 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpedition & Expansion: Leveraging Semantic Representations for Goal-Directed Exploration in Continuous Cellular Automata
Sep 04, 2025Discovering diverse visual patterns in continuous cellular automata (CA) is challenging due to the vastness and redundancy of high-dimensional behavioral spaces. Traditional exploration methods like Novelty Search (NS) expand locally by mutating known novel solutions but often plateau when local novelty is exhausted, failing to reach distant, unexplored regions. We introduce Expedition and Expansion (E&E), a hybrid strategy where exploration alternates between local novelty-driven expansions and goal-directed expeditions. During expeditions, E&E leverages a Vision-Language Model (VLM) to generate linguistic goals--descriptions of interesting but hypothetical patterns that drive exploration toward uncharted regions. By operating in semantic spaces that align with human perception, E&E both evaluates novelty and generates goals in conceptually meaningful ways, enhancing the interpretability and relevance of discovered behaviors. Tested on Flow Lenia, a continuous CA known for its rich, emergent behaviors, E&E consistently uncovers more diverse solutions than existing exploration methods. A genealogical analysis further reveals that solutions originating from expeditions disproportionately influence long-term exploration, unlocking new behavioral niches that serve as stepping stones for subsequent search. These findings highlight E&E's capacity to break through local novelty boundaries and explore behavioral landscapes in human-aligned, interpretable ways, offering a promising template for open-ended exploration in artificial life and beyond.
MAGELLAN: Metacognitive predictions of learning progress guide autotelic LLM agents in large goal spaces
Feb 12, 2025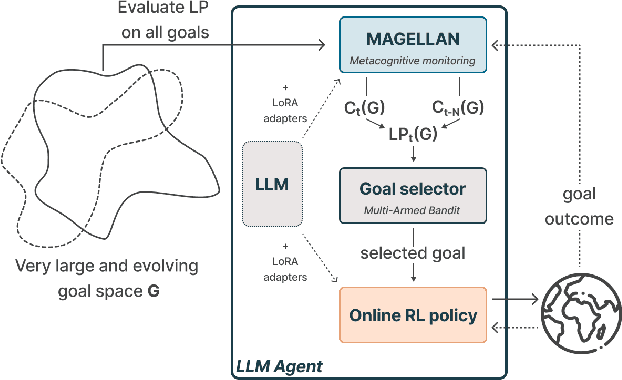
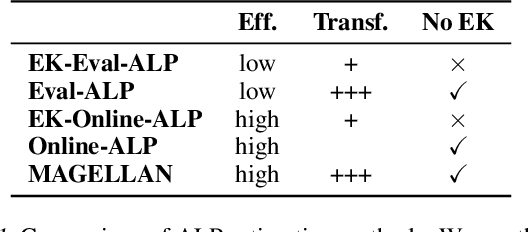
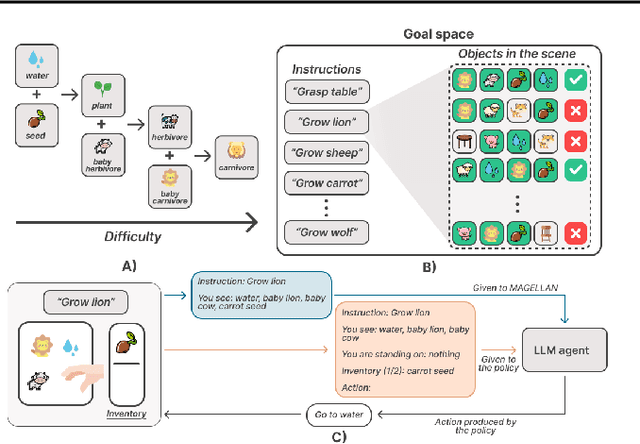
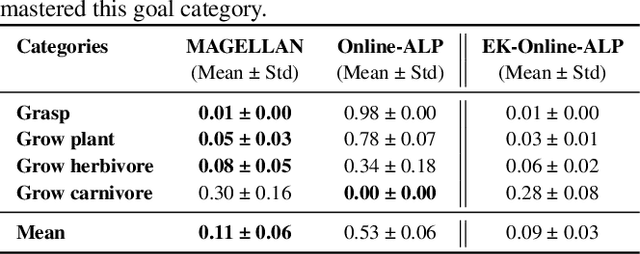
Open-ended learning agents must efficiently prioritize goals in vast possibility spaces, focusing on those that maximize learning progress (LP). When such autotelic exploration is achieved by LLM agents trained with online RL in high-dimensional and evolving goal spaces, a key challenge for LP prediction is modeling one's own competence, a form of metacognitive monitoring. Traditional approaches either require extensive sampling or rely on brittle expert-defined goal groupings. We introduce MAGELLAN, a metacognitive framework that lets LLM agents learn to predict their competence and LP online. By capturing semantic relationships between goals, MAGELLAN enables sample-efficient LP estimation and dynamic adaptation to evolving goal spaces through generalization. In an interactive learning environment, we show that MAGELLAN improves LP prediction efficiency and goal prioritization, being the only method allowing the agent to fully master a large and evolving goal space. These results demonstrate how augmenting LLM agents with a metacognitive ability for LP predictions can effectively scale curriculum learning to open-ended goal spaces.
When LLMs Play the Telephone Game: Cumulative Changes and Attractors in Iterated Cultural Transmissions
Jul 05, 2024



As large language models (LLMs) start interacting with each other and generating an increasing amount of text online, it becomes crucial to better understand how information is transformed as it passes from one LLM to the next. While significant research has examined individual LLM behaviors, existing studies have largely overlooked the collective behaviors and information distortions arising from iterated LLM interactions. Small biases, negligible at the single output level, risk being amplified in iterated interactions, potentially leading the content to evolve towards attractor states. In a series of telephone game experiments, we apply a transmission chain design borrowed from the human cultural evolution literature: LLM agents iteratively receive, produce, and transmit texts from the previous to the next agent in the chain. By tracking the evolution of text toxicity, positivity, difficulty, and length across transmission chains, we uncover the existence of biases and attractors, and study their dependence on the initial text, the instructions, language model, and model size. For instance, we find that more open-ended instructions lead to stronger attraction effects compared to more constrained tasks. We also find that different text properties display different sensitivity to attraction effects, with toxicity leading to stronger attractors than length. These findings highlight the importance of accounting for multi-step transmission dynamics and represent a first step towards a more comprehensive understanding of LLM cultural dynamics.
ACES: Generating Diverse Programming Puzzles with Autotelic Language Models and Semantic Descriptors
Oct 25, 2023



Finding and selecting new and interesting problems to solve is at the heart of curiosity, science and innovation. We here study automated problem generation in the context of the open-ended space of python programming puzzles. Existing generative models often aim at modeling a reference distribution without any explicit diversity optimization. Other methods explicitly optimizing for diversity do so either in limited hand-coded representation spaces or in uninterpretable learned embedding spaces that may not align with human perceptions of interesting variations. With ACES (Autotelic Code Exploration via Semantic descriptors), we introduce a new autotelic generation method that leverages semantic descriptors produced by a large language model (LLM) to directly optimize for interesting diversity, as well as few-shot-based generation. Each puzzle is labeled along 10 dimensions, each capturing a programming skill required to solve it. ACES generates and pursues novel and feasible goals to explore that abstract semantic space, slowly discovering a diversity of solvable programming puzzles in any given run. Across a set of experiments, we show that ACES discovers a richer diversity of puzzles than existing diversity-maximizing algorithms as measured across a range of diversity metrics. We further study whether and in which conditions this diversity can translate into the successful training of puzzle solving models.
Large Language Models as Superpositions of Cultural Perspectives
Jul 15, 2023



Large Language Models (LLMs) are often misleadingly recognized as having a personality or a set of values. We argue that an LLM can be seen as a superposition of perspectives with different values and personality traits. LLMs exhibit context-dependent values and personality traits that change based on the induced perspective (as opposed to humans, who tend to have more coherent values and personality traits across contexts). We introduce the concept of perspective controllability, which refers to a model's affordance to adopt various perspectives with differing values and personality traits. In our experiments, we use questionnaires from psychology (PVQ, VSM, IPIP) to study how exhibited values and personality traits change based on different perspectives. Through qualitative experiments, we show that LLMs express different values when those are (implicitly or explicitly) implied in the prompt, and that LLMs express different values even when those are not obviously implied (demonstrating their context-dependent nature). We then conduct quantitative experiments to study the controllability of different models (GPT-4, GPT-3.5, OpenAssistant, StableVicuna, StableLM), the effectiveness of various methods for inducing perspectives, and the smoothness of the models' drivability. We conclude by examining the broader implications of our work and outline a variety of associated scientific questions. The project website is available at https://sites.google.com/view/llm-superpositions .
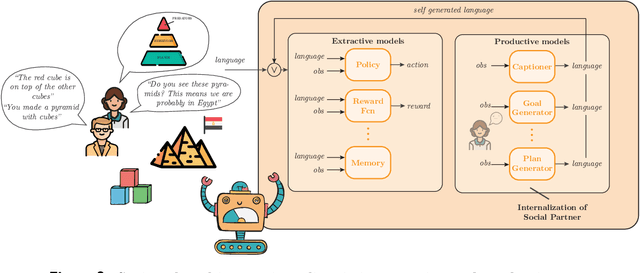
Augmenting Autotelic Agents with Large Language Models
May 21, 2023Humans learn to master open-ended repertoires of skills by imagining and practicing their own goals. This autotelic learning process, literally the pursuit of self-generated (auto) goals (telos), becomes more and more open-ended as the goals become more diverse, abstract and creative. The resulting exploration of the space of possible skills is supported by an inter-individual exploration: goal representations are culturally evolved and transmitted across individuals, in particular using language. Current artificial agents mostly rely on predefined goal representations corresponding to goal spaces that are either bounded (e.g. list of instructions), or unbounded (e.g. the space of possible visual inputs) but are rarely endowed with the ability to reshape their goal representations, to form new abstractions or to imagine creative goals. In this paper, we introduce a language model augmented autotelic agent (LMA3) that leverages a pretrained language model (LM) to support the representation, generation and learning of diverse, abstract, human-relevant goals. The LM is used as an imperfect model of human cultural transmission; an attempt to capture aspects of humans' common-sense, intuitive physics and overall interests. Specifically, it supports three key components of the autotelic architecture: 1)~a relabeler that describes the goals achieved in the agent's trajectories, 2)~a goal generator that suggests new high-level goals along with their decomposition into subgoals the agent already masters, and 3)~reward functions for each of these goals. Without relying on any hand-coded goal representations, reward functions or curriculum, we show that LMA3 agents learn to master a large diversity of skills in a task-agnostic text-based environment.
Guiding Pretraining in Reinforcement Learning with Large Language Models
Feb 13, 2023



Reinforcement learning algorithms typically struggle in the absence of a dense, well-shaped reward function. Intrinsically motivated exploration methods address this limitation by rewarding agents for visiting novel states or transitions, but these methods offer limited benefits in large environments where most discovered novelty is irrelevant for downstream tasks. We describe a method that uses background knowledge from text corpora to shape exploration. This method, called ELLM (Exploring with LLMs) rewards an agent for achieving goals suggested by a language model prompted with a description of the agent's current state. By leveraging large-scale language model pretraining, ELLM guides agents toward human-meaningful and plausibly useful behaviors without requiring a human in the loop. We evaluate ELLM in the Crafter game environment and the Housekeep robotic simulator, showing that ELLM-trained agents have better coverage of common-sense behaviors during pretraining and usually match or improve performance on a range of downstream tasks.
Vygotskian Autotelic Artificial Intelligence: Language and Culture Internalization for Human-Like AI
Jun 02, 2022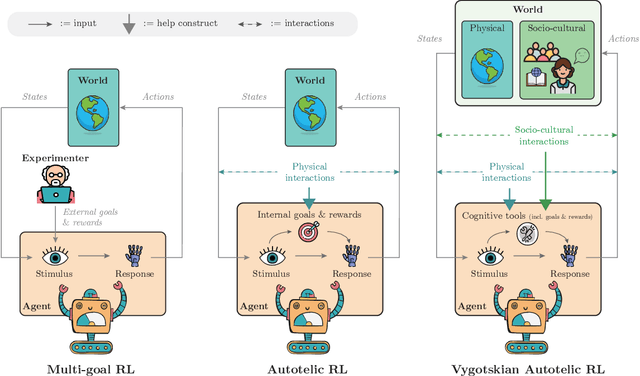
Building autonomous artificial agents able to grow open-ended repertoires of skills is one of the fundamental goals of AI. To that end, a promising developmental approach recommends the design of intrinsically motivated agents that learn new skills by generating and pursuing their own goals - autotelic agents. However, existing algorithms still show serious limitations in terms of goal diversity, exploration, generalization or skill composition. This perspective calls for the immersion of autotelic agents into rich socio-cultural worlds. We focus on language especially, and how its structure and content may support the development of new cognitive functions in artificial agents, just like it does in humans. Indeed, most of our skills could not be learned in isolation. Formal education teaches us to reason systematically, books teach us history, and YouTube might teach us how to cook. Crucially, our values, traditions, norms and most of our goals are cultural in essence. This knowledge, and some argue, some of our cognitive functions such as abstraction, compositional imagination or relational thinking, are formed through linguistic and cultural interactions. Inspired by the work of Vygotsky, we suggest the design of Vygotskian autotelic agents able to interact with others and, more importantly, able to internalize these interactions to transform them into cognitive tools supporting the development of new cognitive functions. This perspective paper proposes a new AI paradigm in the quest for artificial lifelong skill discovery. It justifies the approach by uncovering examples of new artificial cognitive functions emerging from interactions between language and embodiment in recent works at the intersection of deep reinforcement learning and natural language processing. Looking forward, it highlights future opportunities and challenges for Vygotskian Autotelic AI research.
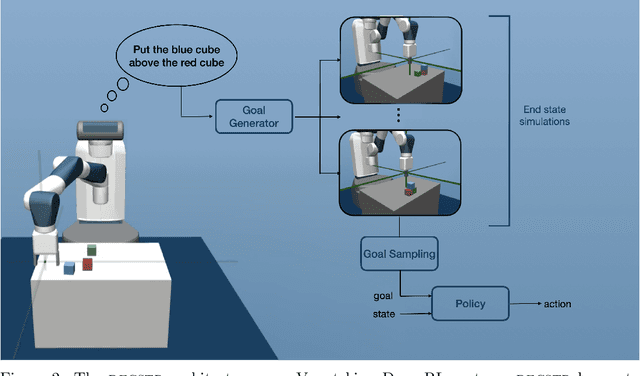
Help Me Explore: Minimal Social Interventions for Graph-Based Autotelic Agents
Feb 10, 2022In the quest for autonomous agents learning open-ended repertoires of skills, most works take a Piagetian perspective: learning trajectories are the results of interactions between developmental agents and their physical environment. The Vygotskian perspective, on the other hand, emphasizes the centrality of the socio-cultural environment: higher cognitive functions emerge from transmissions of socio-cultural processes internalized by the agent. This paper argues that both perspectives could be coupled within the learning of autotelic agents to foster their skill acquisition. To this end, we make two contributions: 1) a novel social interaction protocol called Help Me Explore (HME), where autotelic agents can benefit from both individual and socially guided exploration. In social episodes, a social partner suggests goals at the frontier of the learning agent knowledge. In autotelic episodes, agents can either learn to master their own discovered goals or autonomously rehearse failed social goals; 2) GANGSTR, a graph-based autotelic agent for manipulation domains capable of decomposing goals into sequences of intermediate sub-goals. We show that when learning within HME, GANGSTR overcomes its individual learning limits by mastering the most complex configurations (e.g. stacks of 5 blocks) with only few social interventions.
Towards Teachable Autonomous Agents
May 25, 2021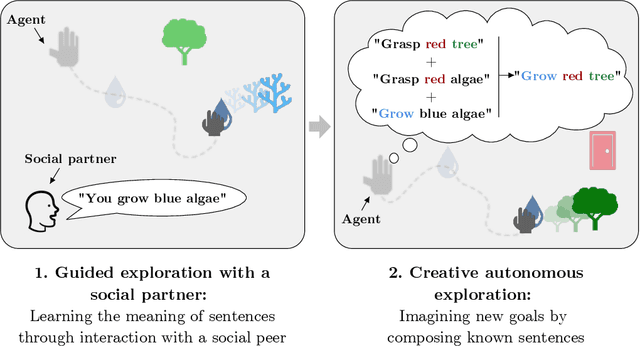
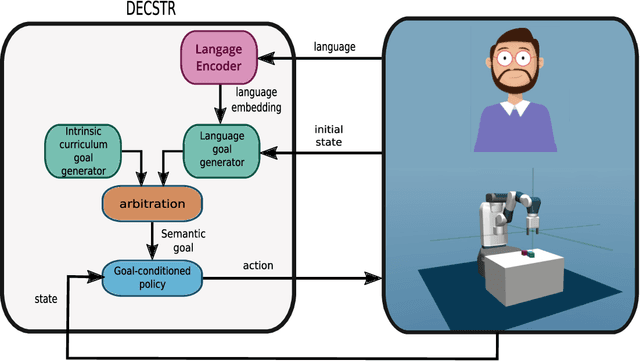
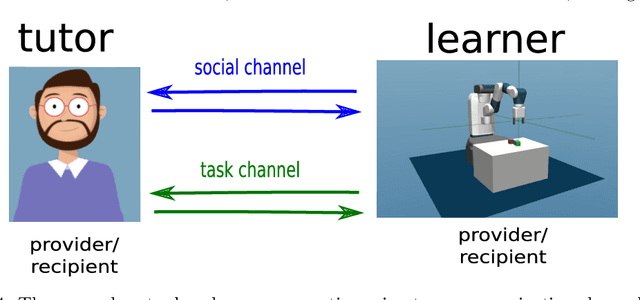
Autonomous discovery and direct instruction are two extreme sources of learning in children, but educational sciences have shown that intermediate approaches such as assisted discovery or guided play resulted in better acquisition of skills. When turning to Artificial Intelligence, the above dichotomy is translated into the distinction between autonomous agents which learn in isolation and interactive learning agents which can be taught by social partners but generally lack autonomy. In between should stand teachable autonomous agents: agents learning from both internal and teaching signals to benefit from the higher efficiency of assisted discovery. Such agents could learn on their own in the real world, but non-expert users could drive their learning behavior towards their expectations. More fundamentally, combining both capabilities might also be a key step towards general intelligence. In this paper we elucidate obstacles along this research line. First, we build on a seminal work of Bruner to extract relevant features of the assisted discovery processes. Second, we describe current research on autotelic agents, i.e. agents equipped with forms of intrinsic motivations that enable them to represent, self-generate and pursue their own goals. We argue that autotelic capabilities are paving the way towards teachable and autonomous agents. Finally, we adopt a social learning perspective on tutoring interactions and we highlight some components that are currently missing to autotelic agents before they can be taught by ordinary people using natural pedagogy, and we provide a list of specific research questions that emerge from this perspective.