 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Contamination in Large Language Models: Introducing the LogProber method
Paper and Code
Aug 26, 2024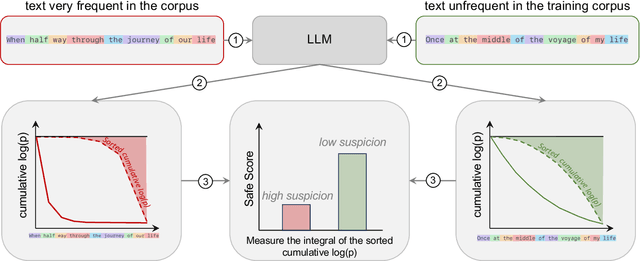
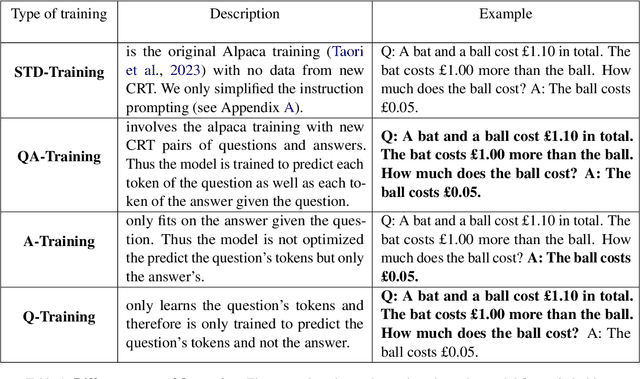
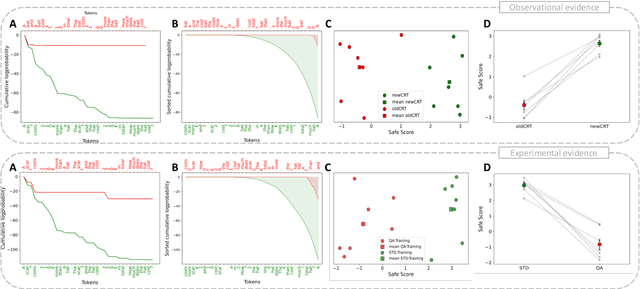
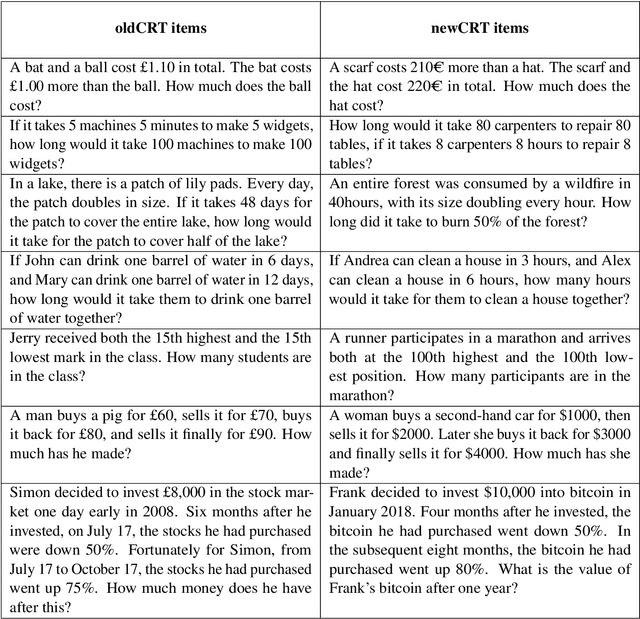
In machine learning, contamination refers to situations where testing data leak into the training set. The issue is particularly relevant for the evaluation of the performance of Large Language Models (LLMs), which are generally trained on gargantuan, and generally opaque, corpora of text scraped from the world wide web. Developing tools to detect contamination is therefore crucial to be able to fairly and properly track the evolution of the performance of LLMs. Most recent works in the field are not tailored to quantify contamination on short sequences of text like we find in psychology questionnaires. In the present paper we introduce LogProber, a novel, efficient, algorithm that we show able to detect contamination using token probability in given sentences. In the second part we investigate the limitations of the method and discuss how different training methods can contaminate models without leaving traces in the token probabilities.