 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of the NeurIPS 2023 Neural MMO Competition on Multi-task Reinforcement Learning
Aug 17, 2025We present the results of the NeurIPS 2023 Neural MMO Competition, which attracted over 200 participants and submissions. Participants trained goal-conditional policies that generalize to tasks, maps, and opponents never seen during training. The top solution achieved a score 4x higher than our baseline within 8 hours of training on a single 4090 GPU. We open-source everything relating to Neural MMO and the competition under the MIT license, including the policy weights and training code for our baseline and for the top submissions.
Syllabus: Portable Curricula for Reinforcement Learning Agents
Nov 18, 2024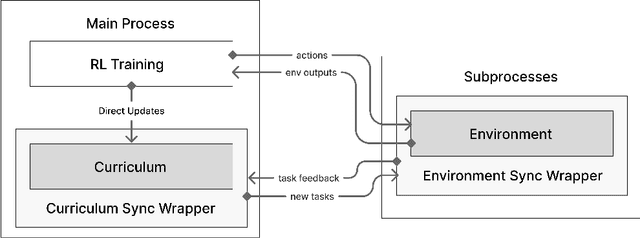


Curriculum learning has been a quiet yet crucial component of many of the high-profile successes of reinforcement learning. Despite this, none of the major reinforcement learning libraries directly support curriculum learning or include curriculum learning implementations. These methods can improve the capabilities and robustness of RL agents, but often require significant, complex changes to agent training code. We introduce Syllabus, a library for training RL agents with curriculum learning, as a solution to this problem. Syllabus provides a universal API for curriculum learning algorithms, implementations of popular curriculum learning methods, and infrastructure for easily integrating them with distributed training code written in nearly any RL library. Syllabus provides a minimal API for each of the core components of curriculum learning, dramatically simplifying the process of designing new algorithms and applying existing algorithms to new environments. We demonstrate that the same Syllabus code can be used to train agents written in multiple different RL libraries on numerous domains. In doing so, we present the first examples of curriculum learning in NetHack and Neural MMO, two of the premier challenges for single-agent and multi-agent RL respectively, achieving strong results compared to state of the art baselines.
Conditioned Language Policy: A General Framework for Steerable Multi-Objective Finetuning
Jul 22, 2024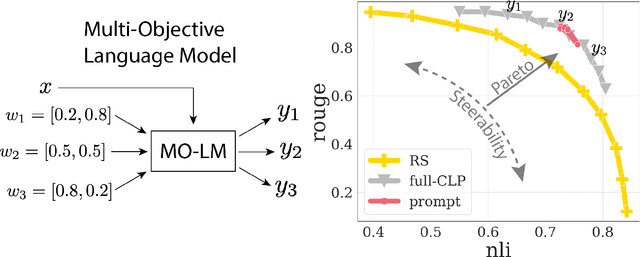
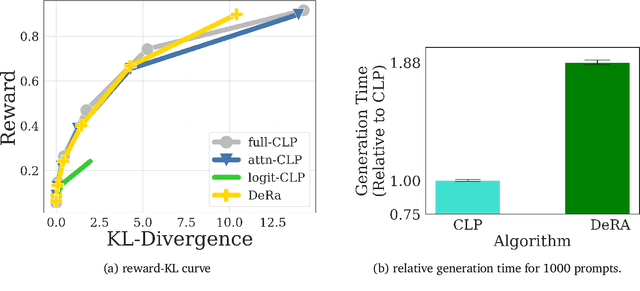
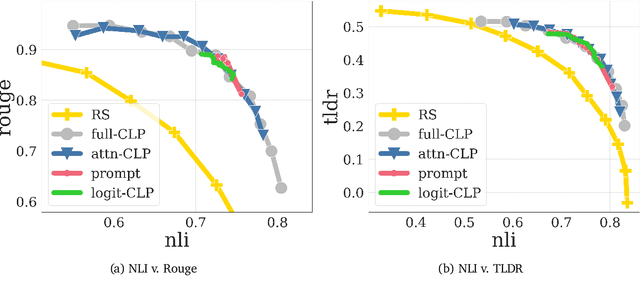
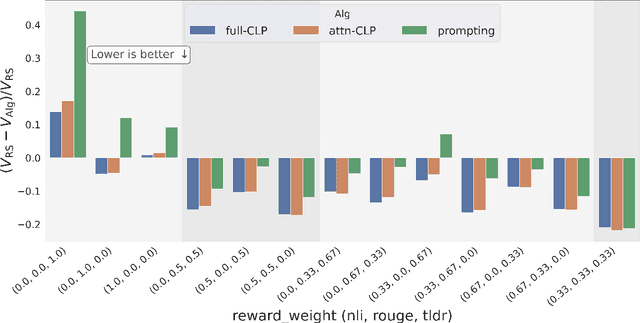
Reward-based finetuning is crucial for aligning language policies with intended behaviors (e.g., creativity and safety). A key challenge here is to develop steerable language models that trade-off multiple (conflicting) objectives in a flexible and efficient manner. This paper presents Conditioned Language Policy (CLP), a general framework for finetuning language models on multiple objectives. Building on techniques from multi-task training and parameter-efficient finetuning, CLP can learn steerable models that effectively trade-off conflicting objectives at inference time. Notably, this does not require training or maintaining multiple models to achieve different trade-offs between the objectives. Through an extensive set of experiments and ablations, we show that the CLP framework learns steerable models that outperform and Pareto-dominate the current state-of-the-art approaches for multi-objective finetuning.
Massively Multiagent Minigames for Training Generalist Agents
Jun 07, 2024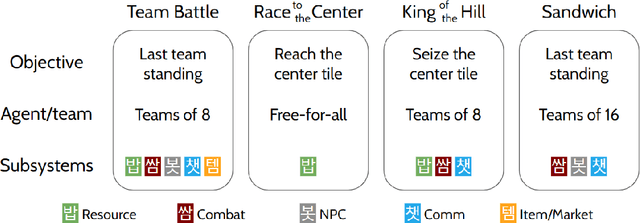
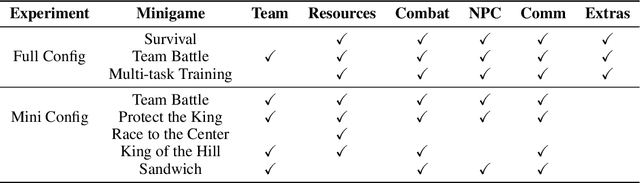
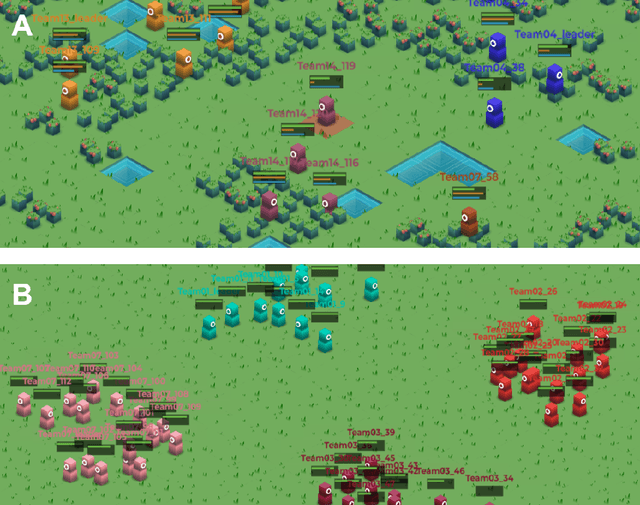
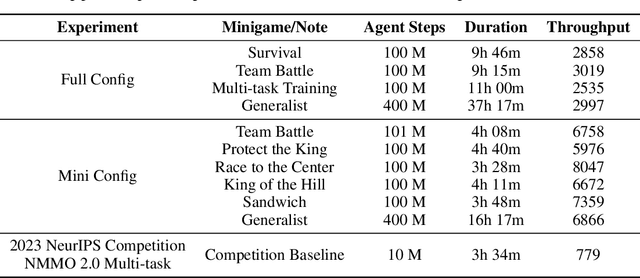
We present Meta MMO, a collection of many-agent minigames for use as a reinforcement learning benchmark. Meta MMO is built on top of Neural MMO, a massively multiagent environment that has been the subject of two previous NeurIPS competitions. Our work expands Neural MMO with several computationally efficient minigames. We explore generalization across Meta MMO by learning to play several minigames with a single set of weights. We release the environment, baselines, and training code under the MIT license. We hope that Meta MMO will spur additional progress on Neural MMO and, more generally, will serve as a useful benchmark for many-agent generalization.
How Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks
Apr 04, 2024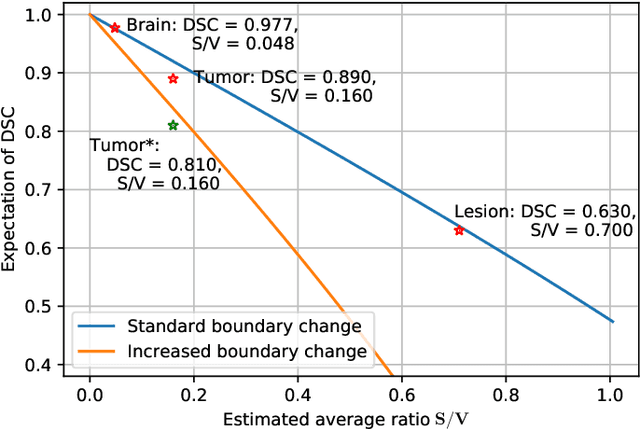
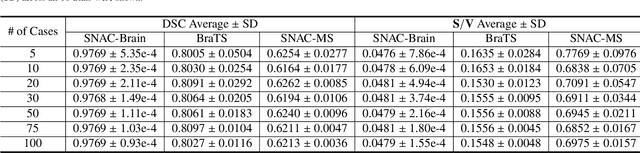

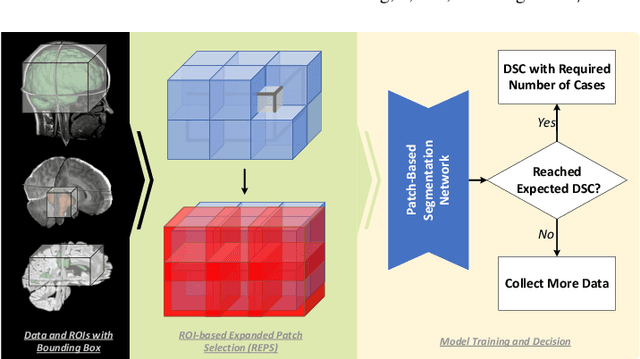
Training deep neural networks reliably requires access to large-scale datasets. However, obtaining such datasets can be challenging, especially in the context of neuroimaging analysis tasks, where the cost associated with image acquisition and annotation can be prohibitive. To mitigate both the time and financial costs associated with model development, a clear understanding of the amount of data required to train a satisfactory model is crucial. This paper focuses on an early stage phase of deep learning research, prior to model development, and proposes a strategic framework for estimating the amount of annotated data required to train patch-based segmentation networks. This framework includes the establishment of performance expectations using a novel Minor Boundary Adjustment for Threshold (MinBAT) method, and standardizing patch selection through the ROI-based Expanded Patch Selection (REPS) method. Our experiments demonstrate that tasks involving regions of interest (ROIs) with different sizes or shapes may yield variably acceptable Dice Similarity Coefficient (DSC) scores. By setting an acceptable DSC as the target, the required amount of training data can be estimated and even predicted as data accumulates. This approach could assist researchers and engineers in estimating the cost associated with data collection and annotation when defining a new segmentation task based on deep neural networks, ultimately contributing to their efficient translation to real-world applications.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Gradient Informed Proximal Policy Optimization
Dec 14, 2023



We introduce a novel policy learning method that integrates analytical gradients from differentiable environments with the Proximal Policy Optimization (PPO) algorithm. To incorporate analytical gradients into the PPO framework, we introduce the concept of an {\alpha}-policy that stands as a locally superior policy. By adaptively modifying the {\alpha} value, we can effectively manage the influence of analytical policy gradients during learning. To this end, we suggest metrics for assessing the variance and bias of analytical gradients, reducing dependence on these gradients when high variance or bias is detected. Our proposed approach outperforms baseline algorithms in various scenarios, such as function optimization, physics simulations, and traffic control environments. Our code can be found online: https://github.com/SonSang/gippo.
Neural MMO 2.0: A Massively Multi-task Addition to Massively Multi-agent Learning
Nov 07, 2023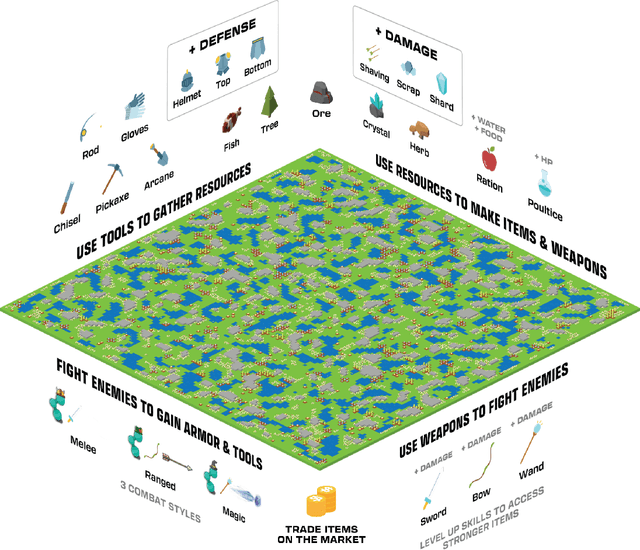

Neural MMO 2.0 is a massively multi-agent environment for reinforcement learning research. The key feature of this new version is a flexible task system that allows users to define a broad range of objectives and reward signals. We challenge researchers to train agents capable of generalizing to tasks, maps, and opponents never seen during training. Neural MMO features procedurally generated maps with 128 agents in the standard setting and support for up to. Version 2.0 is a complete rewrite of its predecessor with three-fold improved performance and compatibility with CleanRL. We release the platform as free and open-source software with comprehensive documentation available at neuralmmo.github.io and an active community Discord. To spark initial research on this new platform, we are concurrently running a competition at NeurIPS 2023.
Reward Scale Robustness for Proximal Policy Optimization via DreamerV3 Tricks
Oct 26, 2023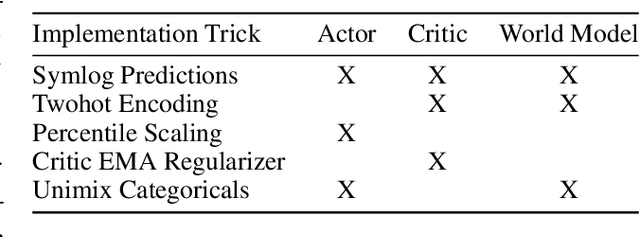
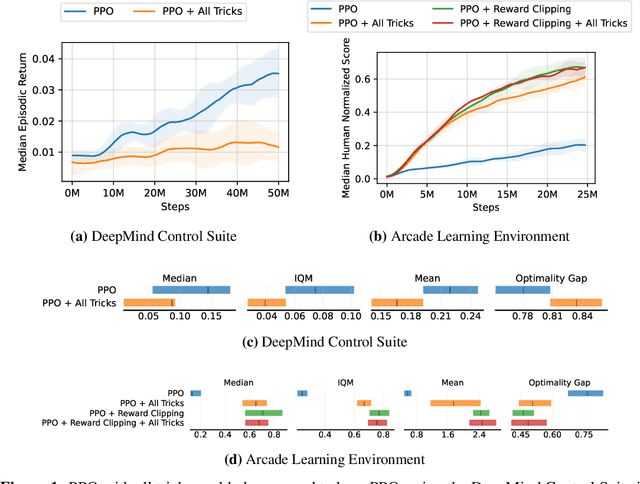
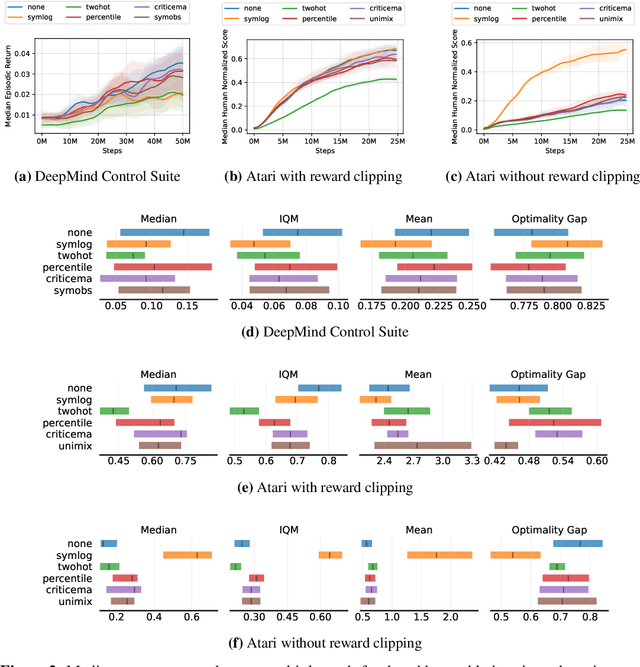
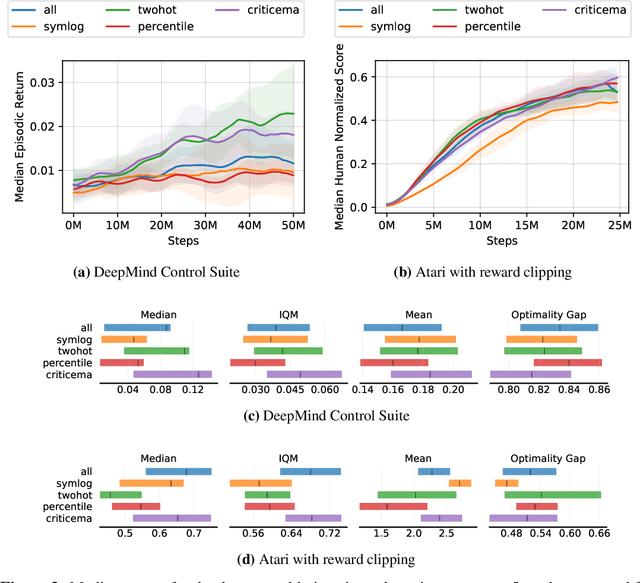
Most reinforcement learning methods rely heavily on dense, well-normalized environment rewards. DreamerV3 recently introduced a model-based method with a number of tricks that mitigate these limitations, achieving state-of-the-art on a wide range of benchmarks with a single set of hyperparameters. This result sparked discussion about the generality of the tricks, since they appear to be applicable to other reinforcement learning algorithms. Our work applies DreamerV3's tricks to PPO and is the first such empirical study outside of the original work. Surprisingly, we find that the tricks presented do not transfer as general improvements to PPO. We use a high quality PPO reference implementation and present extensive ablation studies totaling over 10,000 A100 hours on the Arcade Learning Environment and the DeepMind Control Suite. Though our experiments demonstrate that these tricks do not generally outperform PPO, we identify cases where they succeed and offer insight into the relationship between the implementation tricks. In particular, PPO with these tricks performs comparably to PPO on Atari games with reward clipping and significantly outperforms PPO without reward clipping.
Improving Multiple Sclerosis Lesion Segmentation Across Clinical Sites: A Federated Learning Approach with Noise-Resilient Training
Aug 31, 2023



Accurately measuring the evolution of Multiple Sclerosis (MS) with magnetic resonance imaging (MRI) critically informs understanding of disease progression and helps to direct therapeutic strategy. Deep learning models have shown promise for automatically segmenting MS lesions, but the scarcity of accurately annotated data hinders progress in this area. Obtaining sufficient data from a single clinical site is challenging and does not address the heterogeneous need for model robustness. Conversely, the collection of data from multiple sites introduces data privacy concerns and potential label noise due to varying annotation standards. To address this dilemma, we explore the use of the federated learning framework while considering label noise. Our approach enables collaboration among multiple clinical sites without compromising data privacy under a federated learning paradigm that incorporates a noise-robust training strategy based on label correction. Specifically, we introduce a Decoupled Hard Label Correction (DHLC) strategy that considers the imbalanced distribution and fuzzy boundaries of MS lesions, enabling the correction of false annotations based on prediction confidence. We also introduce a Centrally Enhanced Label Correction (CELC) strategy, which leverages the aggregated central model as a correction teacher for all sites, enhancing the reliability of the correction process. Extensive experiments conducted on two multi-site datasets demonstrate the effectiveness and robustness of our proposed methods, indicating their potential for clinical applications in multi-site collaborations.