 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Group Recommender System
Jul 22, 2023
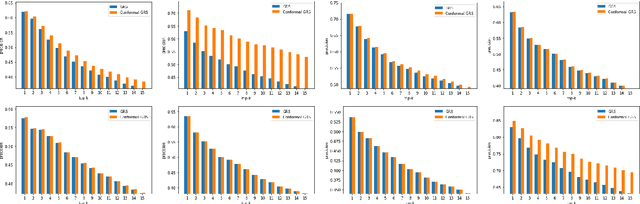
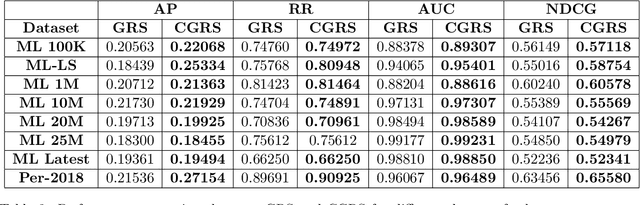
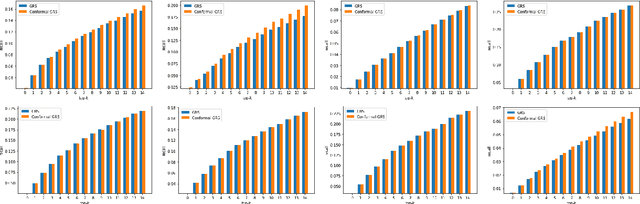
Group recommender systems (GRS) are critical in discovering relevant items from a near-infinite inventory based on group preferences rather than individual preferences, like recommending a movie, restaurant, or tourist destination to a group of individuals. The traditional models of group recommendation are designed to act like a black box with a strict focus on improving recommendation accuracy, and most often, they place the onus on the users to interpret recommendations. In recent years, the focus of Recommender Systems (RS) research has shifted away from merely improving recommendation accuracy towards value additions such as confidence and explanation. In this work, we propose a conformal prediction framework that provides a measure of confidence with prediction in conjunction with a group recommender system to augment the system-generated plain recommendations. In the context of group recommender systems, we propose various nonconformity measures that play a vital role in the efficiency of the conformal framework. We also show that defined nonconformity satisfies the exchangeability property. Experimental results demonstrate the effectiveness of the proposed approach over several benchmark datasets. Furthermore, our proposed approach also satisfies validity and efficiency properties.
On Robustness of Finetuned Transformer-based NLP Models
May 23, 2023



Transformer-based pretrained models like BERT, GPT-2 and T5 have been finetuned for a large number of natural language processing (NLP) tasks, and have been shown to be very effective. However, while finetuning, what changes across layers in these models with respect to pretrained checkpoints is under-studied. Further, how robust are these models to perturbations in input text? Does the robustness vary depending on the NLP task for which the models have been finetuned? While there exists some work on studying robustness of BERT finetuned for a few NLP tasks, there is no rigorous study which compares this robustness across encoder only, decoder only and encoder-decoder models. In this paper, we study the robustness of three language models (BERT, GPT-2 and T5) with eight different text perturbations on the General Language Understanding Evaluation (GLUE) benchmark. Also, we use two metrics (CKA and STIR) to quantify changes between pretrained and finetuned language model representations across layers. GPT-2 representations are more robust than BERT and T5 across multiple types of input perturbation. Although models exhibit good robustness broadly, dropping nouns, verbs or changing characters are the most impactful. Overall, this study provides valuable insights into perturbation-specific weaknesses of popular Transformer-based models which should be kept in mind when passing inputs.