 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERAKLES: Hierarchical Skill Compilation for Open-ended LLM Agents
Aug 20, 2025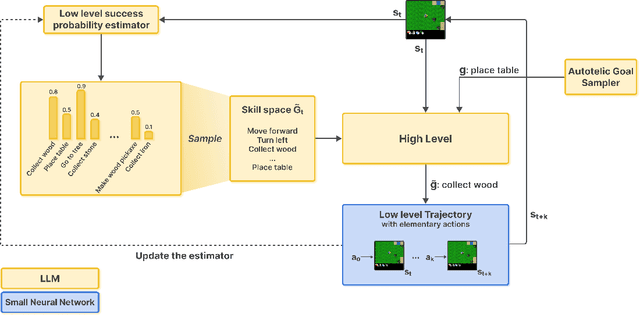
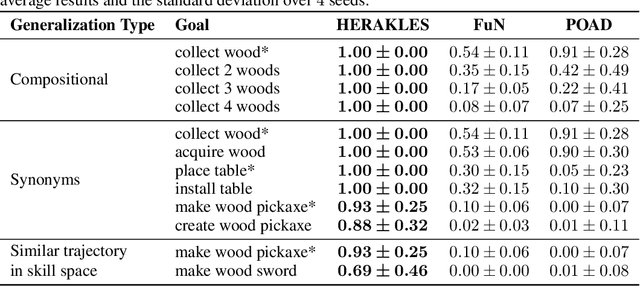
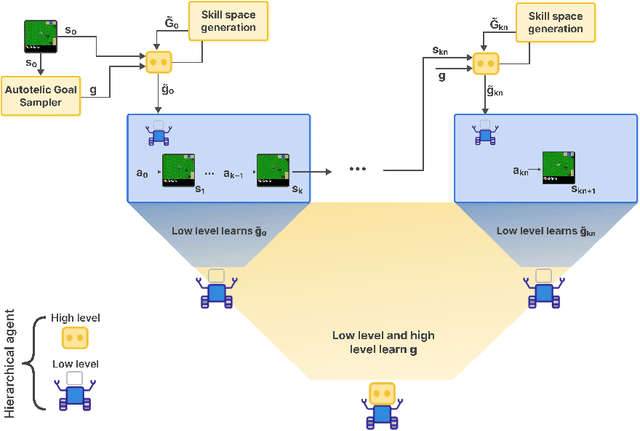

Open-ended AI agents need to be able to learn efficiently goals of increasing complexity, abstraction and heterogeneity over their lifetime. Beyond sampling efficiently their own goals, autotelic agents specifically need to be able to keep the growing complexity of goals under control, limiting the associated growth in sample and computational complexity. To adress this challenge, recent approaches have leveraged hierarchical reinforcement learning (HRL) and language, capitalizing on its compositional and combinatorial generalization capabilities to acquire temporally extended reusable behaviours. Existing approaches use expert defined spaces of subgoals over which they instantiate a hierarchy, and often assume pre-trained associated low-level policies. Such designs are inadequate in open-ended scenarios, where goal spaces naturally diversify across a broad spectrum of difficulties. We introduce HERAKLES, a framework that enables a two-level hierarchical autotelic agent to continuously compile mastered goals into the low-level policy, executed by a small, fast neural network, dynamically expanding the set of subgoals available to the high-level policy. We train a Large Language Model (LLM) to serve as the high-level controller, exploiting its strengths in goal decomposition and generalization to operate effectively over this evolving subgoal space. We evaluate HERAKLES in the open-ended Crafter environment and show that it scales effectively with goal complexity, improves sample efficiency through skill compilation, and enables the agent to adapt robustly to novel challenges over time.
MAGELLAN: Metacognitive predictions of learning progress guide autotelic LLM agents in large goal spaces
Feb 12, 2025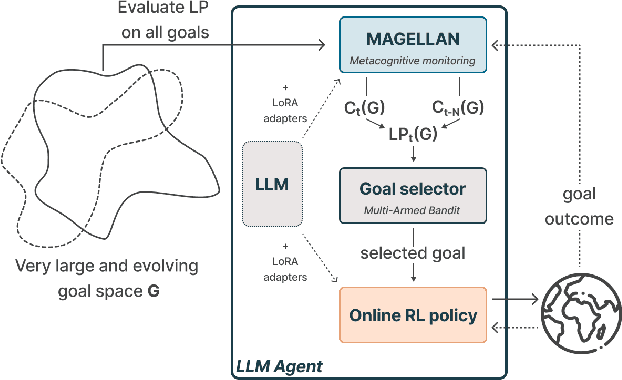
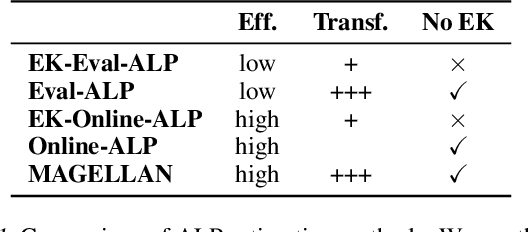
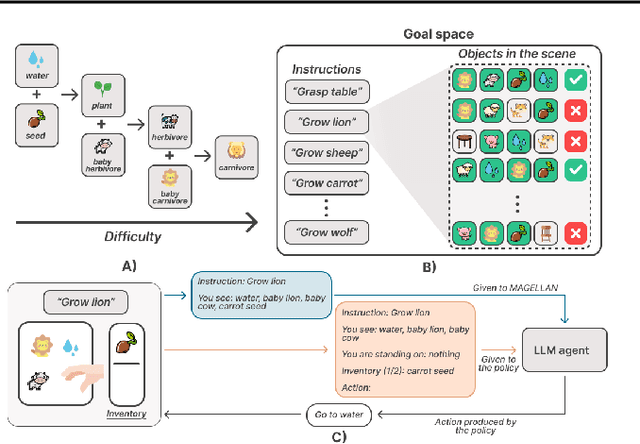
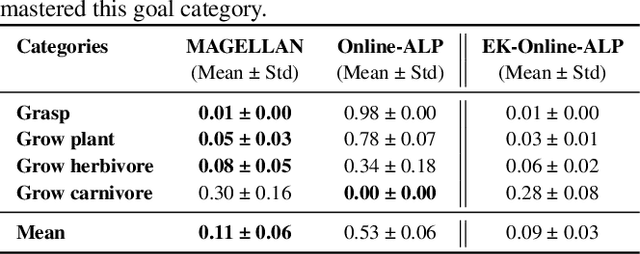
Open-ended learning agents must efficiently prioritize goals in vast possibility spaces, focusing on those that maximize learning progress (LP). When such autotelic exploration is achieved by LLM agents trained with online RL in high-dimensional and evolving goal spaces, a key challenge for LP prediction is modeling one's own competence, a form of metacognitive monitoring. Traditional approaches either require extensive sampling or rely on brittle expert-defined goal groupings. We introduce MAGELLAN, a metacognitive framework that lets LLM agents learn to predict their competence and LP online. By capturing semantic relationships between goals, MAGELLAN enables sample-efficient LP estimation and dynamic adaptation to evolving goal spaces through generalization. In an interactive learning environment, we show that MAGELLAN improves LP prediction efficiency and goal prioritization, being the only method allowing the agent to fully master a large and evolving goal space. These results demonstrate how augmenting LLM agents with a metacognitive ability for LP predictions can effectively scale curriculum learning to open-ended goal spaces.
Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent
Feb 15, 2024
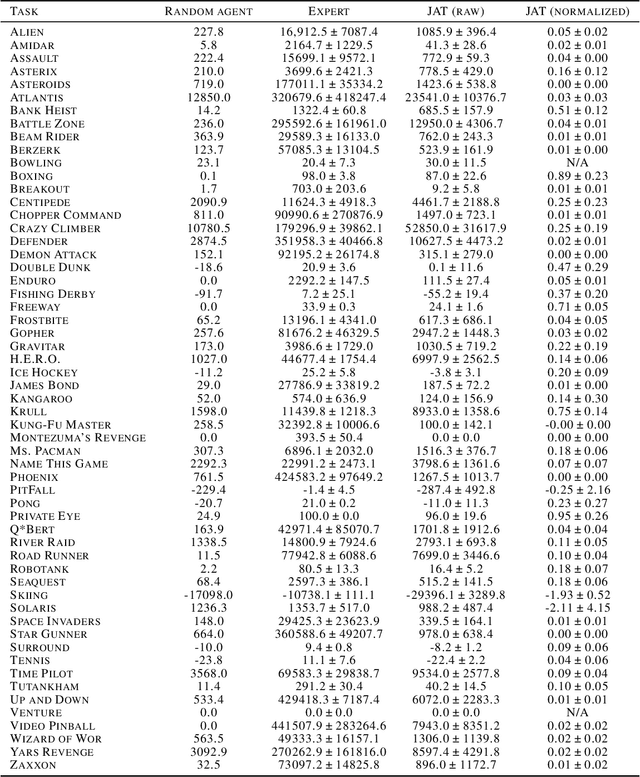


The search for a general model that can operate seamlessly across multiple domains remains a key goal in machine learning research. The prevailing methodology in Reinforcement Learning (RL) typically limits models to a single task within a unimodal framework, a limitation that contrasts with the broader vision of a versatile, multi-domain model. In this paper, we present Jack of All Trades (JAT), a transformer-based model with a unique design optimized for handling sequential decision-making tasks and multimodal data types. The JAT model demonstrates its robust capabilities and versatility by achieving strong performance on very different RL benchmarks, along with promising results on Computer Vision (CV) and Natural Language Processing (NLP) tasks, all using a single set of weights. The JAT model marks a significant step towards more general, cross-domain AI model design, and notably, it is the first model of its kind to be fully open-sourced (see https://huggingface.co/jat-project/jat), including a pioneering general-purpose dataset.
Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
Feb 06, 2023



Recent works successfully leveraged Large Language Models' (LLM) abilities to capture abstract knowledge about world's physics to solve decision-making problems. Yet, the alignment between LLMs' knowledge and the environment can be wrong and limit functional competence due to lack of grounding. In this paper, we study an approach to achieve this alignment through functional grounding: we consider an agent using an LLM as a policy that is progressively updated as the agent interacts with the environment, leveraging online Reinforcement Learning to improve its performance to solve goals. Using an interactive textual environment designed to study higher-level forms of functional grounding, and a set of spatial and navigation tasks, we study several scientific questions: 1) Can LLMs boost sample efficiency for online learning of various RL tasks? 2) How can it boost different forms of generalization? 3) What is the impact of online learning? We study these questions by functionally grounding several variants (size, architecture) of FLAN-T5.
TeachMyAgent: a Benchmark for Automatic Curriculum Learning in Deep RL
Mar 17, 2021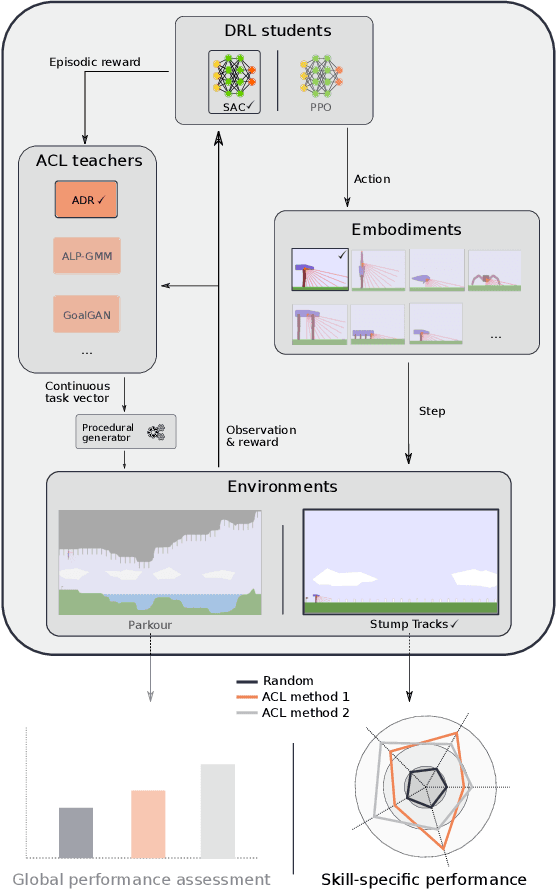

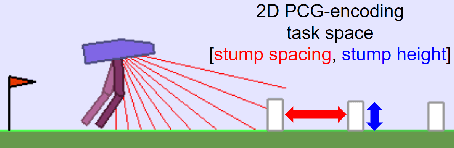
Training autonomous agents able to generalize to multiple tasks is a key target of Deep Reinforcement Learning (DRL) research. In parallel to improving DRL algorithms themselves, Automatic Curriculum Learning (ACL) study how teacher algorithms can train DRL agents more efficiently by adapting task selection to their evolving abilities. While multiple standard benchmarks exist to compare DRL agents, there is currently no such thing for ACL algorithms. Thus, comparing existing approaches is difficult, as too many experimental parameters differ from paper to paper. In this work, we identify several key challenges faced by ACL algorithms. Based on these, we present TeachMyAgent (TA), a benchmark of current ACL algorithms leveraging procedural task generation. It includes 1) challenge-specific unit-tests using variants of a procedural Box2D bipedal walker environment, and 2) a new procedural Parkour environment combining most ACL challenges, making it ideal for global performance assessment. We then use TeachMyAgent to conduct a comparative study of representative existing approaches, showcasing the competitiveness of some ACL algorithms that do not use expert knowledge. We also show that the Parkour environment remains an open problem. We open-source our environments, all studied ACL algorithms (collected from open-source code or re-implemented), and DRL students in a Python package available at https://github.com/flowersteam/TeachMyAgent.
Meta Automatic Curriculum Learning
Nov 16, 2020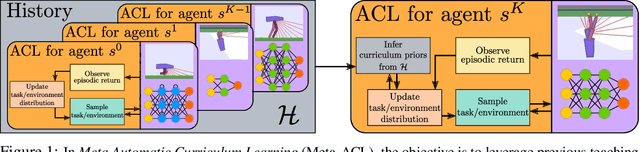

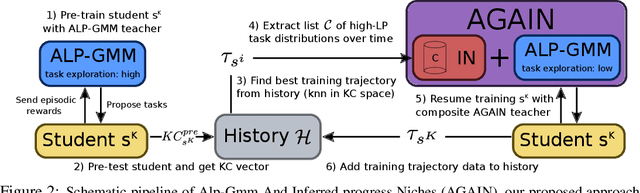
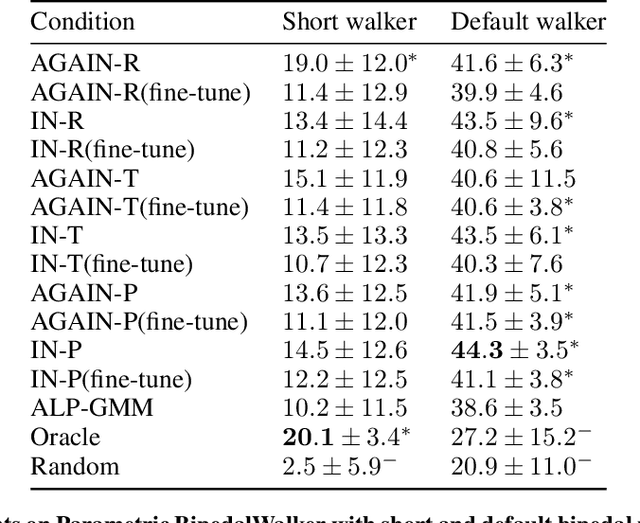
A major challenge in the Deep RL (DRL) community is to train agents able to generalize their control policy over situations never seen in training. Training on diverse tasks has been identified as a key ingredient for good generalization, which pushed researchers towards using rich procedural task generation systems controlled through complex continuous parameter spaces. In such complex task spaces, it is essential to rely on some form of Automatic Curriculum Learning (ACL) to adapt the task sampling distribution to a given learning agent, instead of randomly sampling tasks, as many could end up being either trivial or unfeasible. Since it is hard to get prior knowledge on such task spaces, many ACL algorithms explore the task space to detect progress niches over time, a costly tabula-rasa process that needs to be performed for each new learning agents, although they might have similarities in their capabilities profiles. To address this limitation, we introduce the concept of Meta-ACL, and formalize it in the context of black-box RL learners, i.e. algorithms seeking to generalize curriculum generation to an (unknown) distribution of learners. In this work, we present AGAIN, a first instantiation of Meta-ACL, and showcase its benefits for curriculum generation over classical ACL in multiple simulated environments including procedurally generated parkour environments with learners of varying morphologies. Videos and code are available at https://sites.google.com/view/meta-acl .
Deep Recurrent Q-Learning vs Deep Q-Learning on a simple Partially Observable Markov Decision Process with Minecraft
Apr 11, 2019

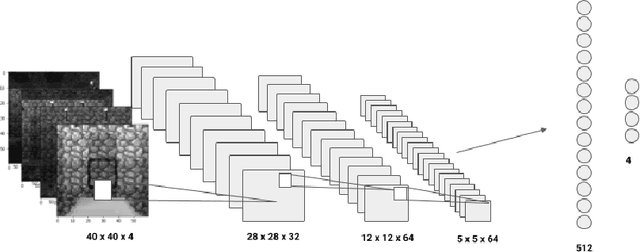

Deep Q-Learning has been successfully applied to a wide variety of tasks in the past several years. However, the architecture of the vanilla Deep Q-Network is not suited to deal with partially observable environments such as 3D video games. For this, recurrent layers have been added to the Deep Q-Network in order to allow it to handle past dependencies. We here use Minecraft for its customization advantages and design two very simple missions that can be frames as Partially Observable Markov Decision Process. We compare on these missions the Deep Q-Network and the Deep Recurrent Q-Network in order to see if the latter, which is trickier and longer to train, is always the best architecture when the agent has to deal with partial observability.