 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Multi-Modal Method for Patient Wound Healing Assessment
Feb 10, 2026Hospitalization of patients is one of the major factors for high wound care costs. Most patients do not acquire a wound which needs immediate hospitalization. However, due to factors such as delay in treatment, patient's non-compliance or existing co-morbid conditions, an injury can deteriorate and ultimately lead to patient hospitalization. In this paper, we propose a deep multi-modal method to predict the patient's risk of hospitalization. Our goal is to predict the risk confidently by collectively using the wound variables and wound images of the patient. Existing works in this domain have mainly focused on healing trajectories based on distinct wound types. We developed a transfer learning-based wound assessment solution, which can predict both wound variables from wound images and their healing trajectories, which is our primary contribution. We argue that the development of a novel model can help in early detection of the complexities in the wound, which might affect the healing process and also reduce the time spent by a clinician to diagnose the wound.
* 4 pages, 2 figures
Linguistic properties and model scale in brain encoding: from small to compressed language models
Feb 07, 2026Recent work has shown that scaling large language models (LLMs) improves their alignment with human brain activity, yet it remains unclear what drives these gains and which representational properties are responsible. Although larger models often yield better task performance and brain alignment, they are increasingly difficult to analyze mechanistically. This raises a fundamental question: what is the minimal model capacity required to capture brain-relevant representations? To address this question, we systematically investigate how constraining model scale and numerical precision affects brain alignment. We compare full-precision LLMs, small language models (SLMs), and compressed variants (quantized and pruned) by predicting fMRI responses during naturalistic language comprehension. Across model families up to 14B parameters, we find that 3B SLMs achieve brain predictivity indistinguishable from larger LLMs, whereas 1B models degrade substantially, particularly in semantic language regions. Brain alignment is remarkably robust to compression: most quantization and pruning methods preserve neural predictivity, with GPTQ as a consistent exception. Linguistic probing reveals a dissociation between task performance and brain predictivity: compression degrades discourse, syntax, and morphology, yet brain predictivity remains largely unchanged. Overall, brain alignment saturates at modest model scales and is resilient to compression, challenging common assumptions about neural scaling and motivating compact models for brain-aligned language modeling.
How does longer temporal context enhance multimodal narrative video processing in the brain?
Feb 07, 2026Understanding how humans and artificial intelligence systems process complex narrative videos is a fundamental challenge at the intersection of neuroscience and machine learning. This study investigates how the temporal context length of video clips (3--12 s clips) and the narrative-task prompting shape brain-model alignment during naturalistic movie watching. Using fMRI recordings from participants viewing full-length movies, we examine how brain regions sensitive to narrative context dynamically represent information over varying timescales and how these neural patterns align with model-derived features. We find that increasing clip duration substantially improves brain alignment for multimodal large language models (MLLMs), whereas unimodal video models show little to no gain. Further, shorter temporal windows align with perceptual and early language regions, while longer windows preferentially align higher-order integrative regions, mirrored by a layer-to-cortex hierarchy in MLLMs. Finally, narrative-task prompts (multi-scene summary, narrative summary, character motivation, and event boundary detection) elicit task-specific, region-dependent brain alignment patterns and context-dependent shifts in clip-level tuning in higher-order regions. Together, our results position long-form narrative movies as a principled testbed for probing biologically relevant temporal integration and interpretable representations in long-context MLLMs.
Instruction-Tuned Video-Audio Models Elucidate Functional Specialization in the Brain
Jun 09, 2025Recent voxel-wise multimodal brain encoding studies have shown that multimodal large language models (MLLMs) exhibit a higher degree of brain alignment compared to unimodal models in both unimodal and multimodal stimulus settings. More recently, instruction-tuned multimodal models have shown to generate task-specific representations that align strongly with brain activity. However, prior work evaluating the brain alignment of MLLMs has primarily focused on unimodal settings or relied on non-instruction-tuned multimodal models for multimodal stimuli. To address this gap, we investigated brain alignment, that is, measuring the degree of predictivity of neural activity recorded while participants were watching naturalistic movies (video along with audio) with representations derived from MLLMs. We utilized instruction-specific embeddings from six video and two audio instruction-tuned MLLMs. Experiments with 13 video task-specific instructions show that instruction-tuned video MLLMs significantly outperform non-instruction-tuned multimodal (by 15%) and unimodal models (by 20%). Our evaluation of MLLMs for both video and audio tasks using language-guided instructions shows clear disentanglement in task-specific representations from MLLMs, leading to precise differentiation of multimodal functional processing in the brain. We also find that MLLM layers align hierarchically with the brain, with early sensory areas showing strong alignment with early layers, while higher-level visual and language regions align more with middle to late layers. These findings provide clear evidence for the role of task-specific instructions in improving the alignment between brain activity and MLLMs, and open new avenues for mapping joint information processing in both the systems. We make the code publicly available [https://github.com/subbareddy248/mllm_videos].
Multi-modal brain encoding models for multi-modal stimuli
May 26, 2025Despite participants engaging in unimodal stimuli, such as watching images or silent videos, recent work has demonstrated that multi-modal Transformer models can predict visual brain activity impressively well, even with incongruent modality representations. This raises the question of how accurately these multi-modal models can predict brain activity when participants are engaged in multi-modal stimuli. As these models grow increasingly popular, their use in studying neural activity provides insights into how our brains respond to such multi-modal naturalistic stimuli, i.e., where it separates and integrates information across modalities through a hierarchy of early sensory regions to higher cognition. We investigate this question by using multiple unimodal and two types of multi-modal models-cross-modal and jointly pretrained-to determine which type of model is more relevant to fMRI brain activity when participants are engaged in watching movies. We observe that both types of multi-modal models show improved alignment in several language and visual regions. This study also helps in identifying which brain regions process unimodal versus multi-modal information. We further investigate the contribution of each modality to multi-modal alignment by carefully removing unimodal features one by one from multi-modal representations, and find that there is additional information beyond the unimodal embeddings that is processed in the visual and language regions. Based on this investigation, we find that while for cross-modal models, their brain alignment is partially attributed to the video modality; for jointly pretrained models, it is partially attributed to both the video and audio modalities. This serves as a strong motivation for the neuroscience community to investigate the interpretability of these models for deepening our understanding of multi-modal information processing in brain.
* 26 pages, 15 figures, The Thirteenth International Conference on Learning Representations, ICLR-2025, Singapore. https://openreview.net/pdf?id=0dELcFHig2
Correlating instruction-tuning (in multimodal models) with vision-language processing (in the brain)
May 26, 2025Transformer-based language models, though not explicitly trained to mimic brain recordings, have demonstrated surprising alignment with brain activity. Progress in these models-through increased size, instruction-tuning, and multimodality-has led to better representational alignment with neural data. Recently, a new class of instruction-tuned multimodal LLMs (MLLMs) have emerged, showing remarkable zero-shot capabilities in open-ended multimodal vision tasks. However, it is unknown whether MLLMs, when prompted with natural instructions, lead to better brain alignment and effectively capture instruction-specific representations. To address this, we first investigate brain alignment, i.e., measuring the degree of predictivity of neural visual activity using text output response embeddings from MLLMs as participants engage in watching natural scenes. Experiments with 10 different instructions show that MLLMs exhibit significantly better brain alignment than vision-only models and perform comparably to non-instruction-tuned multimodal models like CLIP. We also find that while these MLLMs are effective at generating high-quality responses suitable to the task-specific instructions, not all instructions are relevant for brain alignment. Further, by varying instructions, we make the MLLMs encode instruction-specific visual concepts related to the input image. This analysis shows that MLLMs effectively capture count-related and recognition-related concepts, demonstrating strong alignment with brain activity. Notably, the majority of the explained variance of the brain encoding models is shared between MLLM embeddings of image captioning and other instructions. These results suggest that enhancing MLLMs' ability to capture task-specific information could lead to better differentiation between various types of instructions, and thereby improving their precision in predicting brain responses.
* 30 pages, 22 figures, The Thirteenth International Conference on Learning Representations, ICLR-2025, Singapore. https://openreview.net/pdf?id=xkgfLXZ4e0
IndicSentEval: How Effectively do Multilingual Transformer Models encode Linguistic Properties for Indic Languages?
Oct 03, 2024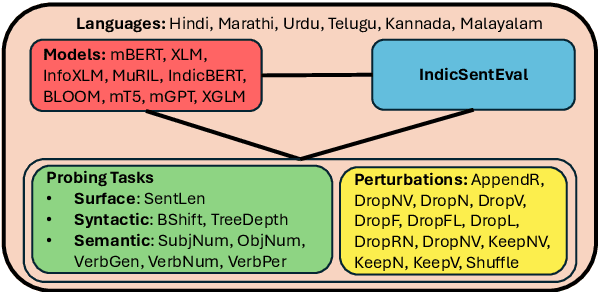
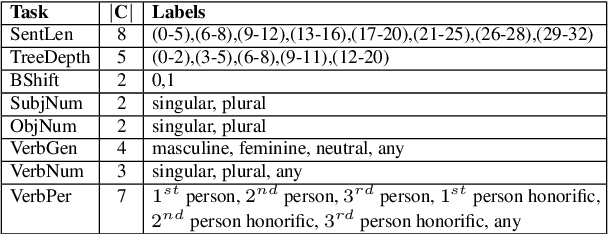
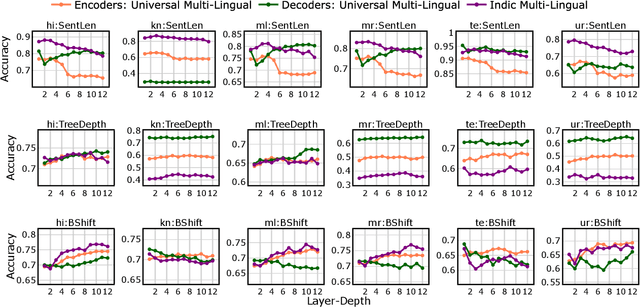
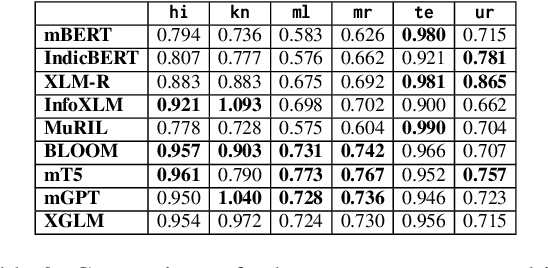
Transformer-based models have revolutionized the field of natural language processing. To understand why they perform so well and to assess their reliability, several studies have focused on questions such as: Which linguistic properties are encoded by these models, and to what extent? How robust are these models in encoding linguistic properties when faced with perturbations in the input text? However, these studies have mainly focused on BERT and the English language. In this paper, we investigate similar questions regarding encoding capability and robustness for 8 linguistic properties across 13 different perturbations in 6 Indic languages, using 9 multilingual Transformer models (7 universal and 2 Indic-specific). To conduct this study, we introduce a novel multilingual benchmark dataset, IndicSentEval, containing approximately $\sim$47K sentences. Surprisingly, our probing analysis of surface, syntactic, and semantic properties reveals that while almost all multilingual models demonstrate consistent encoding performance for English, they show mixed results for Indic languages. As expected, Indic-specific multilingual models capture linguistic properties in Indic languages better than universal models. Intriguingly, universal models broadly exhibit better robustness compared to Indic-specific models, particularly under perturbations such as dropping both nouns and verbs, dropping only verbs, or keeping only nouns. Overall, this study provides valuable insights into probing and perturbation-specific strengths and weaknesses of popular multilingual Transformer-based models for different Indic languages. We make our code and dataset publicly available [https://tinyurl.com/IndicSentEval}].
USDC: A Dataset of $\underline{U}$ser $\underline{S}$tance and $\underline{D}$ogmatism in Long $\underline{C}$onversations
Jun 24, 2024Identifying user's opinions and stances in long conversation threads on various topics can be extremely critical for enhanced personalization, market research, political campaigns, customer service, conflict resolution, targeted advertising, and content moderation. Hence, training language models to automate this task is critical. However, to train such models, gathering manual annotations has multiple challenges: 1) It is time-consuming and costly; 2) Conversation threads could be very long, increasing chances of noisy annotations; and 3) Interpreting instances where a user changes their opinion within a conversation is difficult because often such transitions are subtle and not expressed explicitly. Inspired by the recent success of large language models (LLMs) for complex natural language processing (NLP) tasks, we leverage Mistral Large and GPT-4 to automate the human annotation process on the following two tasks while also providing reasoning: i) User Stance classification, which involves labeling a user's stance of a post in a conversation on a five-point scale; ii) User Dogmatism classification, which deals with labeling a user's overall opinion in the conversation on a four-point scale. The majority voting on zero-shot, one-shot, and few-shot annotations from these two LLMs on 764 multi-user Reddit conversations helps us curate the USDC dataset. USDC is then used to finetune and instruction-tune multiple deployable small language models for the 5-class stance and 4-class dogmatism classification tasks. We make the code and dataset publicly available [https://anonymous.4open.science/r/USDC-0F7F].
Speech language models lack important brain-relevant semantics
Nov 08, 2023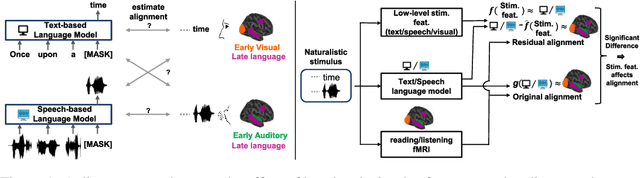

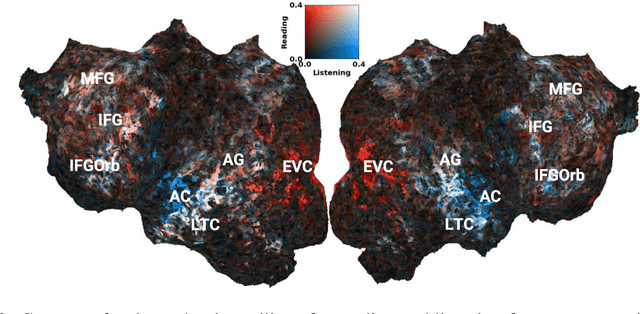
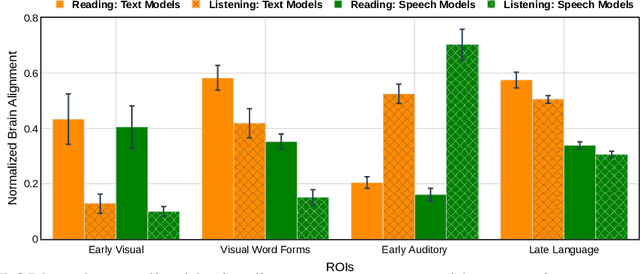
Despite known differences between reading and listening in the brain, recent work has shown that text-based language models predict both text-evoked and speech-evoked brain activity to an impressive degree. This poses the question of what types of information language models truly predict in the brain. We investigate this question via a direct approach, in which we eliminate information related to specific low-level stimulus features (textual, speech, and visual) in the language model representations, and observe how this intervention affects the alignment with fMRI brain recordings acquired while participants read versus listened to the same naturalistic stories. We further contrast our findings with speech-based language models, which would be expected to predict speech-evoked brain activity better, provided they model language processing in the brain well. Using our direct approach, we find that both text-based and speech-based language models align well with early sensory regions due to shared low-level features. Text-based models continue to align well with later language regions even after removing these features, while, surprisingly, speech-based models lose most of their alignment. These findings suggest that speech-based models can be further improved to better reflect brain-like language processing.
Deep Neural Networks and Brain Alignment: Brain Encoding and Decoding (Survey)
Jul 17, 2023



How does the brain represent different modes of information? Can we design a system that automatically understands what the user is thinking? Such questions can be answered by studying brain recordings like functional magnetic resonance imaging (fMRI). As a first step, the neuroscience community has contributed several large cognitive neuroscience datasets related to passive reading/listening/viewing of concept words, narratives, pictures and movies. Encoding and decoding models using these datasets have also been proposed in the past two decades. These models serve as additional tools for basic research in cognitive science and neuroscience. Encoding models aim at generating fMRI brain representations given a stimulus automatically. They have several practical applications in evaluating and diagnosing neurological conditions and thus also help design therapies for brain damage. Decoding models solve the inverse problem of reconstructing the stimuli given the fMRI. They are useful for designing brain-machine or brain-computer interfaces. Inspired by the effectiveness of deep learning models for natural language processing, computer vision, and speech, recently several neural encoding and decoding models have been proposed. In this survey, we will first discuss popular representations of language, vision and speech stimuli, and present a summary of neuroscience datasets. Further, we will review popular deep learning based encoding and decoding architectures and note their benefits and limitations. Finally, we will conclude with a brief summary and discussion about future trends. Given the large amount of recently published work in the `computational cognitive neuroscience' community, we believe that this survey nicely organizes the plethora of work and presents it as a coherent story.