 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Reservoir: A Diagonalization-Based Optimization
Feb 23, 2026We introduce a diagonalization-based optimization for Linear Echo State Networks (ESNs) that reduces the per-step computational complexity of reservoir state updates from O(N^2) to O(N). By reformulating reservoir dynamics in the eigenbasis of the recurrent matrix, the recurrent update becomes a set of independent element-wise operations, eliminating the matrix multiplication. We further propose three methods to use our optimization depending on the situation: (i) Eigenbasis Weight Transformation (EWT), which preserves the dynamics of standard and trained Linear ESNs, (ii) End-to-End Eigenbasis Training (EET), which directly optimizes readout weights in the transformed space and (iii) Direct Parameter Generation (DPG), that bypasses matrix diagonalization by directly sampling eigenvalues and eigenvectors, achieving comparable performance than standard Linear ESNs. Across all experiments, both our methods preserve predictive accuracy while offering significant computational speedups, making them a replacement of standard Linear ESNs computations and training, and suggesting a shift of paradigm in linear ESN towards the direct selection of eigenvalues.
Less is More: some Computational Principles based on Parcimony, and Limitations of Natural Intelligence
Jun 08, 2025Natural intelligence (NI) consistently achieves more with less. Infants learn language, develop abstract concepts, and acquire sensorimotor skills from sparse data, all within tight neural and energy limits. In contrast, today's AI relies on virtually unlimited computational power, energy, and data to reach high performance. This paper argues that constraints in NI are paradoxically catalysts for efficiency, adaptability, and creativity. We first show how limited neural bandwidth promotes concise codes that still capture complex patterns. Spiking neurons, hierarchical structures, and symbolic-like representations emerge naturally from bandwidth constraints, enabling robust generalization. Next, we discuss chaotic itinerancy, illustrating how the brain transits among transient attractors to flexibly retrieve memories and manage uncertainty. We then highlight reservoir computing, where random projections facilitate rapid generalization from small datasets. Drawing on developmental perspectives, we emphasize how intrinsic motivation, along with responsive social environments, drives infant language learning and discovery of meaning. Such active, embodied processes are largely absent in current AI. Finally, we suggest that adopting 'less is more' principles -- energy constraints, parsimonious architectures, and real-world interaction -- can foster the emergence of more efficient, interpretable, and biologically grounded artificial systems.
Evolving Reservoirs for Meta Reinforcement Learning
Dec 09, 2023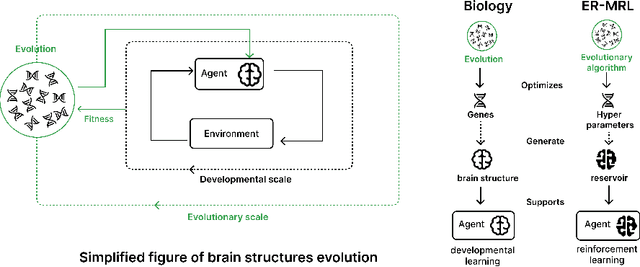
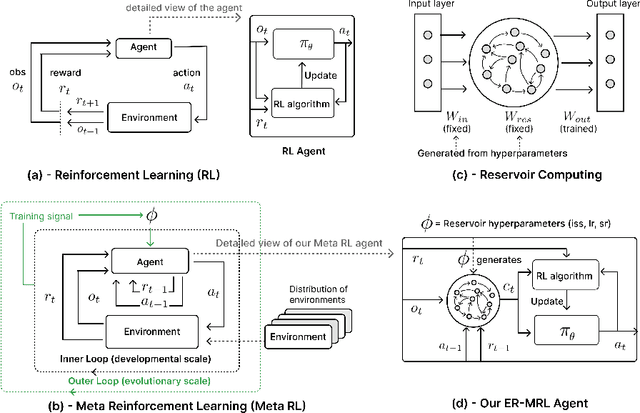
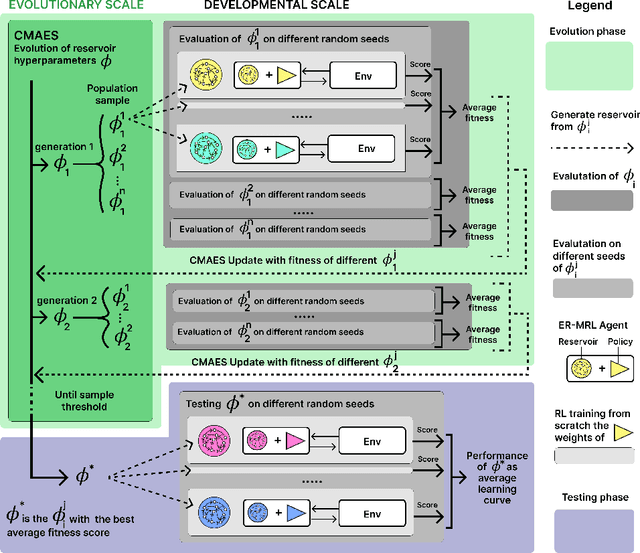
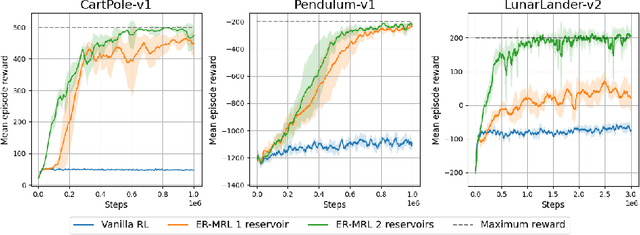
Animals often demonstrate a remarkable ability to adapt to their environments during their lifetime. They do so partly due to the evolution of morphological and neural structures. These structures capture features of environments shared between generations to bias and speed up lifetime learning. In this work, we propose a computational model for studying a mechanism that can enable such a process. We adopt a computational framework based on meta reinforcement learning as a model of the interplay between evolution and development. At the evolutionary scale, we evolve reservoirs, a family of recurrent neural networks that differ from conventional networks in that one optimizes not the weight values but hyperparameters of the architecture: the later control macro-level properties, such as memory and dynamics. At the developmental scale, we employ these evolved reservoirs to facilitate the learning of a behavioral policy through Reinforcement Learning (RL). Within an RL agent, a reservoir encodes the environment state before providing it to an action policy. We evaluate our approach on several 2D and 3D simulated environments. Our results show that the evolution of reservoirs can improve the learning of diverse challenging tasks. We study in particular three hypotheses: the use of an architecture combining reservoirs and reinforcement learning could enable (1) solving tasks with partial observability, (2) generating oscillatory dynamics that facilitate the learning of locomotion tasks, and (3) facilitating the generalization of learned behaviors to new tasks unknown during the evolution phase.
Deep Neural Networks and Brain Alignment: Brain Encoding and Decoding (Survey)
Jul 17, 2023



How does the brain represent different modes of information? Can we design a system that automatically understands what the user is thinking? Such questions can be answered by studying brain recordings like functional magnetic resonance imaging (fMRI). As a first step, the neuroscience community has contributed several large cognitive neuroscience datasets related to passive reading/listening/viewing of concept words, narratives, pictures and movies. Encoding and decoding models using these datasets have also been proposed in the past two decades. These models serve as additional tools for basic research in cognitive science and neuroscience. Encoding models aim at generating fMRI brain representations given a stimulus automatically. They have several practical applications in evaluating and diagnosing neurological conditions and thus also help design therapies for brain damage. Decoding models solve the inverse problem of reconstructing the stimuli given the fMRI. They are useful for designing brain-machine or brain-computer interfaces. Inspired by the effectiveness of deep learning models for natural language processing, computer vision, and speech, recently several neural encoding and decoding models have been proposed. In this survey, we will first discuss popular representations of language, vision and speech stimuli, and present a summary of neuroscience datasets. Further, we will review popular deep learning based encoding and decoding architectures and note their benefits and limitations. Finally, we will conclude with a brief summary and discussion about future trends. Given the large amount of recently published work in the `computational cognitive neuroscience' community, we believe that this survey nicely organizes the plethora of work and presents it as a coherent story.
A journey in ESN and LSTM visualisations on a language task
Dec 13, 2020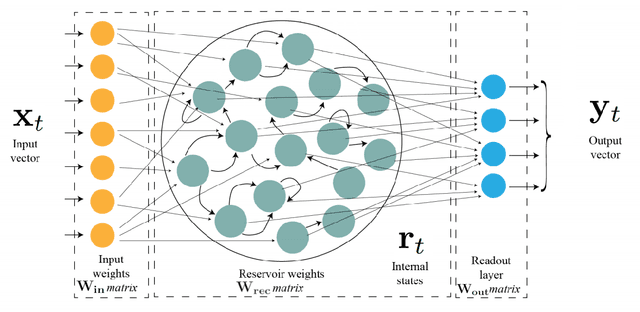

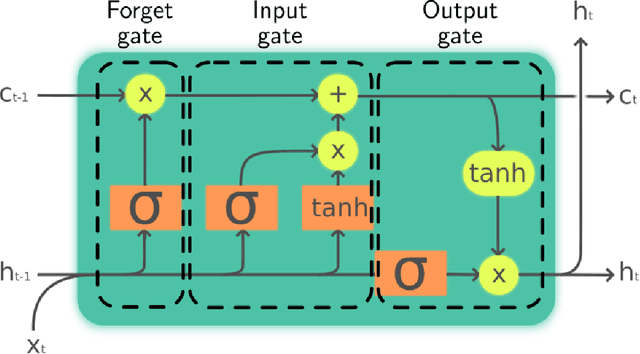

Echo States Networks (ESN) and Long-Short Term Memory networks (LSTM) are two popular architectures of Recurrent Neural Networks (RNN) to solve machine learning task involving sequential data. However, little have been done to compare their performances and their internal mechanisms on a common task. In this work, we trained ESNs and LSTMs on a Cross-Situationnal Learning (CSL) task. This task aims at modelling how infants learn language: they create associations between words and visual stimuli in order to extract meaning from words and sentences. The results are of three kinds: performance comparison, internal dynamics analyses and visualization of latent space. (1) We found that both models were able to successfully learn the task: the LSTM reached the lowest error for the basic corpus, but the ESN was quicker to train. Furthermore, the ESN was able to outperform LSTMs on datasets more challenging without any further tuning needed. (2) We also conducted an analysis of the internal units activations of LSTMs and ESNs. Despite the deep differences between both models (trained or fixed internal weights), we were able to uncover similar inner mechanisms: both put emphasis on the units encoding aspects of the sentence structure. (3) Moreover, we present Recurrent States Space Visualisations (RSSviz), a method to visualize the structure of latent state space of RNNs, based on dimension reduction (using UMAP). This technique enables us to observe a fractal embedding of sequences in the LSTM. RSSviz is also useful for the analysis of ESNs (i) to spot difficult examples and (ii) to generate animated plots showing the evolution of activations across learning stages. Finally, we explore qualitatively how the RSSviz could provide an intuitive visualisation to understand the influence of hyperparameters on the reservoir dynamics prior to ESN training.
Transfer between long-term and short-term memory using Conceptors
Mar 11, 2020



We introduce a recurrent neural network model of working memory combining short-term and long-term components. e short-term component is modelled using a gated reservoir model that is trained to hold a value from an input stream when a gate signal is on. e long-term component is modelled using conceptors in order to store inner temporal patterns (that corresponds to values). We combine these two components to obtain a model where information can go from long-term memory to short-term memory and vice-versa and we show how standard operations on conceptors allow to combine long-term memories and describe their effect on short-term memory.
A Simple Reservoir Model of Working Memory with Real Values
Jun 18, 2018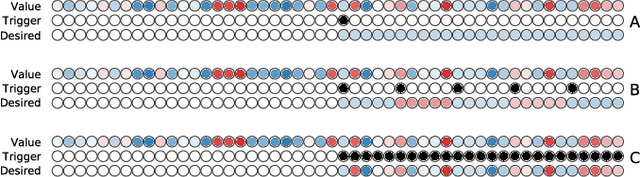
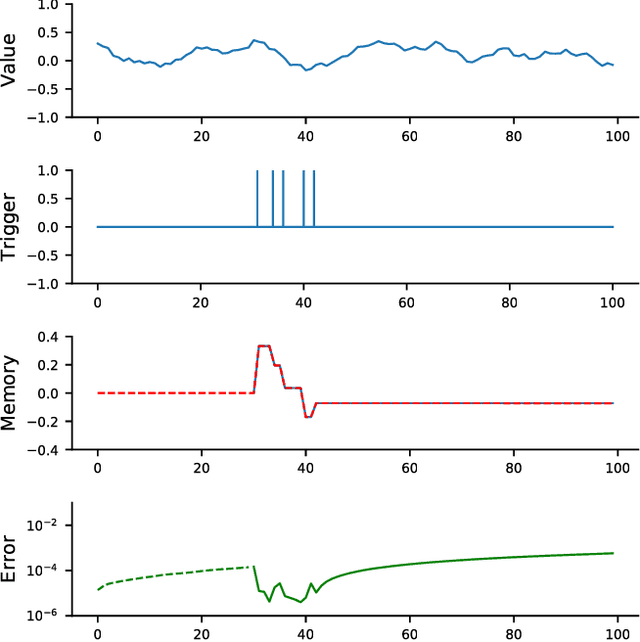
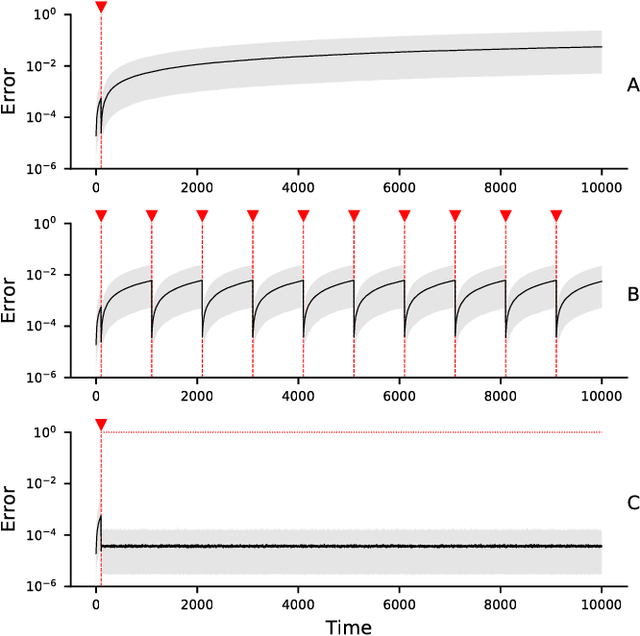
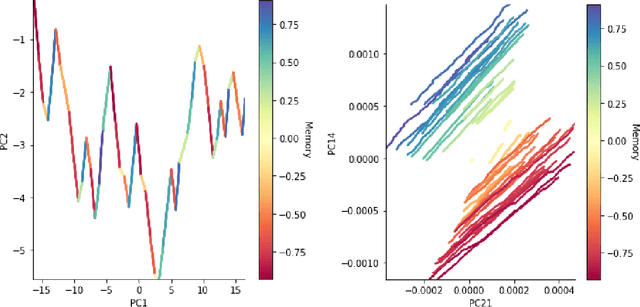
The prefrontal cortex is known to be involved in many high-level cognitive functions, in particular, working memory. Here, we study to what extent a group of randomly connected units (namely an Echo State Network, ESN) can store and maintain (as output) an arbitrary real value from a streamed input, i.e. can act as a sustained working memory unit. Furthermore, we explore to what extent such an architecture can take advantage of the stored value in order to produce non-linear computations. Comparison between different architectures (with and without feedback, with and without a working memory unit) shows that an explicit memory improves the performances.