 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
DextrAH-G: Pixels-to-Action Dexterous Arm-Hand Grasping with Geometric Fabrics
Jul 02, 2024

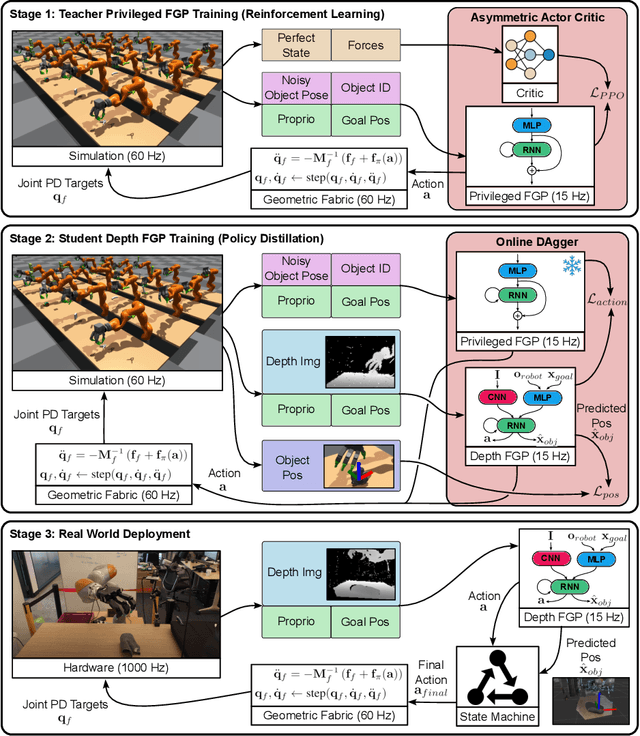
A pivotal challenge in robotics is achieving fast, safe, and robust dexterous grasping across a diverse range of objects, an important goal within industrial applications. However, existing methods often have very limited speed, dexterity, and generality, along with limited or no hardware safety guarantees. In this work, we introduce DextrAH-G, a depth-based dexterous grasping policy trained entirely in simulation that combines reinforcement learning, geometric fabrics, and teacher-student distillation. We address key challenges in joint arm-hand policy learning, such as high-dimensional observation and action spaces, the sim2real gap, collision avoidance, and hardware constraints. DextrAH-G enables a 23 motor arm-hand robot to safely and continuously grasp and transport a large variety of objects at high speed using multi-modal inputs including depth images, allowing generalization across object geometry. Videos at https://sites.google.com/view/dextrah-g.
Geometric Fabrics: a Safe Guiding Medium for Policy Learning
May 03, 2024


Robotics policies are always subjected to complex, second order dynamics that entangle their actions with resulting states. In reinforcement learning (RL) contexts, policies have the burden of deciphering these complicated interactions over massive amounts of experience and complex reward functions to learn how to accomplish tasks. Moreover, policies typically issue actions directly to controllers like Operational Space Control (OSC) or joint PD control, which induces straightline motion towards these action targets in task or joint space. However, straightline motion in these spaces for the most part do not capture the rich, nonlinear behavior our robots need to exhibit, shifting the burden of discovering these behaviors more completely to the agent. Unlike these simpler controllers, geometric fabrics capture a much richer and desirable set of behaviors via artificial, second order dynamics grounded in nonlinear geometry. These artificial dynamics shift the uncontrolled dynamics of a robot via an appropriate control law to form behavioral dynamics. Behavioral dynamics unlock a new action space and safe, guiding behavior over which RL policies are trained. Behavioral dynamics enable bang-bang-like RL policy actions that are still safe for real robots, simplify reward engineering, and help sequence real-world, high-performance policies. We describe the framework more generally and create a specific instantiation for the problem of dexterous, in-hand reorientation of a cube by a highly actuated robot hand.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
DexPBT: Scaling up Dexterous Manipulation for Hand-Arm Systems with Population Based Training
May 20, 2023



In this work, we propose algorithms and methods that enable learning dexterous object manipulation using simulated one- or two-armed robots equipped with multi-fingered hand end-effectors. Using a parallel GPU-accelerated physics simulator (Isaac Gym), we implement challenging tasks for these robots, including regrasping, grasp-and-throw, and object reorientation. To solve these problems we introduce a decentralized Population-Based Training (PBT) algorithm that allows us to massively amplify the exploration capabilities of deep reinforcement learning. We find that this method significantly outperforms regular end-to-end learning and is able to discover robust control policies in challenging tasks. Video demonstrations of learned behaviors and the code can be found at https://sites.google.com/view/dexpbt
DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Oct 25, 2022Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. Videos of the resulting policy and supplementary information, including experiments and demos, can be found at \url{https://dextreme.org/}
EnvPool: A Highly Parallel Reinforcement Learning Environment Execution Engine
Jun 21, 2022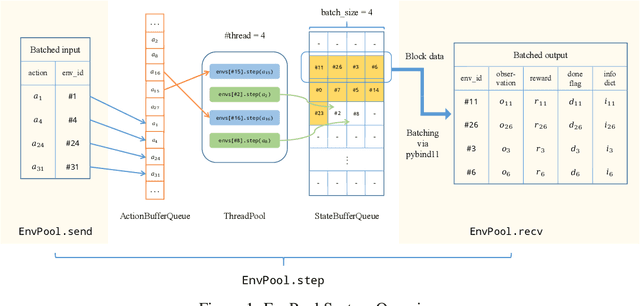
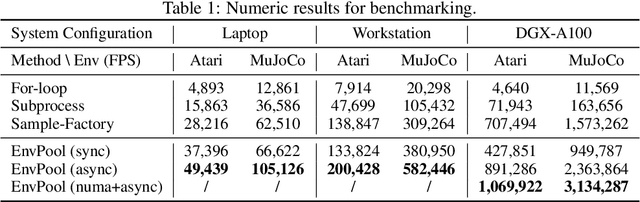
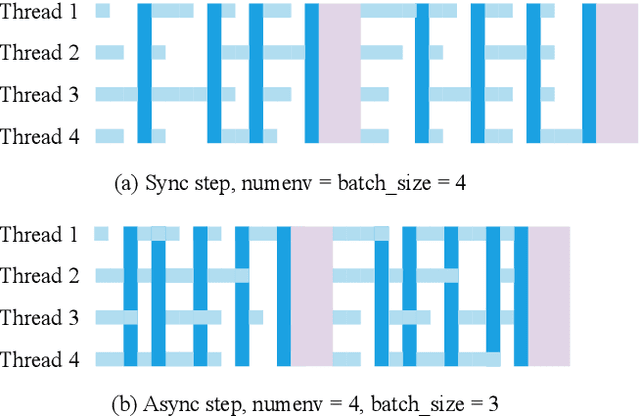
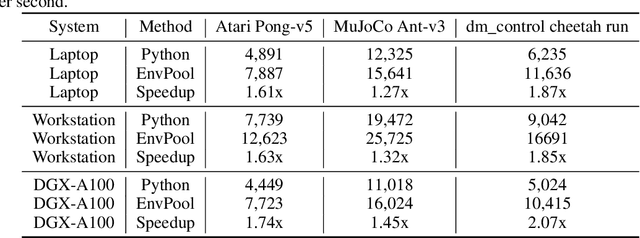
There has been significant progress in developing reinforcement learning (RL) training systems. Past works such as IMPALA, Apex, Seed RL, Sample Factory, and others aim to improve the system's overall throughput. In this paper, we try to address a common bottleneck in the RL training system, i.e., parallel environment execution, which is often the slowest part of the whole system but receives little attention. With a curated design for paralleling RL environments, we have improved the RL environment simulation speed across different hardware setups, ranging from a laptop, and a modest workstation, to a high-end machine like NVIDIA DGX-A100. On a high-end machine, EnvPool achieves 1 million frames per second for the environment execution on Atari environments and 3 million frames per second on MuJoCo environments. When running on a laptop, the speed of EnvPool is 2.8 times of the Python subprocess. Moreover, great compatibility with existing RL training libraries has been demonstrated in the open-sourced community, including CleanRL, rl_games, DeepMind Acme, etc. Finally, EnvPool allows researchers to iterate their ideas at a much faster pace and has the great potential to become the de facto RL environment execution engine. Example runs show that it takes only 5 minutes to train Atari Pong and MuJoCo Ant, both on a laptop. EnvPool has already been open-sourced at https://github.com/sail-sg/envpool.
Accelerated Policy Learning with Parallel Differentiable Simulation
Apr 14, 2022
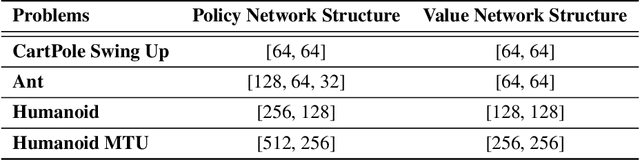
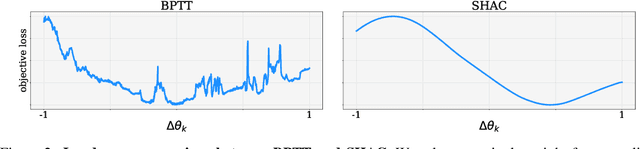
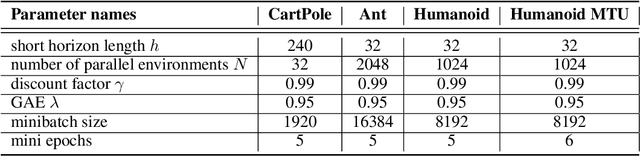
Deep reinforcement learning can generate complex control policies, but requires large amounts of training data to work effectively. Recent work has attempted to address this issue by leveraging differentiable simulators. However, inherent problems such as local minima and exploding/vanishing numerical gradients prevent these methods from being generally applied to control tasks with complex contact-rich dynamics, such as humanoid locomotion in classical RL benchmarks. In this work we present a high-performance differentiable simulator and a new policy learning algorithm (SHAC) that can effectively leverage simulation gradients, even in the presence of non-smoothness. Our learning algorithm alleviates problems with local minima through a smooth critic function, avoids vanishing/exploding gradients through a truncated learning window, and allows many physical environments to be run in parallel. We evaluate our method on classical RL control tasks, and show substantial improvements in sample efficiency and wall-clock time over state-of-the-art RL and differentiable simulation-based algorithms. In addition, we demonstrate the scalability of our method by applying it to the challenging high-dimensional problem of muscle-actuated locomotion with a large action space, achieving a greater than 17x reduction in training time over the best-performing established RL algorithm.
Reinforcement Learning in Factored Action Spaces using Tensor Decompositions
Oct 27, 2021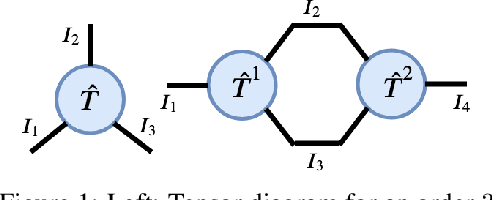
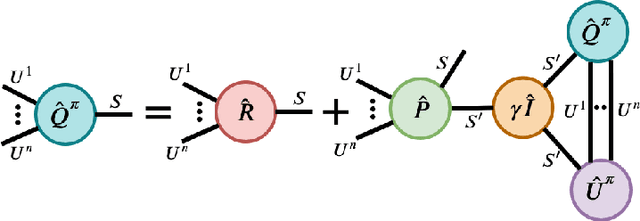
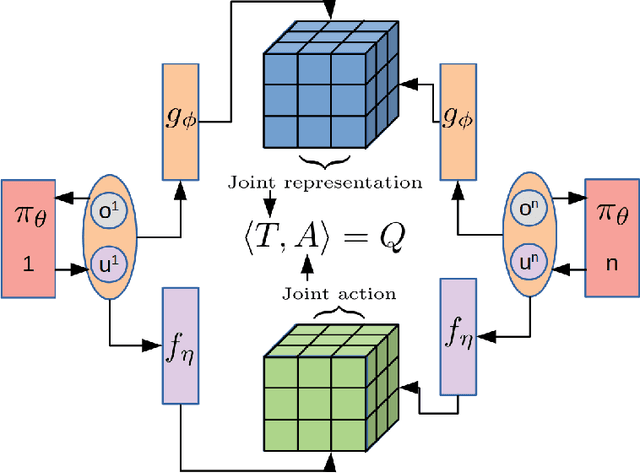
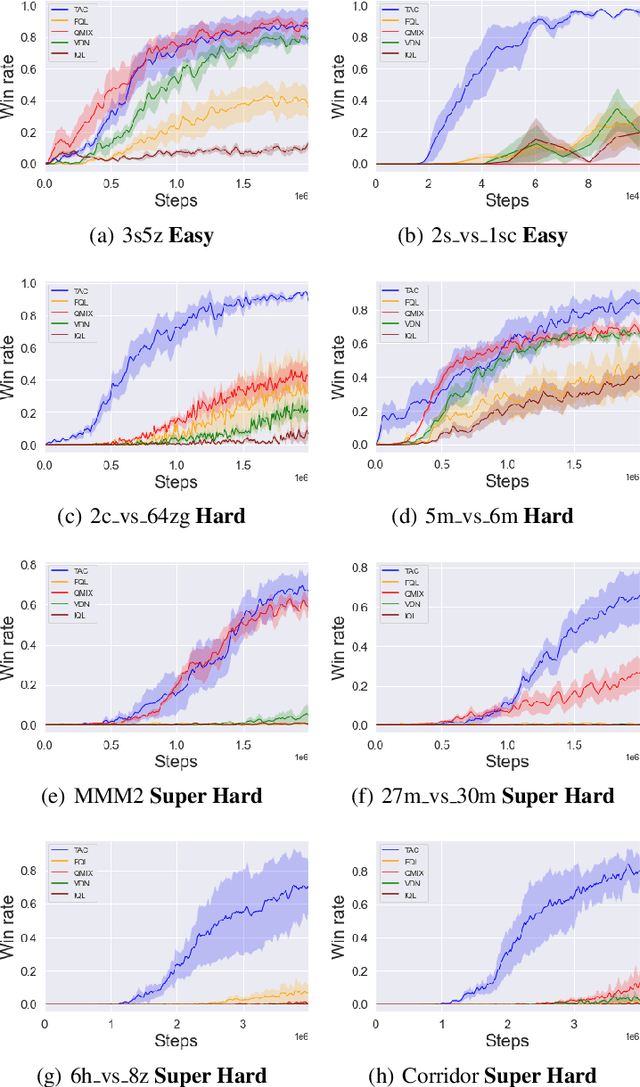
We present an extended abstract for the previously published work TESSERACT [Mahajan et al., 2021], which proposes a novel solution for Reinforcement Learning (RL) in large, factored action spaces using tensor decompositions. The goal of this abstract is twofold: (1) To garner greater interest amongst the tensor research community for creating methods and analysis for approximate RL, (2) To elucidate the generalised setting of factored action spaces where tensor decompositions can be used. We use cooperative multi-agent reinforcement learning scenario as the exemplary setting where the action space is naturally factored across agents and learning becomes intractable without resorting to approximation on the underlying hypothesis space for candidate solutions.
OSCAR: Data-Driven Operational Space Control for Adaptive and Robust Robot Manipulation
Oct 02, 2021
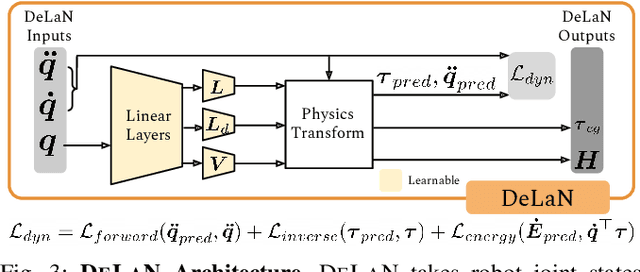
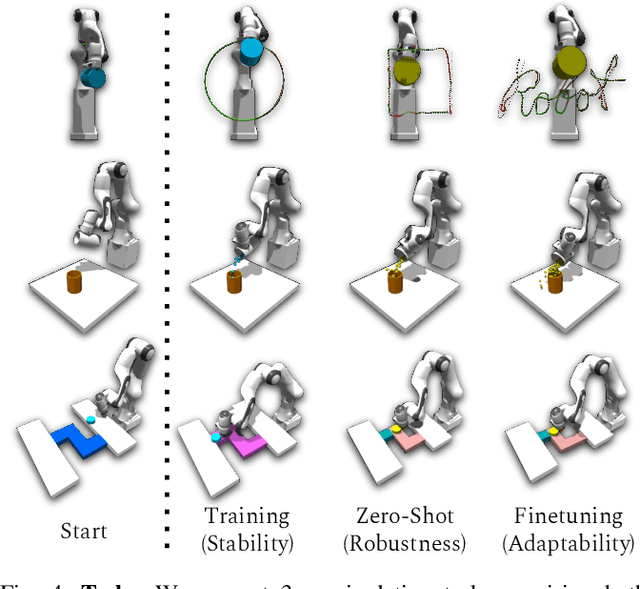

Learning performant robot manipulation policies can be challenging due to high-dimensional continuous actions and complex physics-based dynamics. This can be alleviated through intelligent choice of action space. Operational Space Control (OSC) has been used as an effective task-space controller for manipulation. Nonetheless, its strength depends on the underlying modeling fidelity, and is prone to failure when there are modeling errors. In this work, we propose OSC for Adaptation and Robustness (OSCAR), a data-driven variant of OSC that compensates for modeling errors by inferring relevant dynamics parameters from online trajectories. OSCAR decomposes dynamics learning into task-agnostic and task-specific phases, decoupling the dynamics dependencies of the robot and the extrinsics due to its environment. This structure enables robust zero-shot performance under out-of-distribution and rapid adaptation to significant domain shifts through additional finetuning. We evaluate our method on a variety of simulated manipulation problems, and find substantial improvements over an array of controller baselines. For more results and information, please visit https://cremebrule.github.io/oscar-web/.