 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Training Loops in LLMs: How training data properties modulate distribution shift in generated data?
Apr 08, 2025Large language models (LLMs) are increasingly contributing to the creation of content on the Internet. This creates a feedback loop as subsequent generations of models will be trained on this generated, synthetic data. This phenomenon is receiving increasing interest, in particular because previous studies have shown that it may lead to distribution shift - models misrepresent and forget the true underlying distributions of human data they are expected to approximate (e.g. resulting in a drastic loss of quality). In this study, we study the impact of human data properties on distribution shift dynamics in iterated training loops. We first confirm that the distribution shift dynamics greatly vary depending on the human data by comparing four datasets (two based on Twitter and two on Reddit). We then test whether data quality may influence the rate of this shift. We find that it does on the twitter, but not on the Reddit datasets. We then focus on a Reddit dataset and conduct a more exhaustive evaluation of a large set of dataset properties. This experiment associated lexical diversity with larger, and semantic diversity with smaller detrimental shifts, suggesting that incorporating text with high lexical (but limited semantic) diversity could exacerbate the degradation of generated text. We then focus on the evolution of political bias, and find that the type of shift observed (bias reduction, amplification or inversion) depends on the political lean of the human (true) distribution. Overall, our work extends the existing literature on the consequences of recursive fine-tuning by showing that this phenomenon is highly dependent on features of the human data on which training occurs. This suggests that different parts of internet (e.g. GitHub, Reddit) may undergo different types of shift depending on their properties.
Stick to your Role! Stability of Personal Values Expressed in Large Language Models
Feb 19, 2024The standard way to study Large Language Models (LLMs) through benchmarks or psychology questionnaires is to provide many different queries from similar minimal contexts (e.g. multiple choice questions). However, due to LLM's highly context-dependent nature, conclusions from such minimal-context evaluations may be little informative about the model's behavior in deployment (where it will be exposed to many new contexts). We argue that context-dependence should be studied as another dimension of LLM comparison alongside others such as cognitive abilities, knowledge, or model size. In this paper, we present a case-study about the stability of value expression over different contexts (simulated conversations on different topics), and as measured using a standard psychology questionnaire (PVQ) and a behavioral downstream task. We consider 19 open-sourced LLMs from five families. Reusing methods from psychology, we study Rank-order stability on the population (interpersonal) level, and Ipsative stability on the individual (intrapersonal) level. We explore two settings: with and without instructing LLMs to simulate particular personalities. We observe similar trends in the stability of models and model families - Mixtral, Mistral and Qwen families being more stable than LLaMa-2 and Phi - over those two settings, two different simulated populations, and even in the downstream behavioral task. When instructed to simulate particular personas, LLMs exhibit low Rank-Order stability, and this stability further diminishes with conversation length. This highlights the need for future research directions on LLMs that can coherently simulate a diversity of personas, as well as how context-dependence can be studied in more thorough and efficient ways. This paper provides a foundational step in that direction, and, to our knowledge, it is the first study of value stability in LLMs.
The SocialAI School: Insights from Developmental Psychology Towards Artificial Socio-Cultural Agents
Jul 15, 2023


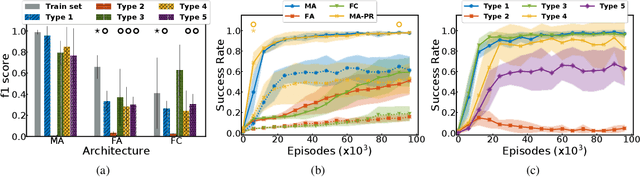
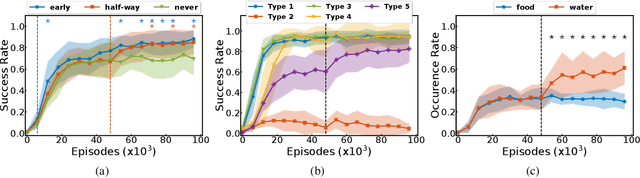
Developmental psychologists have long-established the importance of socio-cognitive abilities in human intelligence. These abilities enable us to enter, participate and benefit from human culture. AI research on social interactive agents mostly concerns the emergence of culture in a multi-agent setting (often without a strong grounding in developmental psychology). We argue that AI research should be informed by psychology and study socio-cognitive abilities enabling to enter a culture too. We discuss the theories of Michael Tomasello and Jerome Bruner to introduce some of their concepts to AI and outline key concepts and socio-cognitive abilities. We present The SocialAI school - a tool including a customizable parameterized uite of procedurally generated environments, which simplifies conducting experiments regarding those concepts. We show examples of such experiments with RL agents and Large Language Models. The main motivation of this work is to engage the AI community around the problem of social intelligence informed by developmental psychology, and to provide a tool to simplify first steps in this direction. Refer to the project website for code and additional information: https://sites.google.com/view/socialai-school.
Large Language Models as Superpositions of Cultural Perspectives
Jul 15, 2023



Large Language Models (LLMs) are often misleadingly recognized as having a personality or a set of values. We argue that an LLM can be seen as a superposition of perspectives with different values and personality traits. LLMs exhibit context-dependent values and personality traits that change based on the induced perspective (as opposed to humans, who tend to have more coherent values and personality traits across contexts). We introduce the concept of perspective controllability, which refers to a model's affordance to adopt various perspectives with differing values and personality traits. In our experiments, we use questionnaires from psychology (PVQ, VSM, IPIP) to study how exhibited values and personality traits change based on different perspectives. Through qualitative experiments, we show that LLMs express different values when those are (implicitly or explicitly) implied in the prompt, and that LLMs express different values even when those are not obviously implied (demonstrating their context-dependent nature). We then conduct quantitative experiments to study the controllability of different models (GPT-4, GPT-3.5, OpenAssistant, StableVicuna, StableLM), the effectiveness of various methods for inducing perspectives, and the smoothness of the models' drivability. We conclude by examining the broader implications of our work and outline a variety of associated scientific questions. The project website is available at https://sites.google.com/view/llm-superpositions .
Language as a Cognitive Tool to Imagine Goals in Curiosity-Driven Exploration
Feb 21, 2020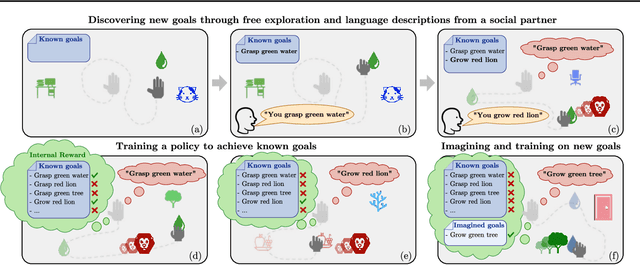
Autonomous reinforcement learning agents must be intrinsically motivated to explore their environment, discover potential goals, represent them and learn how to achieve them. As children do the same, they benefit from exposure to language, using it to formulate goals and imagine new ones as they learn their meaning. In our proposed learning architecture (IMAGINE), the agent freely explores its environment and turns natural language descriptions of interesting interactions from a social partner into potential goals. IMAGINE learns to represent goals by jointly learning a language model and a goal-conditioned reward function. Just like humans, our agent uses language compositionality to generate new goals by composing known ones. Leveraging modular model architectures based on Deep Sets and gated-attention mechanisms, IMAGINE autonomously builds a repertoire of behaviors and shows good zero-shot generalization properties for various types of generalization. When imagining its own goals, the agent leverages zero-shot generalization of the reward function to further train on imagined goals and refine its behavior. We present experiments in a simulated domain where the agent interacts with procedurally generated scenes containing objects of various types and colors, discovers goals, imagines others and learns to achieve them.
User-in-the-loop Adaptive Intent Detection for Instructable Digital Assistant
Jan 16, 2020

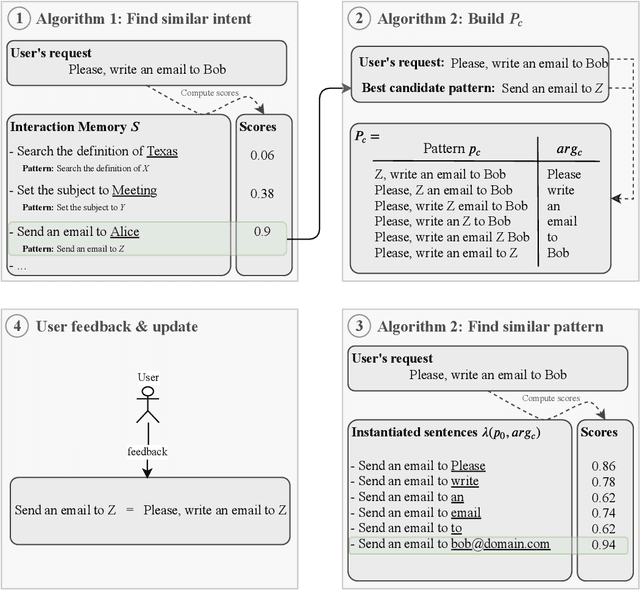

People are becoming increasingly comfortable using Digital Assistants (DAs) to interact with services or connected objects. However, for non-programming users, the available possibilities for customizing their DA are limited and do not include the possibility of teaching the assistant new tasks. To make the most of the potential of DAs, users should be able to customize assistants by instructing them through Natural Language (NL). To provide such functionalities, NL interpretation in traditional assistants should be improved: (1) The intent identification system should be able to recognize new forms of known intents, and to acquire new intents as they are expressed by the user. (2) In order to be adaptive to novel intents, the Natural Language Understanding module should be sample efficient, and should not rely on a pretrained model. Rather, the system should continuously collect the training data as it learns new intents from the user. In this work, we propose AidMe (Adaptive Intent Detection in Multi-Domain Environments), a user-in-the-loop adaptive intent detection framework that allows the assistant to adapt to its user by learning his intents as their interaction progresses. AidMe builds its repertoire of intents and collects data to train a model of semantic similarity evaluation that can discriminate between the learned intents and autonomously discover new forms of known intents. AidMe addresses two major issues - intent learning and user adaptation - for instructable digital assistants. We demonstrate the capabilities of AidMe as a standalone system by comparing it with a one-shot learning system and a pretrained NLU module through simulations of interactions with a user. We also show how AidMe can smoothly integrate to an existing instructable digital assistant.
* To be published as a conference paper in the proceedings of IUI'20
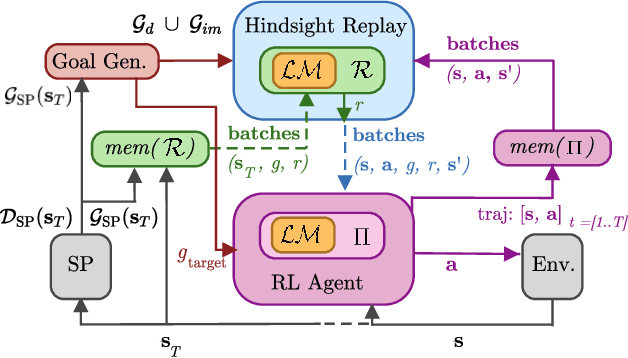
Language Grounding through Social Interactions and Curiosity-Driven Multi-Goal Learning
Nov 08, 2019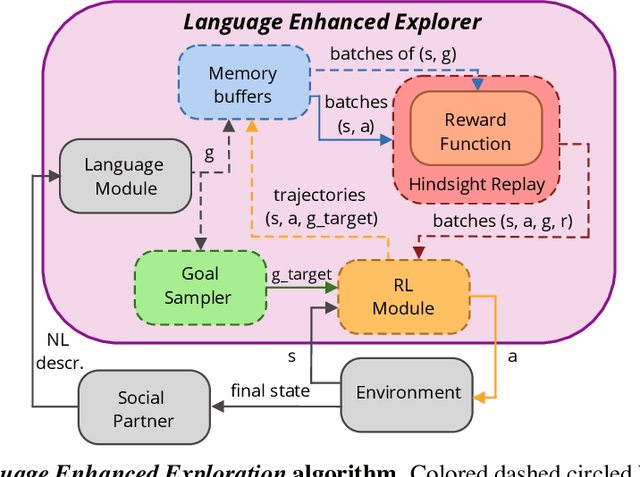
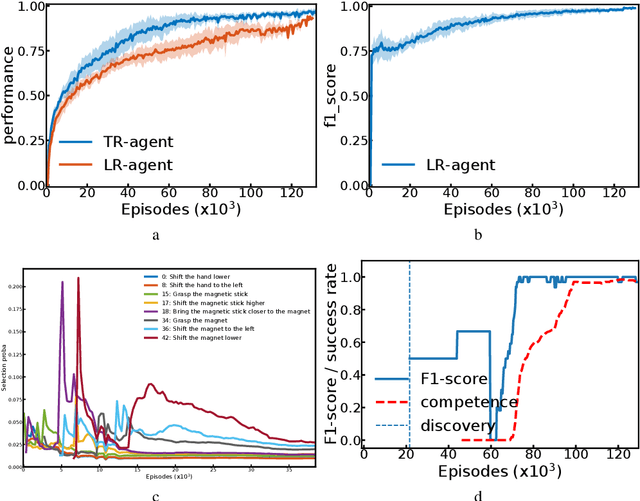
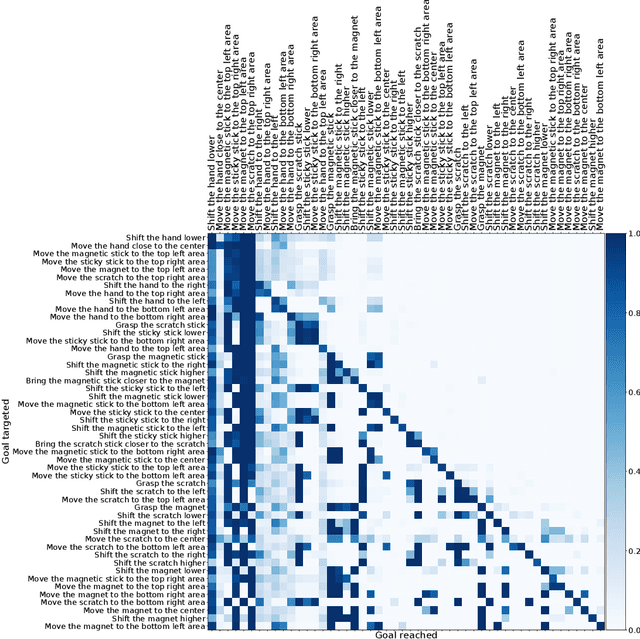
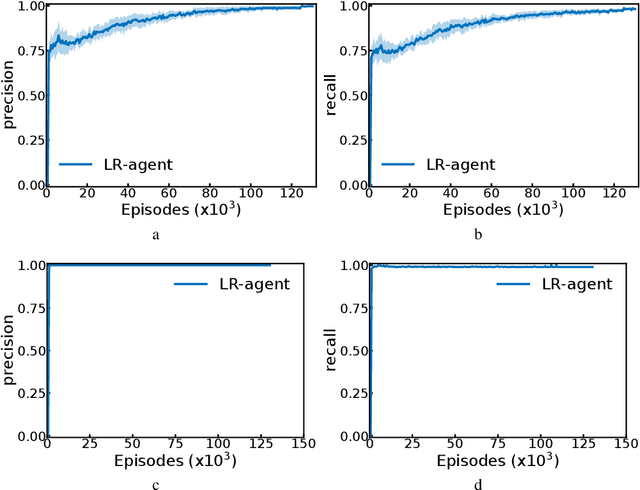
Autonomous reinforcement learning agents, like children, do not have access to predefined goals and reward functions. They must discover potential goals, learn their own reward functions and engage in their own learning trajectory. Children, however, benefit from exposure to language, helping to organize and mediate their thought. We propose LE2 (Language Enhanced Exploration), a learning algorithm leveraging intrinsic motivations and natural language (NL) interactions with a descriptive social partner (SP). Using NL descriptions from the SP, it can learn an NL-conditioned reward function to formulate goals for intrinsically motivated goal exploration and learn a goal-conditioned policy. By exploring, collecting descriptions from the SP and jointly learning the reward function and the policy, the agent grounds NL descriptions into real behavioral goals. From simple goals discovered early to more complex goals discovered by experimenting on simpler ones, our agent autonomously builds its own behavioral repertoire. This naturally occurring curriculum is supplemented by an active learning curriculum resulting from the agent's intrinsic motivations. Experiments are presented with a simulated robotic arm that interacts with several objects including tools.
DAC-h3: A Proactive Robot Cognitive Architecture to Acquire and Express Knowledge About the World and the Self
Sep 18, 2017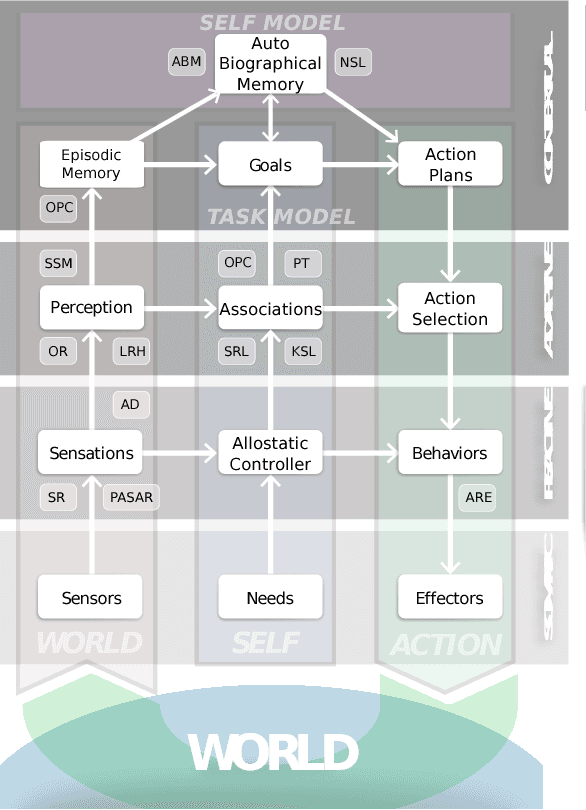
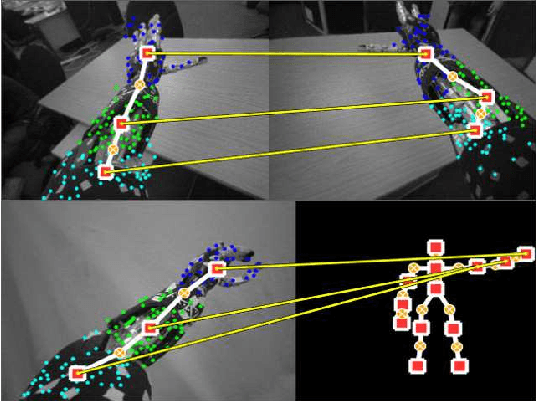


This paper introduces a cognitive architecture for a humanoid robot to engage in a proactive, mixed-initiative exploration and manipulation of its environment, where the initiative can originate from both the human and the robot. The framework, based on a biologically-grounded theory of the brain and mind, integrates a reactive interaction engine, a number of state-of-the-art perceptual and motor learning algorithms, as well as planning abilities and an autobiographical memory. The architecture as a whole drives the robot behavior to solve the symbol grounding problem, acquire language capabilities, execute goal-oriented behavior, and express a verbal narrative of its own experience in the world. We validate our approach in human-robot interaction experiments with the iCub humanoid robot, showing that the proposed cognitive architecture can be applied in real time within a realistic scenario and that it can be used with naive users.
* Preprint version; final version available at http://ieeexplore.ieee.org/ IEEE Transactions on Cognitive and Developmental Systems (Accepted) DOI: 10.1109/TCDS.2017.2754143