 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJack of All Trades, Master of Some, a Multi-Purpose Transformer Agent
Feb 15, 2024
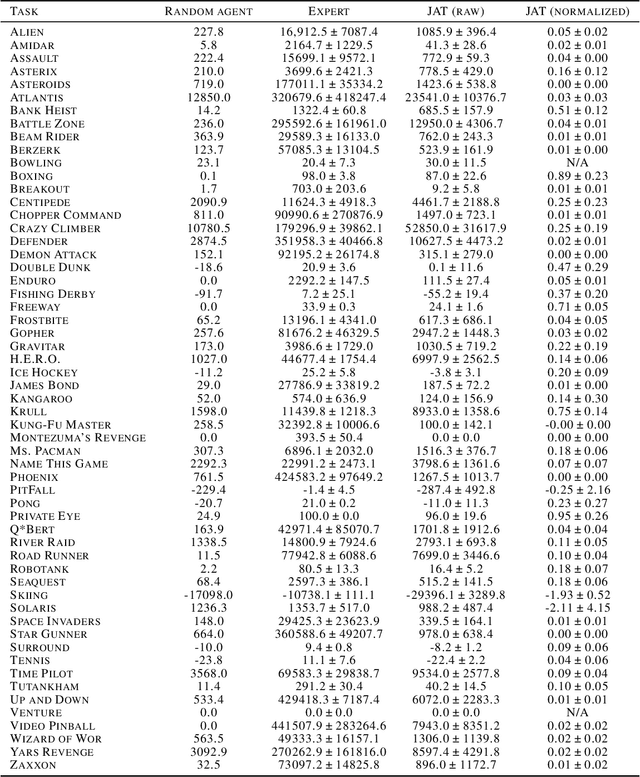


The search for a general model that can operate seamlessly across multiple domains remains a key goal in machine learning research. The prevailing methodology in Reinforcement Learning (RL) typically limits models to a single task within a unimodal framework, a limitation that contrasts with the broader vision of a versatile, multi-domain model. In this paper, we present Jack of All Trades (JAT), a transformer-based model with a unique design optimized for handling sequential decision-making tasks and multimodal data types. The JAT model demonstrates its robust capabilities and versatility by achieving strong performance on very different RL benchmarks, along with promising results on Computer Vision (CV) and Natural Language Processing (NLP) tasks, all using a single set of weights. The JAT model marks a significant step towards more general, cross-domain AI model design, and notably, it is the first model of its kind to be fully open-sourced (see https://huggingface.co/jat-project/jat), including a pioneering general-purpose dataset.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Cell-Free Latent Go-Explore
Aug 31, 2022
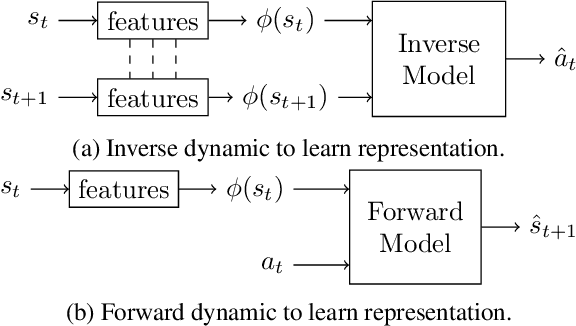

In this paper, we introduce Latent Go-Explore (LGE), a simple and general approach based on the Go-Explore paradigm for exploration in reinforcement learning (RL). Go-Explore was initially introduced with a strong domain knowledge constraint for partitioning the state space into cells. However, in most real-world scenarios, drawing domain knowledge from raw observations is complex and tedious. If the cell partitioning is not informative enough, Go-Explore can completely fail to explore the environment. We argue that the Go-Explore approach can be generalized to any environment without domain knowledge and without cells by exploiting a learned latent representation. Thus, we show that LGE can be flexibly combined with any strategy for learning a latent representation. We show that LGE, although simpler than Go-Explore, is more robust and outperforms all state-of-the-art algorithms in terms of pure exploration on multiple hard-exploration environments. The LGE implementation is available as open-source at https://github.com/qgallouedec/lge.
Multi-Goal Reinforcement Learning environments for simulated Franka Emika Panda robot
Jun 25, 2021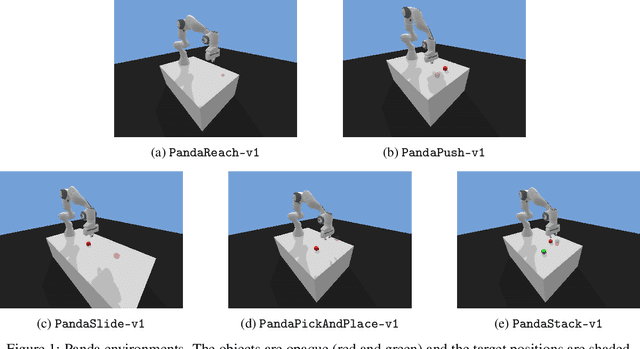

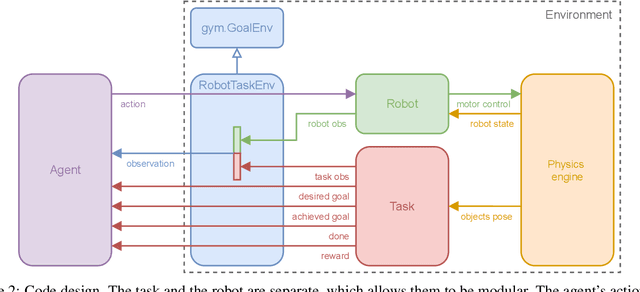
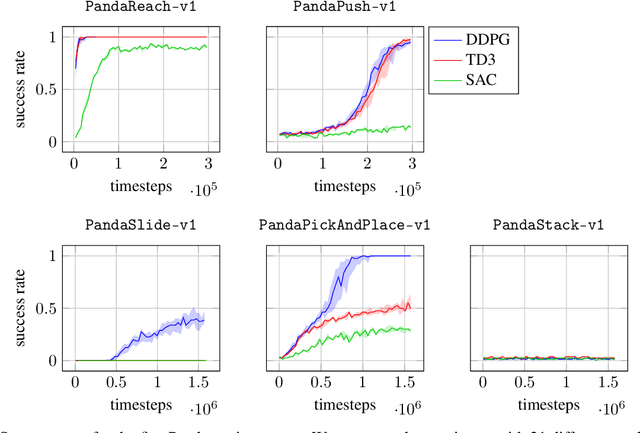
This technical report presents panda-gym, a set Reinforcement Learning (RL) environments for the Franka Emika Panda robot integrated with OpenAI Gym. Five tasks are included: reach, push, slide, pick & place and stack. They all follow a Multi-Goal RL framework, allowing to use goal-oriented RL algorithms. To foster open-research, we chose to use the open-source physics engine PyBullet. The implementation chosen for this package allows to define very easily new tasks or new robots. This report also presents a baseline of results obtained with state-of-the-art model-free off-policy algorithms. panda-gym is open-source at https://github.com/qgallouedec/panda-gym.