 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpedition & Expansion: Leveraging Semantic Representations for Goal-Directed Exploration in Continuous Cellular Automata
Sep 04, 2025Discovering diverse visual patterns in continuous cellular automata (CA) is challenging due to the vastness and redundancy of high-dimensional behavioral spaces. Traditional exploration methods like Novelty Search (NS) expand locally by mutating known novel solutions but often plateau when local novelty is exhausted, failing to reach distant, unexplored regions. We introduce Expedition and Expansion (E&E), a hybrid strategy where exploration alternates between local novelty-driven expansions and goal-directed expeditions. During expeditions, E&E leverages a Vision-Language Model (VLM) to generate linguistic goals--descriptions of interesting but hypothetical patterns that drive exploration toward uncharted regions. By operating in semantic spaces that align with human perception, E&E both evaluates novelty and generates goals in conceptually meaningful ways, enhancing the interpretability and relevance of discovered behaviors. Tested on Flow Lenia, a continuous CA known for its rich, emergent behaviors, E&E consistently uncovers more diverse solutions than existing exploration methods. A genealogical analysis further reveals that solutions originating from expeditions disproportionately influence long-term exploration, unlocking new behavioral niches that serve as stepping stones for subsequent search. These findings highlight E&E's capacity to break through local novelty boundaries and explore behavioral landscapes in human-aligned, interpretable ways, offering a promising template for open-ended exploration in artificial life and beyond.
HERAKLES: Hierarchical Skill Compilation for Open-ended LLM Agents
Aug 20, 2025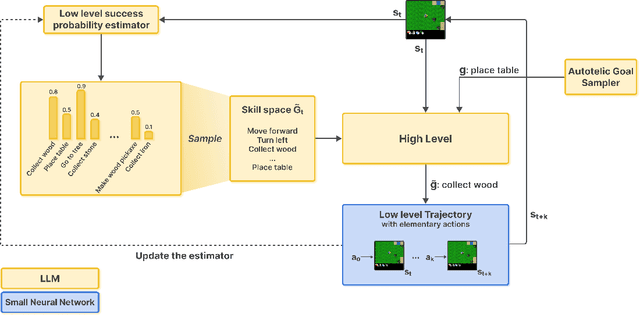
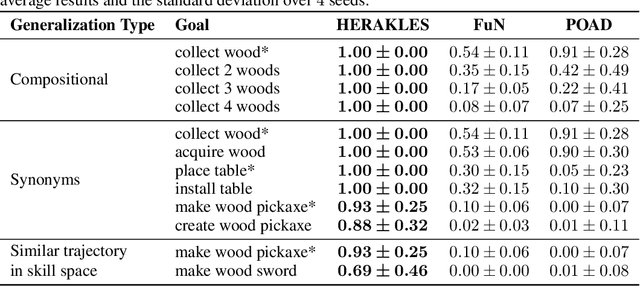
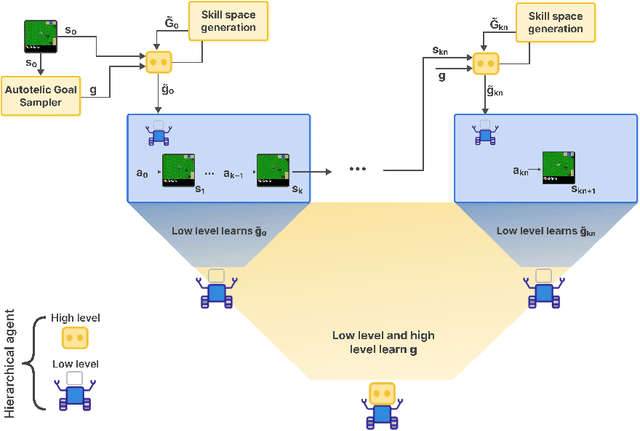

Open-ended AI agents need to be able to learn efficiently goals of increasing complexity, abstraction and heterogeneity over their lifetime. Beyond sampling efficiently their own goals, autotelic agents specifically need to be able to keep the growing complexity of goals under control, limiting the associated growth in sample and computational complexity. To adress this challenge, recent approaches have leveraged hierarchical reinforcement learning (HRL) and language, capitalizing on its compositional and combinatorial generalization capabilities to acquire temporally extended reusable behaviours. Existing approaches use expert defined spaces of subgoals over which they instantiate a hierarchy, and often assume pre-trained associated low-level policies. Such designs are inadequate in open-ended scenarios, where goal spaces naturally diversify across a broad spectrum of difficulties. We introduce HERAKLES, a framework that enables a two-level hierarchical autotelic agent to continuously compile mastered goals into the low-level policy, executed by a small, fast neural network, dynamically expanding the set of subgoals available to the high-level policy. We train a Large Language Model (LLM) to serve as the high-level controller, exploiting its strengths in goal decomposition and generalization to operate effectively over this evolving subgoal space. We evaluate HERAKLES in the open-ended Crafter environment and show that it scales effectively with goal complexity, improves sample efficiency through skill compilation, and enables the agent to adapt robustly to novel challenges over time.
Flow-Lenia: Emergent evolutionary dynamics in mass conservative continuous cellular automata
Jun 10, 2025Central to the artificial life endeavour is the creation of artificial systems spontaneously generating properties found in the living world such as autopoiesis, self-replication, evolution and open-endedness. While numerous models and paradigms have been proposed, cellular automata (CA) have taken a very important place in the field notably as they enable the study of phenomenons like self-reproduction and autopoiesis. Continuous CA like Lenia have been showed to produce life-like patterns reminiscent, on an aesthetic and ontological point of view, of biological organisms we call creatures. We propose in this paper Flow-Lenia, a mass conservative extension of Lenia. We present experiments demonstrating its effectiveness in generating spatially-localized patters (SLPs) with complex behaviors and show that the update rule parameters can be optimized to generate complex creatures showing behaviors of interest. Furthermore, we show that Flow-Lenia allows us to embed the parameters of the model, defining the properties of the emerging patterns, within its own dynamics thus allowing for multispecies simulations. By using the evolutionary activity framework as well as other metrics, we shed light on the emergent evolutionary dynamics taking place in this system.
* This manuscript has been accepted for publication in the Artificial Life journal (https://direct.mit.edu/artl)
WorldLLM: Improving LLMs' world modeling using curiosity-driven theory-making
Jun 07, 2025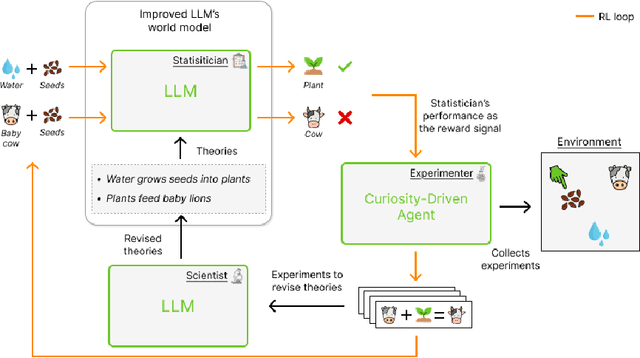
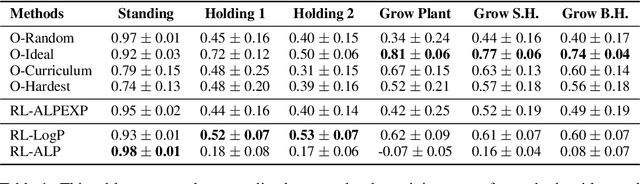
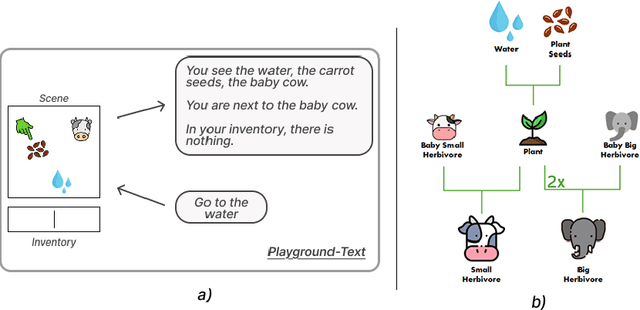
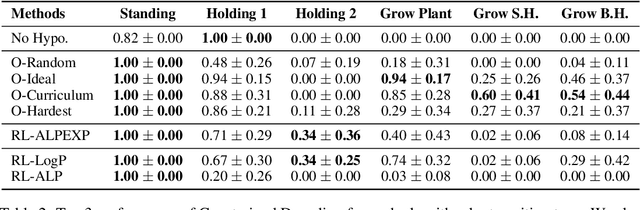
Large Language Models (LLMs) possess general world knowledge but often struggle to generate precise predictions in structured, domain-specific contexts such as simulations. These limitations arise from their inability to ground their broad, unstructured understanding in specific environments. To address this, we present WorldLLM, a framework that enhances LLM-based world modeling by combining Bayesian inference and autonomous active exploration with reinforcement learning. WorldLLM leverages the in-context learning abilities of LLMs to guide an LLM-based world model's predictions using natural language hypotheses given in its prompt. These hypotheses are iteratively refined through a Bayesian inference framework that leverages a second LLM as the proposal distribution given collected evidence. This evidence is collected using a curiosity-driven reinforcement learning policy that explores the environment to find transitions with a low log-likelihood under our LLM-based predictive model using the current hypotheses. By alternating between refining hypotheses and collecting new evidence, our framework autonomously drives continual improvement of the predictions. Our experiments demonstrate the effectiveness of WorldLLM in a textual game environment that requires agents to manipulate and combine objects. The framework not only enhances predictive accuracy, but also generates human-interpretable theories of environment dynamics.
Exploring Flow-Lenia Universes with a Curiosity-driven AI Scientist: Discovering Diverse Ecosystem Dynamics
May 21, 2025We present a method for the automated discovery of system-level dynamics in Flow-Lenia$-$a continuous cellular automaton (CA) with mass conservation and parameter localization$-$using a curiosity-driven AI scientist. This method aims to uncover processes leading to self-organization of evolutionary and ecosystemic dynamics in CAs. We build on previous work which uses diversity search algorithms in Lenia to find self-organized individual patterns, and extend it to large environments that support distinct interacting patterns. We adapt Intrinsically Motivated Goal Exploration Processes (IMGEPs) to drive exploration of diverse Flow-Lenia environments using simulation-wide metrics, such as evolutionary activity, compression-based complexity, and multi-scale entropy. We test our method in two experiments, showcasing its ability to illuminate significantly more diverse dynamics compared to random search. We show qualitative results illustrating how ecosystemic simulations enable self-organization of complex collective behaviors not captured by previous individual pattern search and analysis. We complement automated discovery with an interactive exploration tool, creating an effective human-AI collaborative workflow for scientific investigation. Though demonstrated specifically with Flow-Lenia, this methodology provides a framework potentially applicable to other parameterizable complex systems where understanding emergent collective properties is of interest.
Recursive Training Loops in LLMs: How training data properties modulate distribution shift in generated data?
Apr 08, 2025Large language models (LLMs) are increasingly contributing to the creation of content on the Internet. This creates a feedback loop as subsequent generations of models will be trained on this generated, synthetic data. This phenomenon is receiving increasing interest, in particular because previous studies have shown that it may lead to distribution shift - models misrepresent and forget the true underlying distributions of human data they are expected to approximate (e.g. resulting in a drastic loss of quality). In this study, we study the impact of human data properties on distribution shift dynamics in iterated training loops. We first confirm that the distribution shift dynamics greatly vary depending on the human data by comparing four datasets (two based on Twitter and two on Reddit). We then test whether data quality may influence the rate of this shift. We find that it does on the twitter, but not on the Reddit datasets. We then focus on a Reddit dataset and conduct a more exhaustive evaluation of a large set of dataset properties. This experiment associated lexical diversity with larger, and semantic diversity with smaller detrimental shifts, suggesting that incorporating text with high lexical (but limited semantic) diversity could exacerbate the degradation of generated text. We then focus on the evolution of political bias, and find that the type of shift observed (bias reduction, amplification or inversion) depends on the political lean of the human (true) distribution. Overall, our work extends the existing literature on the consequences of recursive fine-tuning by showing that this phenomenon is highly dependent on features of the human data on which training occurs. This suggests that different parts of internet (e.g. GitHub, Reddit) may undergo different types of shift depending on their properties.
MAGELLAN: Metacognitive predictions of learning progress guide autotelic LLM agents in large goal spaces
Feb 12, 2025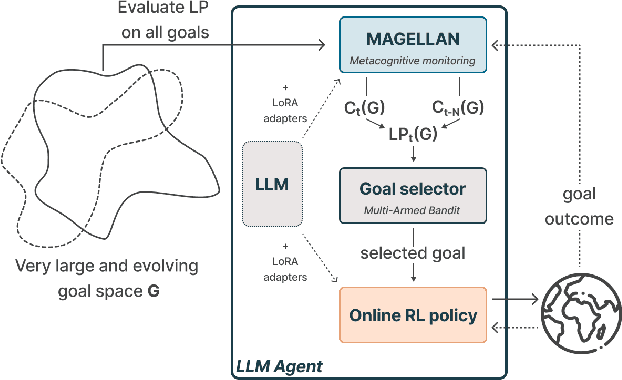
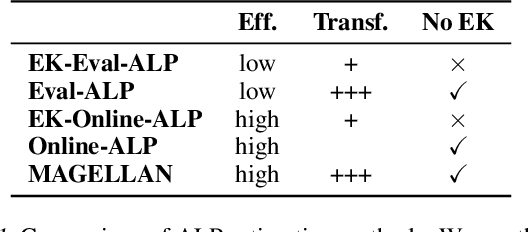
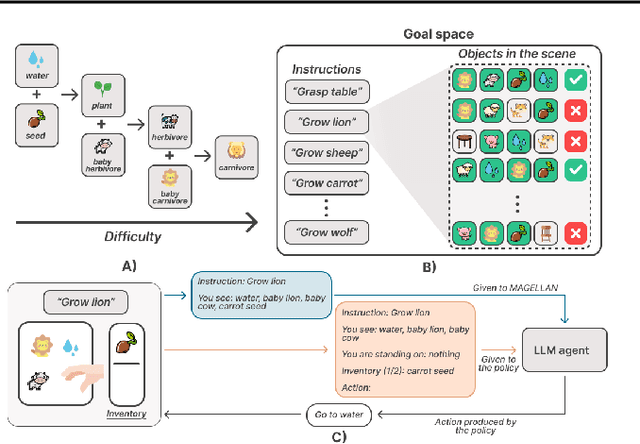
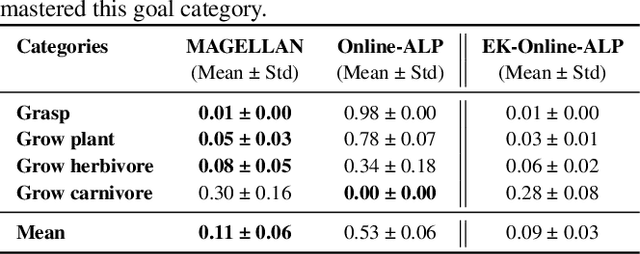
Open-ended learning agents must efficiently prioritize goals in vast possibility spaces, focusing on those that maximize learning progress (LP). When such autotelic exploration is achieved by LLM agents trained with online RL in high-dimensional and evolving goal spaces, a key challenge for LP prediction is modeling one's own competence, a form of metacognitive monitoring. Traditional approaches either require extensive sampling or rely on brittle expert-defined goal groupings. We introduce MAGELLAN, a metacognitive framework that lets LLM agents learn to predict their competence and LP online. By capturing semantic relationships between goals, MAGELLAN enables sample-efficient LP estimation and dynamic adaptation to evolving goal spaces through generalization. In an interactive learning environment, we show that MAGELLAN improves LP prediction efficiency and goal prioritization, being the only method allowing the agent to fully master a large and evolving goal space. These results demonstrate how augmenting LLM agents with a metacognitive ability for LP predictions can effectively scale curriculum learning to open-ended goal spaces.
Automatic Generation of Question Hints for Mathematics Problems using Large Language Models in Educational Technology
Nov 05, 2024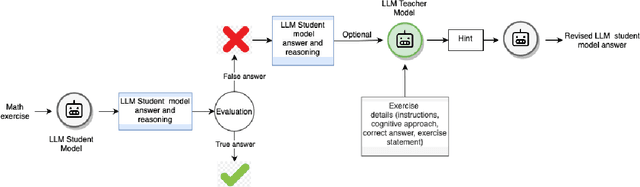
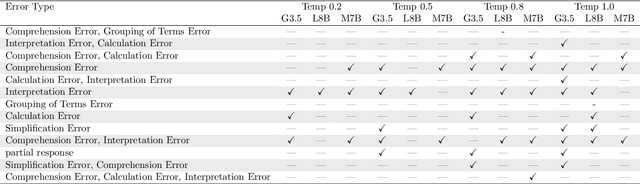
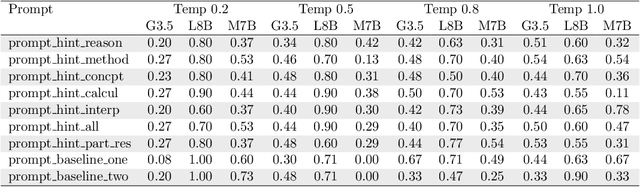
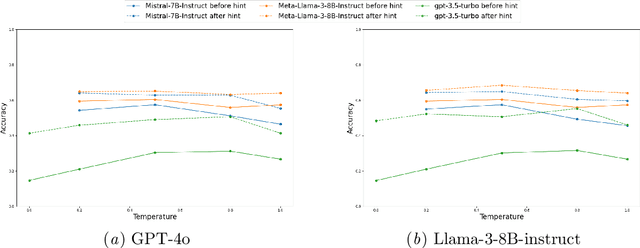
The automatic generation of hints by Large Language Models (LLMs) within Intelligent Tutoring Systems (ITSs) has shown potential to enhance student learning. However, generating pedagogically sound hints that address student misconceptions and adhere to specific educational objectives remains challenging. This work explores using LLMs (GPT-4o and Llama-3-8B-instruct) as teachers to generate effective hints for students simulated through LLMs (GPT-3.5-turbo, Llama-3-8B-Instruct, or Mistral-7B-instruct-v0.3) tackling math exercises designed for human high-school students, and designed using cognitive science principles. We present here the study of several dimensions: 1) identifying error patterns made by simulated students on secondary-level math exercises; 2) developing various prompts for GPT-4o as a teacher and evaluating their effectiveness in generating hints that enable simulated students to self-correct; and 3) testing the best-performing prompts, based on their ability to produce relevant hints and facilitate error correction, with Llama-3-8B-Instruct as the teacher, allowing for a performance comparison with GPT-4o. The results show that model errors increase with higher temperature settings. Notably, when hints are generated by GPT-4o, the most effective prompts include prompts tailored to specific errors as well as prompts providing general hints based on common mathematical errors. Interestingly, Llama-3-8B-Instruct as a teacher showed better overall performance than GPT-4o. Also the problem-solving and response revision capabilities of the LLMs as students, particularly GPT-3.5-turbo, improved significantly after receiving hints, especially at lower temperature settings. However, models like Mistral-7B-Instruct demonstrated a decline in performance as the temperature increased.
Reinforcement Learning for Aligning Large Language Models Agents with Interactive Environments: Quantifying and Mitigating Prompt Overfitting
Oct 29, 2024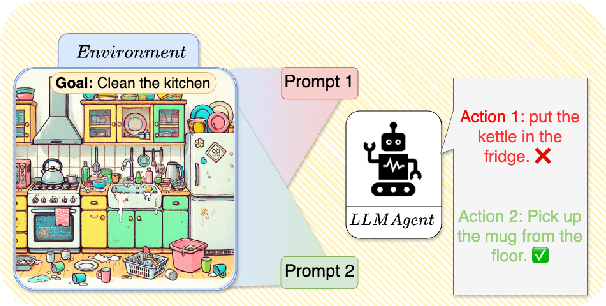
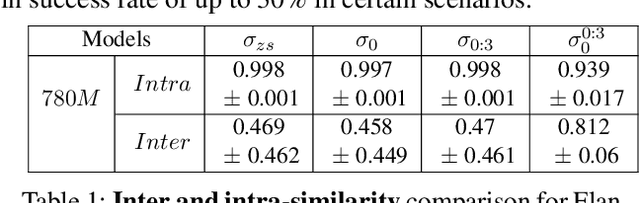
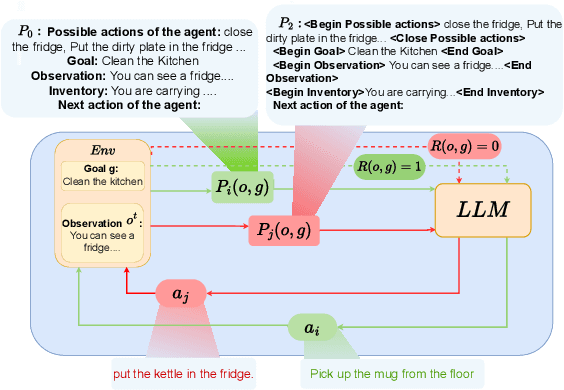
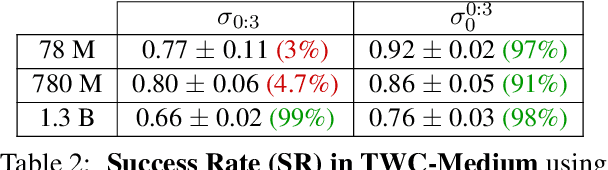
Reinforcement learning (RL) is a promising approach for aligning large language models (LLMs) knowledge with sequential decision-making tasks. However, few studies have thoroughly investigated the impact on LLM agents capabilities of fine-tuning them with RL in a specific environment. In this paper, we propose a novel framework to analyze the sensitivity of LLMs to prompt formulations following RL training in a textual environment. Our findings reveal that the performance of LLMs degrades when faced with prompt formulations different from those used during the RL training phase. Besides, we analyze the source of this sensitivity by examining the model's internal representations and salient tokens. Finally, we propose to use a contrastive loss to mitigate this sensitivity and improve the robustness and generalization capabilities of LLMs.
SAC-GLAM: Improving Online RL for LLM agents with Soft Actor-Critic and Hindsight Relabeling
Oct 16, 2024



The past years have seen Large Language Models (LLMs) strive not only as generative models but also as agents solving textual sequential decision-making tasks. When facing complex environments where their zero-shot abilities are insufficient, recent work showed online Reinforcement Learning (RL) could be used for the LLM agent to discover and learn efficient strategies interactively. However, most prior work sticks to on-policy algorithms, which greatly reduces the scope of methods such agents could use for both exploration and exploitation, such as experience replay and hindsight relabeling. Yet, such methods may be key for LLM learning agents, and in particular when designing autonomous intrinsically motivated agents sampling and pursuing their own goals (i.e. autotelic agents). This paper presents and studies an adaptation of Soft Actor-Critic and hindsight relabeling to LLM agents. Our method not only paves the path towards autotelic LLM agents that learn online but can also outperform on-policy methods in more classic multi-goal RL environments.