 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypernetworks That Evolve Themselves
Dec 18, 2025



How can neural networks evolve themselves without relying on external optimizers? We propose Self-Referential Graph HyperNetworks, systems where the very machinery of variation and inheritance is embedded within the network. By uniting hypernetworks, stochastic parameter generation, and graph-based representations, Self-Referential GHNs mutate and evaluate themselves while adapting mutation rates as selectable traits. Through new reinforcement learning benchmarks with environmental shifts (CartPoleSwitch, LunarLander-Switch), Self-Referential GHNs show swift, reliable adaptation and emergent population dynamics. In the locomotion benchmark Ant-v5, they evolve coherent gaits, showing promising fine-tuning capabilities by autonomously decreasing variation in the population to concentrate around promising solutions. Our findings support the idea that evolvability itself can emerge from neural self-reference. Self-Referential GHNs reflect a step toward synthetic systems that more closely mirror biological evolution, offering tools for autonomous, open-ended learning agents.
When Does Neuroevolution Outcompete Reinforcement Learning in Transfer Learning Tasks?
May 28, 2025The ability to continuously and efficiently transfer skills across tasks is a hallmark of biological intelligence and a long-standing goal in artificial systems. Reinforcement learning (RL), a dominant paradigm for learning in high-dimensional control tasks, is known to suffer from brittleness to task variations and catastrophic forgetting. Neuroevolution (NE) has recently gained attention for its robustness, scalability, and capacity to escape local optima. In this paper, we investigate an understudied dimension of NE: its transfer learning capabilities. To this end, we introduce two benchmarks: a) in stepping gates, neural networks are tasked with emulating logic circuits, with designs that emphasize modular repetition and variation b) ecorobot extends the Brax physics engine with objects such as walls and obstacles and the ability to easily switch between different robotic morphologies. Crucial in both benchmarks is the presence of a curriculum that enables evaluating skill transfer across tasks of increasing complexity. Our empirical analysis shows that NE methods vary in their transfer abilities and frequently outperform RL baselines. Our findings support the potential of NE as a foundation for building more adaptable agents and highlight future challenges for scaling NE to complex, real-world problems.
Collective Innovation in Groups of Large Language Models
Jul 07, 2024



Human culture relies on collective innovation: our ability to continuously explore how existing elements in our environment can be combined to create new ones. Language is hypothesized to play a key role in human culture, driving individual cognitive capacities and shaping communication. Yet the majority of models of collective innovation assign no cognitive capacities or language abilities to agents. Here, we contribute a computational study of collective innovation where agents are Large Language Models (LLMs) that play Little Alchemy 2, a creative video game originally developed for humans that, as we argue, captures useful aspects of innovation landscapes not present in previous test-beds. We, first, study an LLM in isolation and discover that it exhibits both useful skills and crucial limitations. We, then, study groups of LLMs that share information related to their behaviour and focus on the effect of social connectivity on collective performance. In agreement with previous human and computational studies, we observe that groups with dynamic connectivity out-compete fully-connected groups. Our work reveals opportunities and challenges for future studies of collective innovation that are becoming increasingly relevant as Generative Artificial Intelligence algorithms and humans innovate alongside each other.
Evolving Self-Assembling Neural Networks: From Spontaneous Activity to Experience-Dependent Learning
Jun 14, 2024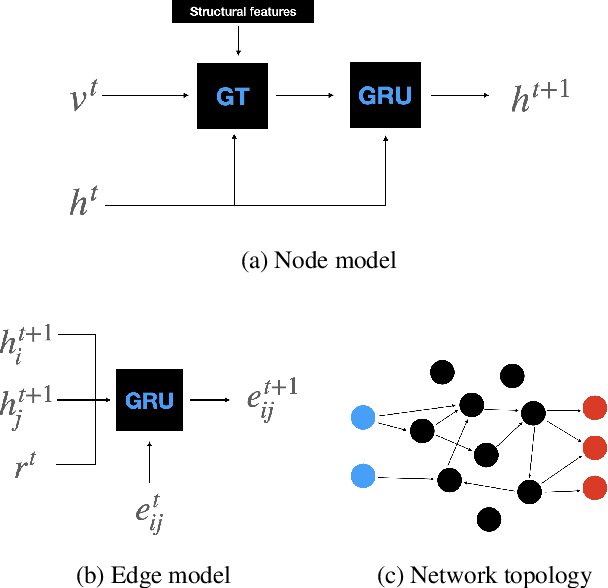
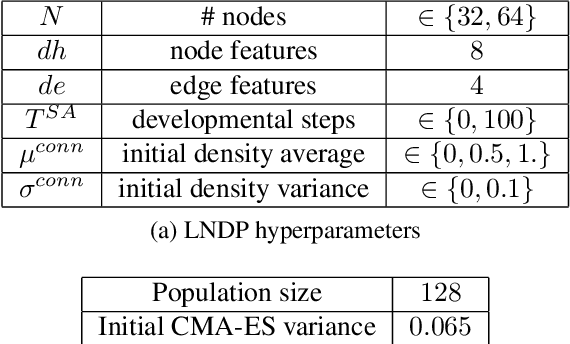
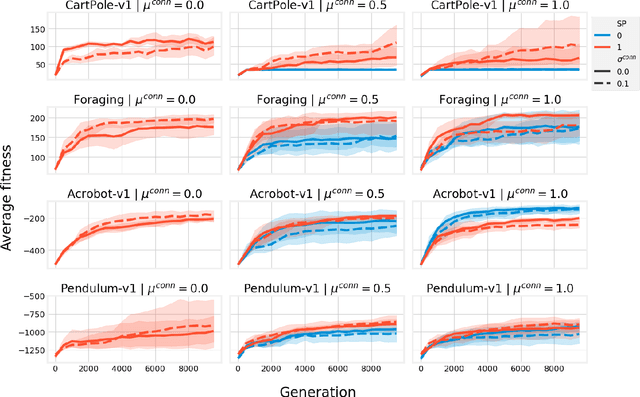
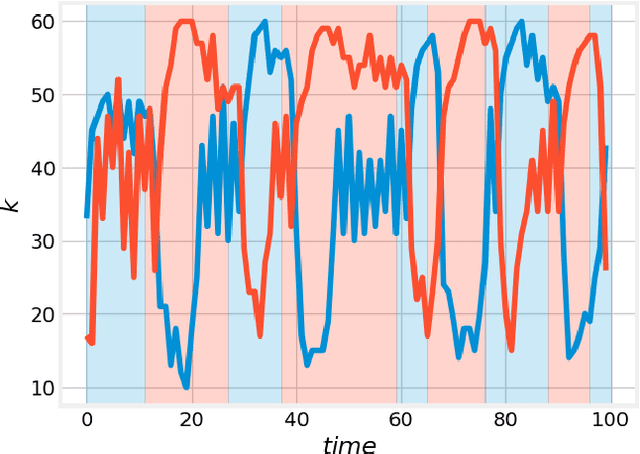
Biological neural networks are characterized by their high degree of plasticity, a core property that enables the remarkable adaptability of natural organisms. Importantly, this ability affects both the synaptic strength and the topology of the nervous systems. Artificial neural networks, on the other hand, have been mainly designed as static, fully connected structures that can be notoriously brittle in the face of changing environments and novel inputs. Building on previous works on Neural Developmental Programs (NDPs), we propose a class of self-organizing neural networks capable of synaptic and structural plasticity in an activity and reward-dependent manner which we call Lifelong Neural Developmental Program (LNDP). We present an instance of such a network built on the graph transformer architecture and propose a mechanism for pre-experience plasticity based on the spontaneous activity of sensory neurons. Our results demonstrate the ability of the model to learn from experiences in different control tasks starting from randomly connected or empty networks. We further show that structural plasticity is advantageous in environments necessitating fast adaptation or with non-stationary rewards.
Meta-Learning an Evolvable Developmental Encoding
Jun 13, 2024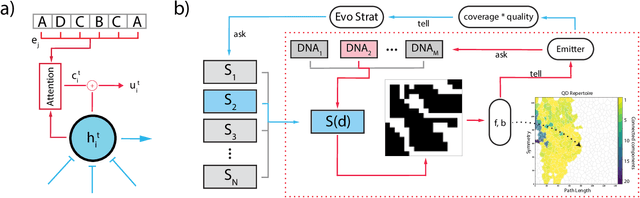
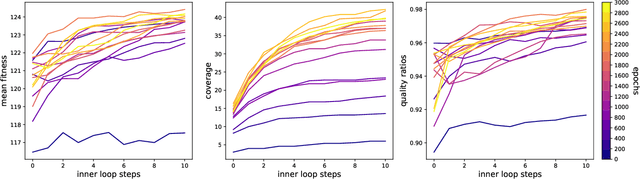
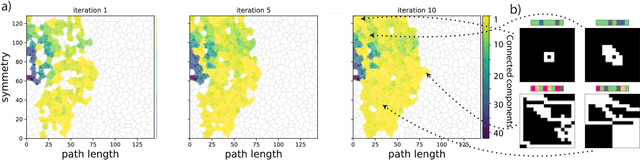
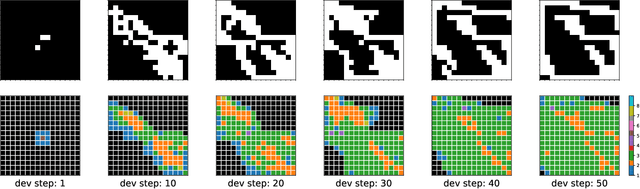
Representations for black-box optimisation methods (such as evolutionary algorithms) are traditionally constructed using a delicate manual process. This is in contrast to the representation that maps DNAs to phenotypes in biological organisms, which is at the hear of biological complexity and evolvability. Additionally, the core of this process is fundamentally the same across nearly all forms of life, reflecting their shared evolutionary origin. Generative models have shown promise in being learnable representations for black-box optimisation but they are not per se designed to be easily searchable. Here we present a system that can meta-learn such representation by directly optimising for a representation's ability to generate quality-diversity. In more detail, we show our meta-learning approach can find one Neural Cellular Automata, in which cells can attend to different parts of a "DNA" string genome during development, enabling it to grow different solvable 2D maze structures. We show that the evolved genotype-to-phenotype mappings become more and more evolvable, not only resulting in a faster search but also increasing the quality and diversity of grown artefacts.
Growing Artificial Neural Networks for Control: the Role of Neuronal Diversity
May 14, 2024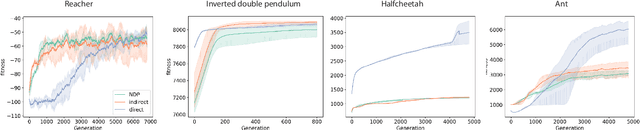

In biological evolution complex neural structures grow from a handful of cellular ingredients. As genomes in nature are bounded in size, this complexity is achieved by a growth process where cells communicate locally to decide whether to differentiate, proliferate and connect with other cells. This self-organisation is hypothesized to play an important part in the generalisation, and robustness of biological neural networks. Artificial neural networks (ANNs), on the other hand, are traditionally optimized in the space of weights. Thus, the benefits and challenges of growing artificial neural networks remain understudied. Building on the previously introduced Neural Developmental Programs (NDP), in this work we present an algorithm for growing ANNs that solve reinforcement learning tasks. We identify a key challenge: ensuring phenotypic complexity requires maintaining neuronal diversity, but this diversity comes at the cost of optimization stability. To address this, we introduce two mechanisms: (a) equipping neurons with an intrinsic state inherited upon neurogenesis; (b) lateral inhibition, a mechanism inspired by biological growth, which controlls the pace of growth, helping diversity persist. We show that both mechanisms contribute to neuronal diversity and that, equipped with them, NDPs achieve comparable results to existing direct and developmental encodings in complex locomotion tasks
Evolving Reservoirs for Meta Reinforcement Learning
Dec 09, 2023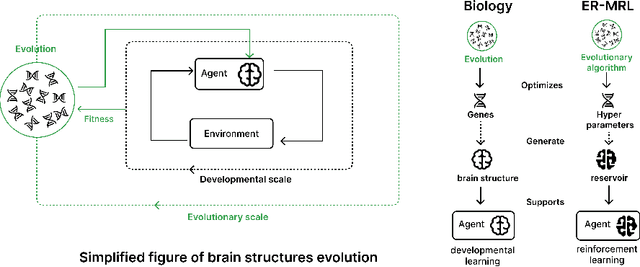
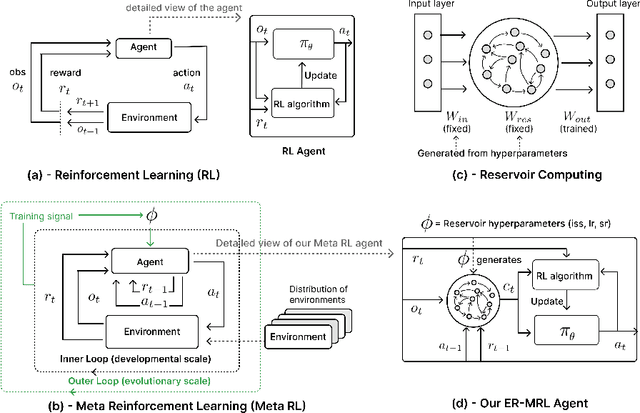
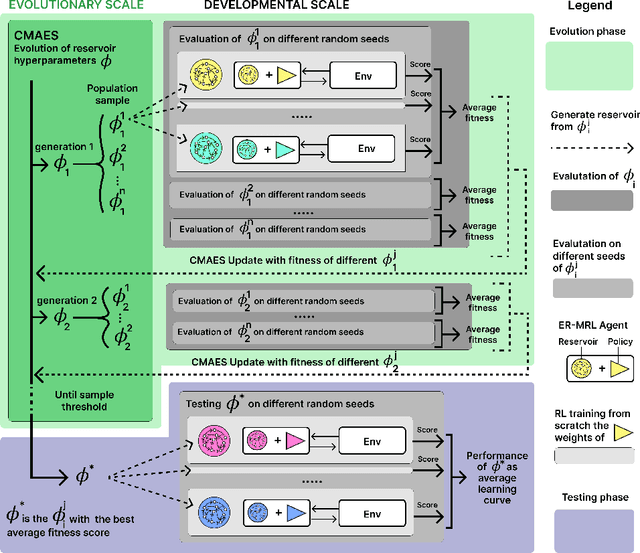
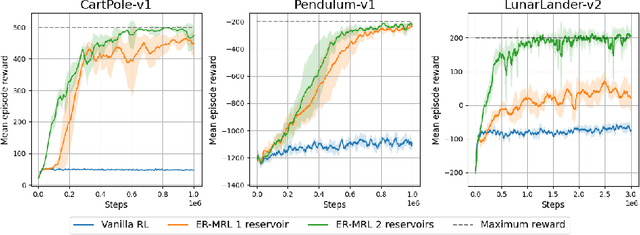
Animals often demonstrate a remarkable ability to adapt to their environments during their lifetime. They do so partly due to the evolution of morphological and neural structures. These structures capture features of environments shared between generations to bias and speed up lifetime learning. In this work, we propose a computational model for studying a mechanism that can enable such a process. We adopt a computational framework based on meta reinforcement learning as a model of the interplay between evolution and development. At the evolutionary scale, we evolve reservoirs, a family of recurrent neural networks that differ from conventional networks in that one optimizes not the weight values but hyperparameters of the architecture: the later control macro-level properties, such as memory and dynamics. At the developmental scale, we employ these evolved reservoirs to facilitate the learning of a behavioral policy through Reinforcement Learning (RL). Within an RL agent, a reservoir encodes the environment state before providing it to an action policy. We evaluate our approach on several 2D and 3D simulated environments. Our results show that the evolution of reservoirs can improve the learning of diverse challenging tasks. We study in particular three hypotheses: the use of an architecture combining reservoirs and reinforcement learning could enable (1) solving tasks with partial observability, (2) generating oscillatory dynamics that facilitate the learning of locomotion tasks, and (3) facilitating the generalization of learned behaviors to new tasks unknown during the evolution phase.
Emergence of Collective Open-Ended Exploration from Decentralized Meta-Reinforcement Learning
Nov 02, 2023Recent works have proven that intricate cooperative behaviors can emerge in agents trained using meta reinforcement learning on open ended task distributions using self-play. While the results are impressive, we argue that self-play and other centralized training techniques do not accurately reflect how general collective exploration strategies emerge in the natural world: through decentralized training and over an open-ended distribution of tasks. In this work we therefore investigate the emergence of collective exploration strategies, where several agents meta-learn independent recurrent policies on an open ended distribution of tasks. To this end we introduce a novel environment with an open ended procedurally generated task space which dynamically combines multiple subtasks sampled from five diverse task types to form a vast distribution of task trees. We show that decentralized agents trained in our environment exhibit strong generalization abilities when confronted with novel objects at test time. Additionally, despite never being forced to cooperate during training the agents learn collective exploration strategies which allow them to solve novel tasks never encountered during training. We further find that the agents learned collective exploration strategies extend to an open ended task setting, allowing them to solve task trees of twice the depth compared to the ones seen during training. Our open source code as well as videos of the agents can be found on our companion website.
Dynamics of niche construction in adaptable populations evolving in diverse environments
May 16, 2023



In both natural and artificial studies, evolution is often seen as synonymous to natural selection. Individuals evolve under pressures set by environments that are either reset or do not carry over significant changes from previous generations. Thus, niche construction (NC), the reciprocal process to natural selection where individuals incur inheritable changes to their environment, is ignored. Arguably due to this lack of study, the dynamics of NC are today little understood, especially in real-world settings. In this work, we study NC in simulation environments that consist of multiple, diverse niches and populations that evolve their plasticity, evolvability and niche-constructing behaviors. Our empirical analysis reveals many interesting dynamics, with populations experiencing mass extinctions, arms races and oscillations. To understand these behaviors, we analyze the interaction between NC and adaptability and the effect of NC on the population's genomic diversity and dispersal, observing that NC diversifies niches. Our study suggests that complexifying the simulation environments studying NC, by considering multiple and diverse niches, is necessary for understanding its dynamics and can lend testable hypotheses to future studies of both natural and artificial systems.
Eco-evolutionary Dynamics of Non-episodic Neuroevolution in Large Multi-agent Environments
Feb 18, 2023Neuroevolution (NE) has recently proven a competitive alternative to learning by gradient descent in reinforcement learning tasks. However, the majority of NE methods and associated simulation environments differ crucially from biological evolution: the environment is reset to initial conditions at the end of each generation, whereas natural environments are continuously modified by their inhabitants; agents reproduce based on their ability to maximize rewards within a population, while biological organisms reproduce and die based on internal physiological variables that depend on their resource consumption; simulation environments are primarily single-agent while the biological world is inherently multi-agent and evolves alongside the population. In this work we present a method for continuously evolving adaptive agents without any environment or population reset. The environment is a large grid world with complex spatiotemporal resource generation, containing many agents that are each controlled by an evolvable recurrent neural network and locally reproduce based on their internal physiology. The entire system is implemented in JAX, allowing very fast simulation on a GPU. We show that NE can operate in an ecologically-valid non-episodic multi-agent setting, finding sustainable collective foraging strategies in the presence of a complex interplay between ecological and evolutionary dynamics.