 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Training Loops in LLMs: How training data properties modulate distribution shift in generated data?
Apr 08, 2025Large language models (LLMs) are increasingly contributing to the creation of content on the Internet. This creates a feedback loop as subsequent generations of models will be trained on this generated, synthetic data. This phenomenon is receiving increasing interest, in particular because previous studies have shown that it may lead to distribution shift - models misrepresent and forget the true underlying distributions of human data they are expected to approximate (e.g. resulting in a drastic loss of quality). In this study, we study the impact of human data properties on distribution shift dynamics in iterated training loops. We first confirm that the distribution shift dynamics greatly vary depending on the human data by comparing four datasets (two based on Twitter and two on Reddit). We then test whether data quality may influence the rate of this shift. We find that it does on the twitter, but not on the Reddit datasets. We then focus on a Reddit dataset and conduct a more exhaustive evaluation of a large set of dataset properties. This experiment associated lexical diversity with larger, and semantic diversity with smaller detrimental shifts, suggesting that incorporating text with high lexical (but limited semantic) diversity could exacerbate the degradation of generated text. We then focus on the evolution of political bias, and find that the type of shift observed (bias reduction, amplification or inversion) depends on the political lean of the human (true) distribution. Overall, our work extends the existing literature on the consequences of recursive fine-tuning by showing that this phenomenon is highly dependent on features of the human data on which training occurs. This suggests that different parts of internet (e.g. GitHub, Reddit) may undergo different types of shift depending on their properties.
When LLMs Play the Telephone Game: Cumulative Changes and Attractors in Iterated Cultural Transmissions
Jul 05, 2024



As large language models (LLMs) start interacting with each other and generating an increasing amount of text online, it becomes crucial to better understand how information is transformed as it passes from one LLM to the next. While significant research has examined individual LLM behaviors, existing studies have largely overlooked the collective behaviors and information distortions arising from iterated LLM interactions. Small biases, negligible at the single output level, risk being amplified in iterated interactions, potentially leading the content to evolve towards attractor states. In a series of telephone game experiments, we apply a transmission chain design borrowed from the human cultural evolution literature: LLM agents iteratively receive, produce, and transmit texts from the previous to the next agent in the chain. By tracking the evolution of text toxicity, positivity, difficulty, and length across transmission chains, we uncover the existence of biases and attractors, and study their dependence on the initial text, the instructions, language model, and model size. For instance, we find that more open-ended instructions lead to stronger attraction effects compared to more constrained tasks. We also find that different text properties display different sensitivity to attraction effects, with toxicity leading to stronger attractors than length. These findings highlight the importance of accounting for multi-step transmission dynamics and represent a first step towards a more comprehensive understanding of LLM cultural dynamics.
Cultural evolution in populations of Large Language Models
Mar 13, 2024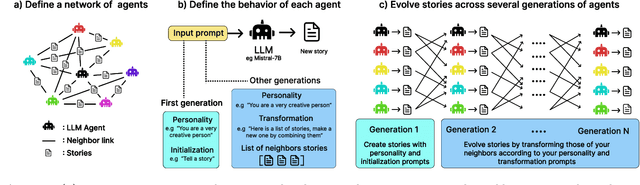
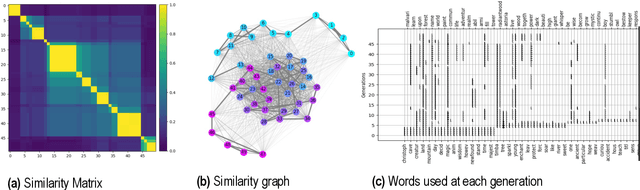
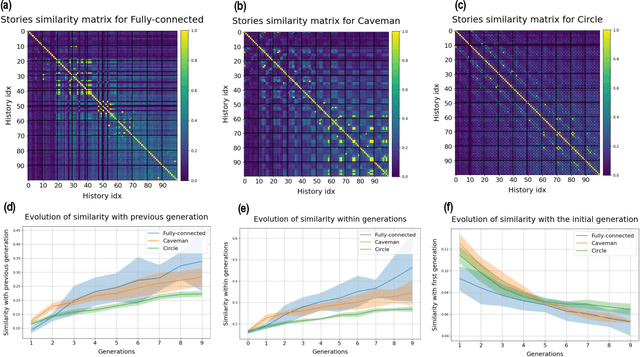

Research in cultural evolution aims at providing causal explanations for the change of culture over time. Over the past decades, this field has generated an important body of knowledge, using experimental, historical, and computational methods. While computational models have been very successful at generating testable hypotheses about the effects of several factors, such as population structure or transmission biases, some phenomena have so far been more complex to capture using agent-based and formal models. This is in particular the case for the effect of the transformations of social information induced by evolved cognitive mechanisms. We here propose that leveraging the capacity of Large Language Models (LLMs) to mimic human behavior may be fruitful to address this gap. On top of being an useful approximation of human cultural dynamics, multi-agents models featuring generative agents are also important to study for their own sake. Indeed, as artificial agents are bound to participate more and more to the evolution of culture, it is crucial to better understand the dynamics of machine-generated cultural evolution. We here present a framework for simulating cultural evolution in populations of LLMs, allowing the manipulation of variables known to be important in cultural evolution, such as network structure, personality, and the way social information is aggregated and transformed. The software we developed for conducting these simulations is open-source and features an intuitive user-interface, which we hope will help to build bridges between the fields of cultural evolution and generative artificial intelligence.