 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Low-Cost Teleoperation: Augmenting GELLO with Force
Jul 18, 2025

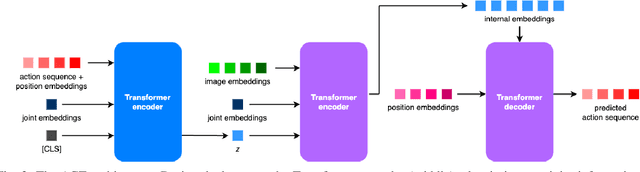

In this work we extend the low-cost GELLO teleoperation system, initially designed for joint position control, with additional force information. Our first extension is to implement force feedback, allowing users to feel resistance when interacting with the environment. Our second extension is to add force information into the data collection process and training of imitation learning models. We validate our additions by implementing these on a GELLO system with a Franka Panda arm as the follower robot, performing a user study, and comparing the performance of policies trained with and without force information on a range of simulated and real dexterous manipulation tasks. Qualitatively, users with robotics experience preferred our controller, and the addition of force inputs improved task success on the majority of tasks.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



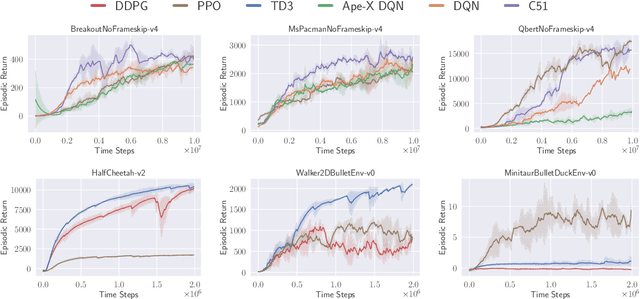
In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
A2C is a special case of PPO
May 18, 2022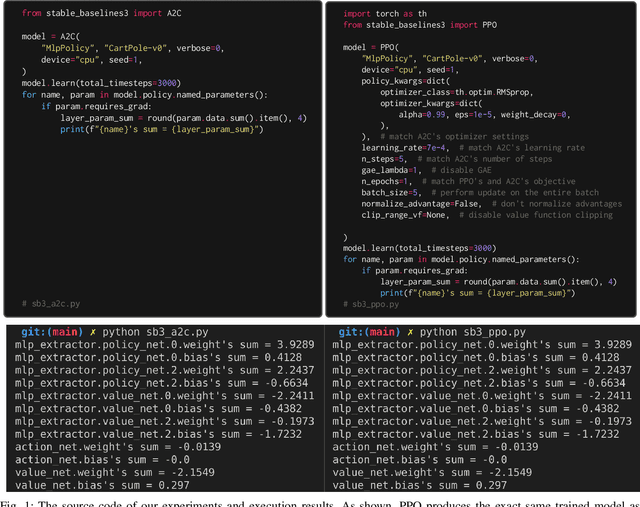
Advantage Actor-critic (A2C) and Proximal Policy Optimization (PPO) are popular deep reinforcement learning algorithms used for game AI in recent years. A common understanding is that A2C and PPO are separate algorithms because PPO's clipped objective appears significantly different than A2C's objective. In this paper, however, we show A2C is a special case of PPO. We present theoretical justifications and pseudocode analysis to demonstrate why. To validate our claim, we conduct an empirical experiment using \texttt{Stable-baselines3}, showing A2C and PPO produce the \textit{exact} same models when other settings are controlled.
CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms
Nov 16, 2021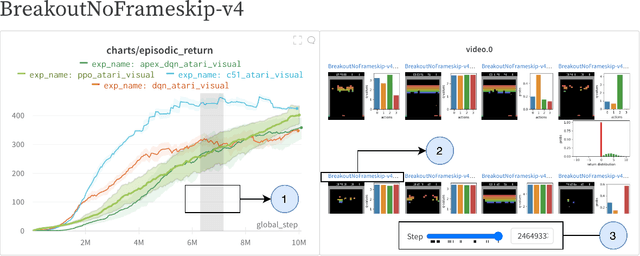
CleanRL is an open-source library that provides high-quality single-file implementations of Deep Reinforcement Learning algorithms. It provides a simpler yet scalable developing experience by having a straightforward codebase and integrating production tools to help interact and scale experiments. In CleanRL, we put all details of an algorithm into a single file, making these performance-relevant details easier to recognize. Additionally, an experiment tracking feature is available to help log metrics, hyperparameters, videos of an agent's gameplay, dependencies, and more to the cloud. Despite succinct implementations, we have also designed tools to help scale, at one point orchestrating experiments on more than 2000 machines simultaneously via Docker and cloud providers. Finally, we have ensured the quality of the implementations by benchmarking against a variety of environments. The source code of CleanRL can be found at https://github.com/vwxyzjn/cleanrl