 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Contamination in Large Language Models: Introducing the LogProber method
Aug 26, 2024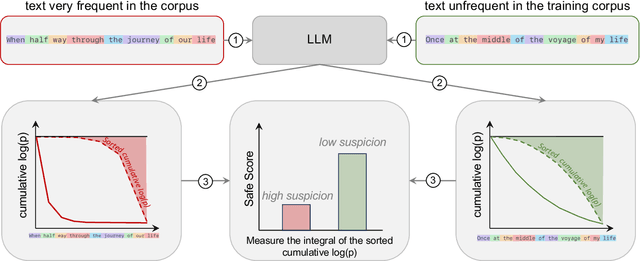
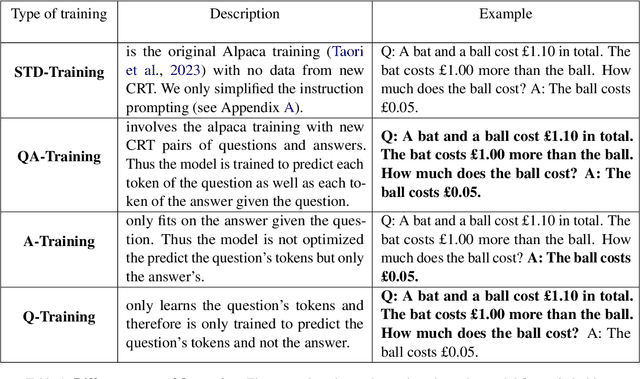
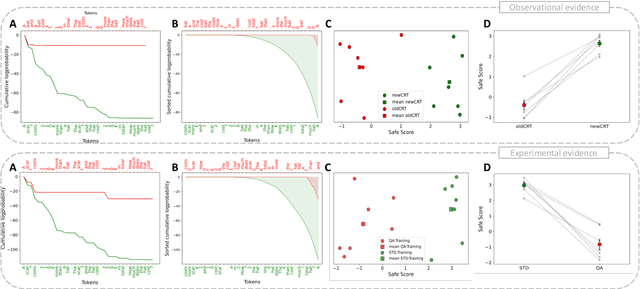
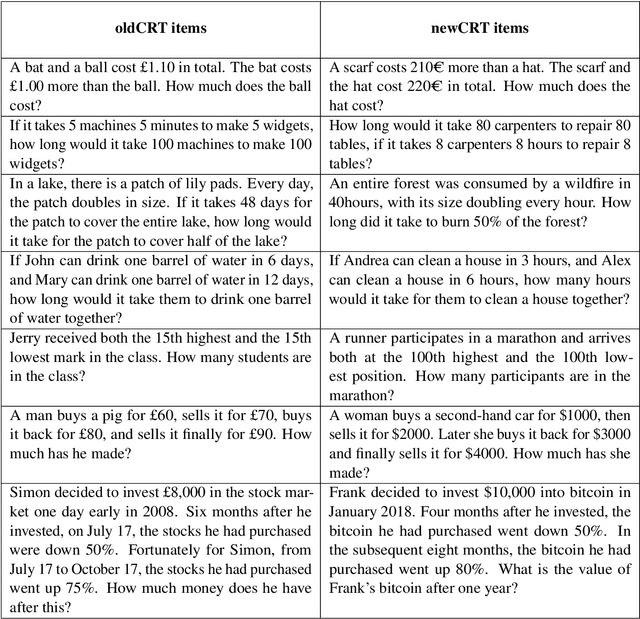
In machine learning, contamination refers to situations where testing data leak into the training set. The issue is particularly relevant for the evaluation of the performance of Large Language Models (LLMs), which are generally trained on gargantuan, and generally opaque, corpora of text scraped from the world wide web. Developing tools to detect contamination is therefore crucial to be able to fairly and properly track the evolution of the performance of LLMs. Most recent works in the field are not tailored to quantify contamination on short sequences of text like we find in psychology questionnaires. In the present paper we introduce LogProber, a novel, efficient, algorithm that we show able to detect contamination using token probability in given sentences. In the second part we investigate the limitations of the method and discuss how different training methods can contaminate models without leaving traces in the token probabilities.
Large Language Models are Biased Reinforcement Learners
May 19, 2024
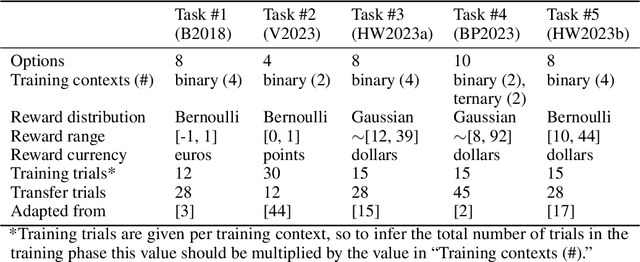
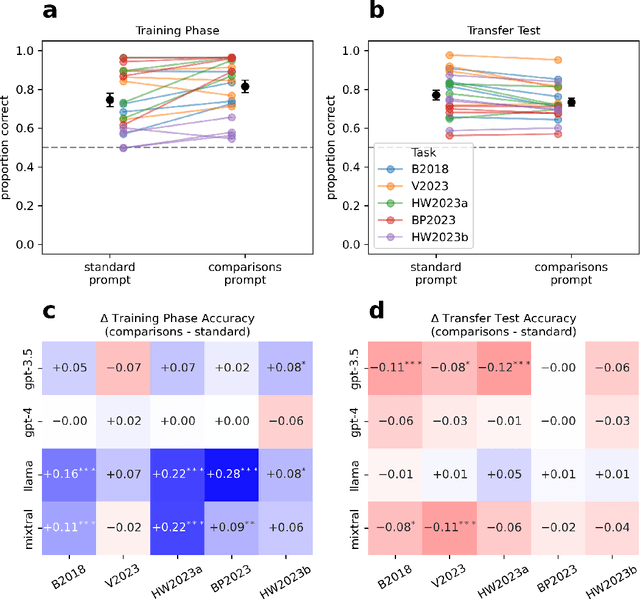
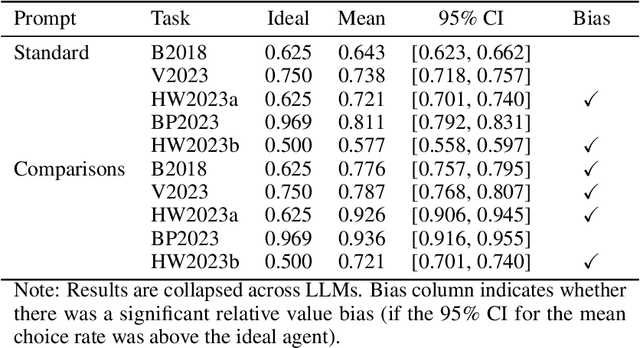
In-context learning enables large language models (LLMs) to perform a variety of tasks, including learning to make reward-maximizing choices in simple bandit tasks. Given their potential use as (autonomous) decision-making agents, it is important to understand how these models perform such reinforcement learning (RL) tasks and the extent to which they are susceptible to biases. Motivated by the fact that, in humans, it has been widely documented that the value of an outcome depends on how it compares to other local outcomes, the present study focuses on whether similar value encoding biases apply to how LLMs encode rewarding outcomes. Results from experiments with multiple bandit tasks and models show that LLMs exhibit behavioral signatures of a relative value bias. Adding explicit outcome comparisons to the prompt produces opposing effects on performance, enhancing maximization in trained choice sets but impairing generalization to new choice sets. Computational cognitive modeling reveals that LLM behavior is well-described by a simple RL algorithm that incorporates relative values at the outcome encoding stage. Lastly, we present preliminary evidence that the observed biases are not limited to fine-tuned LLMs, and that relative value processing is detectable in the final hidden layer activations of a raw, pretrained model. These findings have important implications for the use of LLMs in decision-making applications.
Inferring the Phylogeny of Large Language Models and Predicting their Performances in Benchmarks
Apr 06, 2024



This paper introduces PhyloLM, a method applying phylogenetic algorithms to Large Language Models to explore their finetuning relationships, and predict their performance characteristics. By leveraging the phylogenetic distance metric, we construct dendrograms, which satisfactorily capture distinct LLM families (across a set of 77 open-source and 22 closed models). Furthermore, phylogenetic distance predicts performances in benchmarks (we test MMLU and ARC), thus enabling a time and cost-effective estimation of LLM capabilities. The approach translates genetic concepts to machine learning, offering tools to infer LLM development, relationships, and capabilities, even in the absence of transparent training information.
Relative Value Biases in Large Language Models
Jan 25, 2024


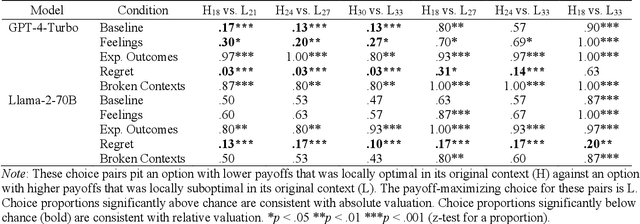
Studies of reinforcement learning in humans and animals have demonstrated a preference for options that yielded relatively better outcomes in the past, even when those options are associated with lower absolute reward. The present study tested whether large language models would exhibit a similar bias. We had gpt-4-1106-preview (GPT-4 Turbo) and Llama-2-70B make repeated choices between pairs of options with the goal of maximizing payoffs. A complete record of previous outcomes was included in each prompt. Both models exhibited relative value decision biases similar to those observed in humans and animals. Making relative comparisons among outcomes more explicit magnified the bias, whereas prompting the models to estimate expected outcomes caused the bias to disappear. These results have implications for the potential mechanisms that contribute to context-dependent choice in human agents.
Studying and improving reasoning in humans and machines
Sep 21, 2023In the present study, we investigate and compare reasoning in large language models (LLM) and humans using a selection of cognitive psychology tools traditionally dedicated to the study of (bounded) rationality. To do so, we presented to human participants and an array of pretrained LLMs new variants of classical cognitive experiments, and cross-compared their performances. Our results showed that most of the included models presented reasoning errors akin to those frequently ascribed to error-prone, heuristic-based human reasoning. Notwithstanding this superficial similarity, an in-depth comparison between humans and LLMs indicated important differences with human-like reasoning, with models limitations disappearing almost entirely in more recent LLMs releases. Moreover, we show that while it is possible to devise strategies to induce better performance, humans and machines are not equally-responsive to the same prompting schemes. We conclude by discussing the epistemological implications and challenges of comparing human and machine behavior for both artificial intelligence and cognitive psychology.