 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Biased Reinforcement Learners
May 19, 2024
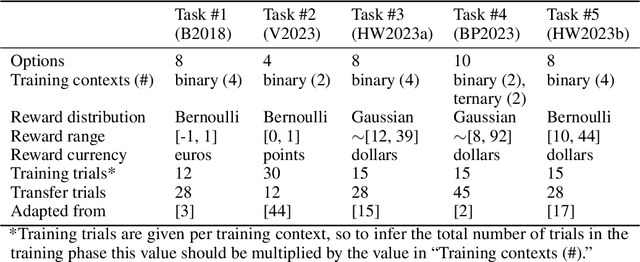
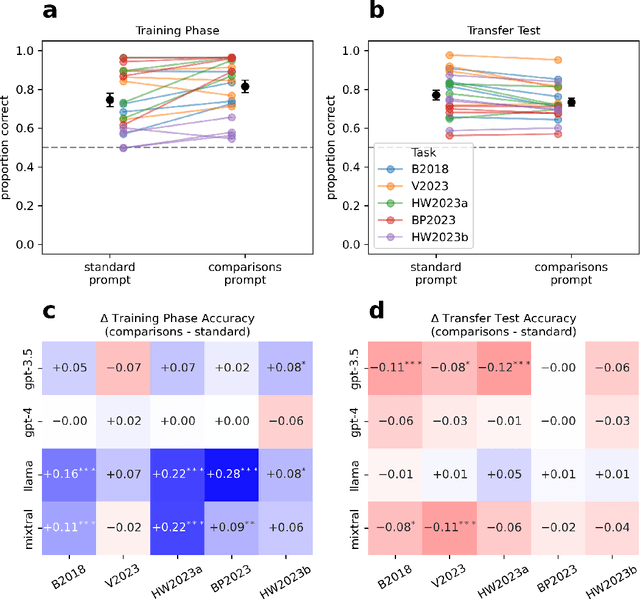
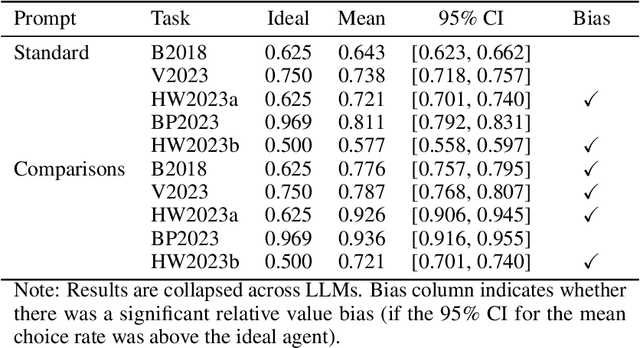
In-context learning enables large language models (LLMs) to perform a variety of tasks, including learning to make reward-maximizing choices in simple bandit tasks. Given their potential use as (autonomous) decision-making agents, it is important to understand how these models perform such reinforcement learning (RL) tasks and the extent to which they are susceptible to biases. Motivated by the fact that, in humans, it has been widely documented that the value of an outcome depends on how it compares to other local outcomes, the present study focuses on whether similar value encoding biases apply to how LLMs encode rewarding outcomes. Results from experiments with multiple bandit tasks and models show that LLMs exhibit behavioral signatures of a relative value bias. Adding explicit outcome comparisons to the prompt produces opposing effects on performance, enhancing maximization in trained choice sets but impairing generalization to new choice sets. Computational cognitive modeling reveals that LLM behavior is well-described by a simple RL algorithm that incorporates relative values at the outcome encoding stage. Lastly, we present preliminary evidence that the observed biases are not limited to fine-tuned LLMs, and that relative value processing is detectable in the final hidden layer activations of a raw, pretrained model. These findings have important implications for the use of LLMs in decision-making applications.
Relative Value Biases in Large Language Models
Jan 25, 2024


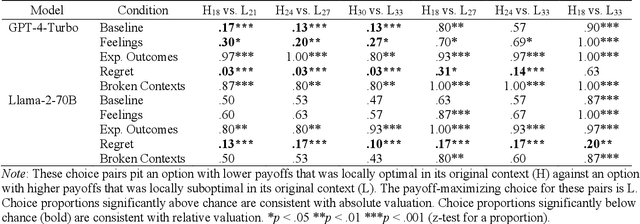
Studies of reinforcement learning in humans and animals have demonstrated a preference for options that yielded relatively better outcomes in the past, even when those options are associated with lower absolute reward. The present study tested whether large language models would exhibit a similar bias. We had gpt-4-1106-preview (GPT-4 Turbo) and Llama-2-70B make repeated choices between pairs of options with the goal of maximizing payoffs. A complete record of previous outcomes was included in each prompt. Both models exhibited relative value decision biases similar to those observed in humans and animals. Making relative comparisons among outcomes more explicit magnified the bias, whereas prompting the models to estimate expected outcomes caused the bias to disappear. These results have implications for the potential mechanisms that contribute to context-dependent choice in human agents.