 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadowless Projection Mapping for Tabletop Workspaces with Synthetic Aperture Projector
Mar 12, 2026Projection mapping (PM) enables augmented reality (AR) experiences without requiring users to wear head-mounted displays and supports multi-user interaction. It is regarded as a promising technology for a variety of applications in which users interact with content superimposed onto augmented objects in tabletop workspaces, including remote collaboration, healthcare, industrial design, urban planning, artwork creation, and office work. However, conventional PM systems often suffer from projection shadows when users occlude the light path. Prior approaches employing multiple distributed projectors can compensate for occlusion, but suffer from latency due to computational processing, degrading the user experience. In this research, we introduce a synthetic-aperture PM system that uses a significantly larger number of projectors, arranged densely in the environment, to achieve delay-free, shadowless projection for tabletop workspaces without requiring computational compensation. To address spatial resolution degradation caused by subpixel misalignment among overlaid projections, we develop and validate an offline blur compensation method whose computation time remains independent of the number of projectors. Furthermore, we demonstrate that our shadowless PM plays a critical role in achieving a fundamental goal of PM: altering material properties without evoking projection-like impression. Specifically, we define this perceptual impression as ``sense of projection (SoP)'' and establish a PM design framework to minimize the SoP based on user studies.
MAME: Multidimensional Adaptive Metamer Exploration with Human Perceptual Feedback
Mar 17, 2025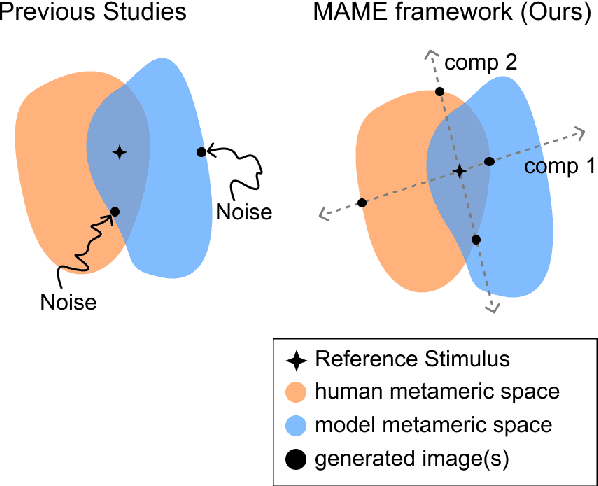
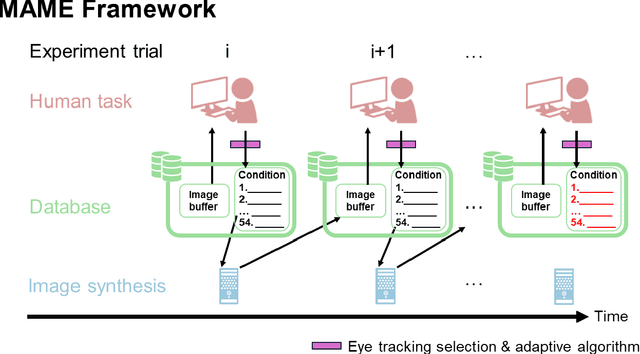
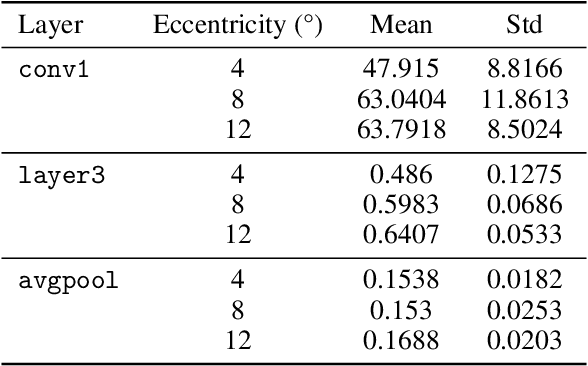
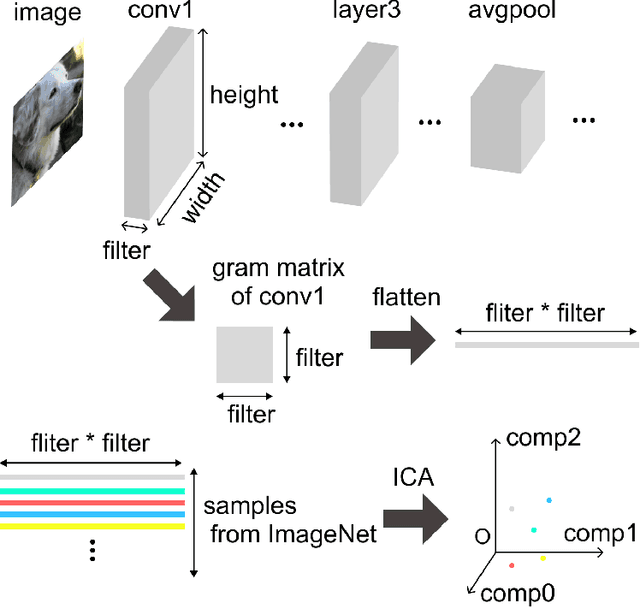
Alignment between human brain networks and artificial models is actively studied in machine learning and neuroscience. A widely adopted approach to explore their functional alignment is to identify metamers for both humans and models. Metamers refer to input stimuli that are physically different but equivalent within a given system. If a model's metameric space completely matched the human metameric space, the model would achieve functional alignment with humans. However, conventional methods lack direct ways to search for human metamers. Instead, researchers first develop biologically inspired models and then infer about human metamers indirectly by testing whether model metamers also appear as metamers to humans. Here, we propose the Multidimensional Adaptive Metamer Exploration (MAME) framework, enabling direct high-dimensional exploration of human metameric space. MAME leverages online image generation guided by human perceptual feedback. Specifically, it modulates reference images across multiple dimensions by leveraging hierarchical responses from convolutional neural networks (CNNs). Generated images are presented to participants whose perceptual discriminability is assessed in a behavioral task. Based on participants' responses, subsequent image generation parameters are adaptively updated online. Using our MAME framework, we successfully measured a human metameric space of over fifty dimensions within a single experiment. Experimental results showed that human discrimination sensitivity was lower for metameric images based on low-level features compared to high-level features, which image contrast metrics could not explain. The finding suggests that the model computes low-level information not essential for human perception. Our framework has the potential to contribute to developing interpretable AI and understanding of brain function in neuroscience.
BrainCodec: Neural fMRI codec for the decoding of cognitive brain states
Oct 06, 2024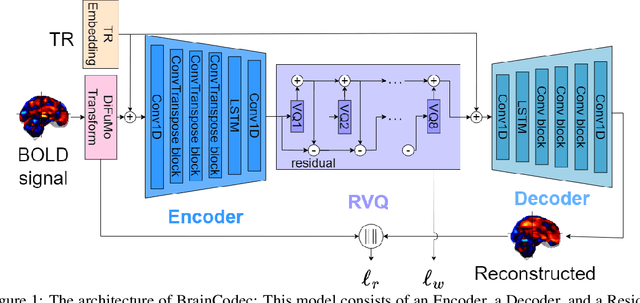
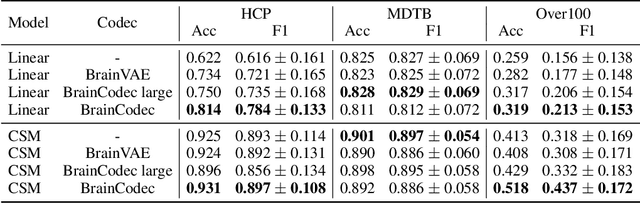


Recently, leveraging big data in deep learning has led to significant performance improvements, as confirmed in applications like mental state decoding using fMRI data. However, fMRI datasets remain relatively small in scale, and the inherent issue of low signal-to-noise ratios (SNR) in fMRI data further exacerbates these challenges. To address this, we apply compression techniques as a preprocessing step for fMRI data. We propose BrainCodec, a novel fMRI codec inspired by the neural audio codec. We evaluated BrainCodec's compression capability in mental state decoding, demonstrating further improvements over previous methods. Furthermore, we analyzed the latent representations obtained through BrainCodec, elucidating the similarities and differences between task and resting state fMRI, highlighting the interpretability of BrainCodec. Additionally, we demonstrated that fMRI reconstructions using BrainCodec can enhance the visibility of brain activity by achieving higher SNR, suggesting its potential as a novel denoising method. Our study shows that BrainCodec not only enhances performance over previous methods but also offers new analytical possibilities for neuroscience. Our codes, dataset, and model weights are available at https://github.com/amano-k-lab/BrainCodec.
Stick to your Role! Stability of Personal Values Expressed in Large Language Models
Feb 19, 2024The standard way to study Large Language Models (LLMs) through benchmarks or psychology questionnaires is to provide many different queries from similar minimal contexts (e.g. multiple choice questions). However, due to LLM's highly context-dependent nature, conclusions from such minimal-context evaluations may be little informative about the model's behavior in deployment (where it will be exposed to many new contexts). We argue that context-dependence should be studied as another dimension of LLM comparison alongside others such as cognitive abilities, knowledge, or model size. In this paper, we present a case-study about the stability of value expression over different contexts (simulated conversations on different topics), and as measured using a standard psychology questionnaire (PVQ) and a behavioral downstream task. We consider 19 open-sourced LLMs from five families. Reusing methods from psychology, we study Rank-order stability on the population (interpersonal) level, and Ipsative stability on the individual (intrapersonal) level. We explore two settings: with and without instructing LLMs to simulate particular personalities. We observe similar trends in the stability of models and model families - Mixtral, Mistral and Qwen families being more stable than LLaMa-2 and Phi - over those two settings, two different simulated populations, and even in the downstream behavioral task. When instructed to simulate particular personas, LLMs exhibit low Rank-Order stability, and this stability further diminishes with conversation length. This highlights the need for future research directions on LLMs that can coherently simulate a diversity of personas, as well as how context-dependence can be studied in more thorough and efficient ways. This paper provides a foundational step in that direction, and, to our knowledge, it is the first study of value stability in LLMs.
Large Language Models as Superpositions of Cultural Perspectives
Jul 15, 2023



Large Language Models (LLMs) are often misleadingly recognized as having a personality or a set of values. We argue that an LLM can be seen as a superposition of perspectives with different values and personality traits. LLMs exhibit context-dependent values and personality traits that change based on the induced perspective (as opposed to humans, who tend to have more coherent values and personality traits across contexts). We introduce the concept of perspective controllability, which refers to a model's affordance to adopt various perspectives with differing values and personality traits. In our experiments, we use questionnaires from psychology (PVQ, VSM, IPIP) to study how exhibited values and personality traits change based on different perspectives. Through qualitative experiments, we show that LLMs express different values when those are (implicitly or explicitly) implied in the prompt, and that LLMs express different values even when those are not obviously implied (demonstrating their context-dependent nature). We then conduct quantitative experiments to study the controllability of different models (GPT-4, GPT-3.5, OpenAssistant, StableVicuna, StableLM), the effectiveness of various methods for inducing perspectives, and the smoothness of the models' drivability. We conclude by examining the broader implications of our work and outline a variety of associated scientific questions. The project website is available at https://sites.google.com/view/llm-superpositions .
Evaluating language-biased image classification based on semantic representations
Jan 26, 2022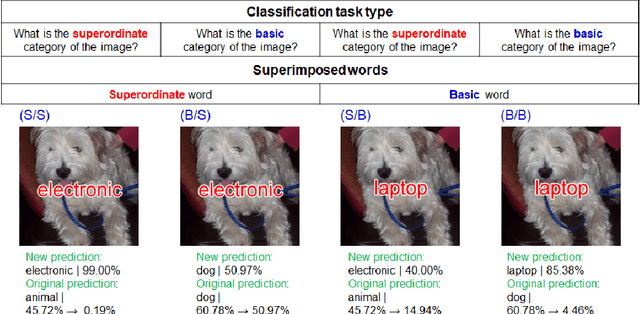

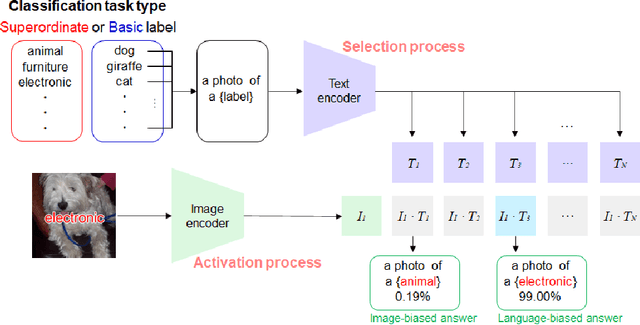

Humans show language-biased image recognition for a word-embedded image, known as picture-word interference. Such interference depends on hierarchical semantic categories and reflects that human language processing highly interacts with visual processing. Similar to humans, recent artificial models jointly trained on texts and images, e.g., OpenAI CLIP, show language-biased image classification. Exploring whether the bias leads to interferences similar to those observed in humans can contribute to understanding how much the model acquires hierarchical semantic representations from joint learning of language and vision. The present study introduces methodological tools from the cognitive science literature to assess the biases of artificial models. Specifically, we introduce a benchmark task to test whether words superimposed on images can distort the image classification across different category levels and, if it can, whether the perturbation is due to the shared semantic representation between language and vision. Our dataset is a set of word-embedded images and consists of a mixture of natural image datasets and hierarchical word labels with superordinate/basic category levels. Using this benchmark test, we evaluate the CLIP model. We show that presenting words distorts the image classification by the model across different category levels, but the effect does not depend on the semantic relationship between images and embedded words. This suggests that the semantic word representation in the CLIP visual processing is not shared with the image representation, although the word representation strongly dominates for word-embedded images.