the tweet. We compared the results of our Experts Model with both baseline results and top five performers of SemEval-2018 Task-1, Affect in Tweets (AIT). The experimental results show that our proposed approach deals with the emotion detection problem and stands at top-5 results.