 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware World Model for Adaptive Prediction and Control
Jun 10, 2025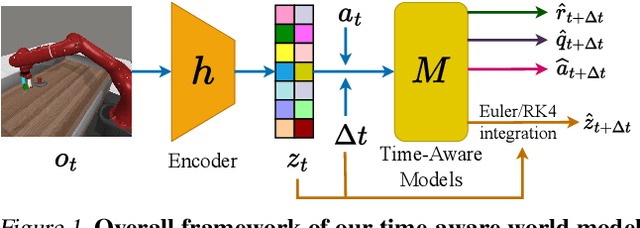



In this work, we introduce the Time-Aware World Model (TAWM), a model-based approach that explicitly incorporates temporal dynamics. By conditioning on the time-step size, {\Delta}t, and training over a diverse range of {\Delta}t values -- rather than sampling at a fixed time-step -- TAWM learns both high- and low-frequency task dynamics across diverse control problems. Grounded in the information-theoretic insight that the optimal sampling rate depends on a system's underlying dynamics, this time-aware formulation improves both performance and data efficiency. Empirical evaluations show that TAWM consistently outperforms conventional models across varying observation rates in a variety of control tasks, using the same number of training samples and iterations. Our code can be found online at: github.com/anh-nn01/Time-Aware-World-Model.
DMesh++: An Efficient Differentiable Mesh for Complex Shapes
Dec 21, 2024



Recent probabilistic methods for 3D triangular meshes capture diverse shapes by differentiable mesh connectivity, but face high computational costs with increased shape details. We introduce a new differentiable mesh processing method in 2D and 3D that addresses this challenge and efficiently handles meshes with intricate structures. Additionally, we present an algorithm that adapts the mesh resolution to local geometry in 2D for efficient representation. We demonstrate the effectiveness of our approach on 2D point cloud and 3D multi-view reconstruction tasks. Visit our project page (https://sonsang.github.io/dmesh2-project) for source code and supplementary material.
Gradient-based Trajectory Optimization with Parallelized Differentiable Traffic Simulation
Dec 21, 2024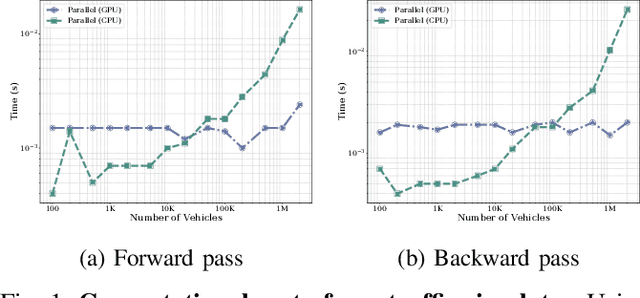
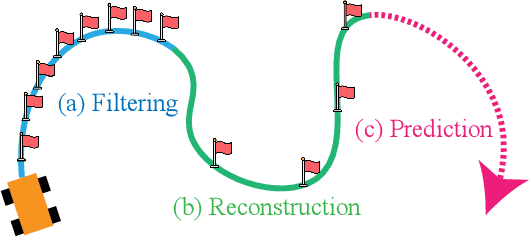
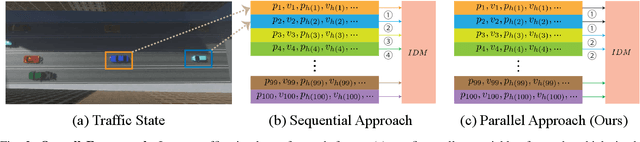

We present a parallelized differentiable traffic simulator based on the Intelligent Driver Model (IDM), a car-following framework that incorporates driver behavior as key variables. Our simulator efficiently models vehicle motion, generating trajectories that can be supervised to fit real-world data. By leveraging its differentiable nature, IDM parameters are optimized using gradient-based methods. With the capability to simulate up to 2 million vehicles in real time, the system is scalable for large-scale trajectory optimization. We show that we can use the simulator to filter noise in the input trajectories (trajectory filtering), reconstruct dense trajectories from sparse ones (trajectory reconstruction), and predict future trajectories (trajectory prediction), with all generated trajectories adhering to physical laws. We validate our simulator and algorithm on several datasets including NGSIM and Waymo Open Dataset.
Deep Stochastic Kinematic Models for Probabilistic Motion Forecasting in Traffic
Jun 03, 2024



Kinematic priors have shown to be helpful in boosting generalization and performance in prior work on trajectory forecasting. Specifically, kinematic priors have been applied such that models predict a set of actions instead of future output trajectories. By unrolling predicted trajectories via time integration and models of kinematic dynamics, predicted trajectories are not only kinematically feasible on average but also relate uncertainty from one timestep to the next. With benchmarks supporting prediction of multiple trajectory predictions, deterministic kinematic priors are less and less applicable to current models. We propose a method for integrating probabilistic kinematic priors into modern probabilistic trajectory forecasting architectures. The primary difference between our work and previous techniques is the analytical quantification of variance, or uncertainty, in predicted trajectories. With negligible additional computational overhead, our method can be generalized and easily implemented with any modern probabilistic method that models candidate trajectories as Gaussian distributions. In particular, our method works especially well in unoptimal settings, such as with small datasets or in the presence of noise. Our method achieves up to a 50% performance boost in small dataset settings and up to an 8% performance boost in large-scale learning compared to previous kinematic prediction methods on SOTA trajectory forecasting architectures out-of-the-box, with minimal fine-tuning. In this paper, we show four analytical formulations of probabilistic kinematic priors which can be used for any Gaussian Mixture Model (GMM)-based deep learning models, quantify the error bound on linear approximations applied during trajectory unrolling, and show results to evaluate each formulation in trajectory forecasting.
DMesh: A Differentiable Representation for General Meshes
Apr 20, 2024We present a differentiable representation, DMesh, for general 3D triangular meshes. DMesh considers both the geometry and connectivity information of a mesh. In our design, we first get a set of convex tetrahedra that compactly tessellates the domain based on Weighted Delaunay Triangulation (WDT), and formulate probability of faces to exist on our desired mesh in a differentiable manner based on the WDT. This enables DMesh to represent meshes of various topology in a differentiable way, and allows us to reconstruct the mesh under various observations, such as point cloud and multi-view images using gradient-based optimization. The source code and full paper is available at: https://sonsang.github.io/dmesh-project.
Gradient Informed Proximal Policy Optimization
Dec 14, 2023



We introduce a novel policy learning method that integrates analytical gradients from differentiable environments with the Proximal Policy Optimization (PPO) algorithm. To incorporate analytical gradients into the PPO framework, we introduce the concept of an {\alpha}-policy that stands as a locally superior policy. By adaptively modifying the {\alpha} value, we can effectively manage the influence of analytical policy gradients during learning. To this end, we suggest metrics for assessing the variance and bias of analytical gradients, reducing dependence on these gradients when high variance or bias is detected. Our proposed approach outperforms baseline algorithms in various scenarios, such as function optimization, physics simulations, and traffic control environments. Our code can be found online: https://github.com/SonSang/gippo.
ICF-SRSR: Invertible scale-Conditional Function for Self-Supervised Real-world Single Image Super-Resolution
Jul 24, 2023Single image super-resolution (SISR) is a challenging ill-posed problem that aims to up-sample a given low-resolution (LR) image to a high-resolution (HR) counterpart. Due to the difficulty in obtaining real LR-HR training pairs, recent approaches are trained on simulated LR images degraded by simplified down-sampling operators, e.g., bicubic. Such an approach can be problematic in practice because of the large gap between the synthesized and real-world LR images. To alleviate the issue, we propose a novel Invertible scale-Conditional Function (ICF), which can scale an input image and then restore the original input with different scale conditions. By leveraging the proposed ICF, we construct a novel self-supervised SISR framework (ICF-SRSR) to handle the real-world SR task without using any paired/unpaired training data. Furthermore, our ICF-SRSR can generate realistic and feasible LR-HR pairs, which can make existing supervised SISR networks more robust. Extensive experiments demonstrate the effectiveness of the proposed method in handling SISR in a fully self-supervised manner. Our ICF-SRSR demonstrates superior performance compared to the existing methods trained on synthetic paired images in real-world scenarios and exhibits comparable performance compared to state-of-the-art supervised/unsupervised methods on public benchmark datasets.
GeoLCR: Attention-based Geometric Loop Closure and Registration
Mar 04, 2023

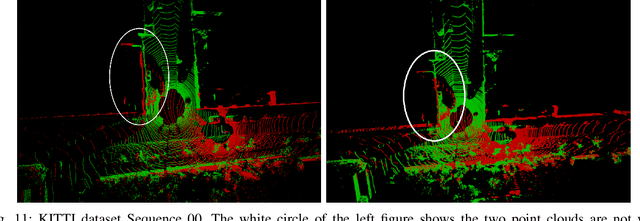
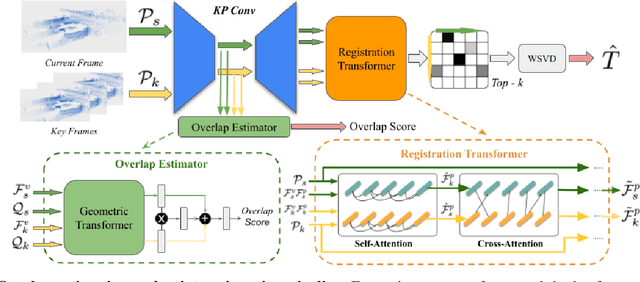
We present a novel algorithm for learning-based loop-closure for SLAM (simultaneous localization and mapping) applications. Our approach is designed for general 3D point cloud data, including those from lidar, and is used to prevent accumulated drift over time for autonomous driving. We voxelize the point clouds into coarse voxels and calculate the overlap to estimate if the vehicle drives in a loop. We perform point-level registration to compute the current pose accurately. We have evaluated our approach on well-known datasets KITTI, KITTI-360, Nuscenes, Complex Urban, NCLT, and MulRan. We show at most 2 times improvement in accuracy estimation of translation and rotation. On some challenging sequences, our method is the first approach that can obtain a 100% success rate.
Differentiable Hybrid Traffic Simulation
Oct 14, 2022


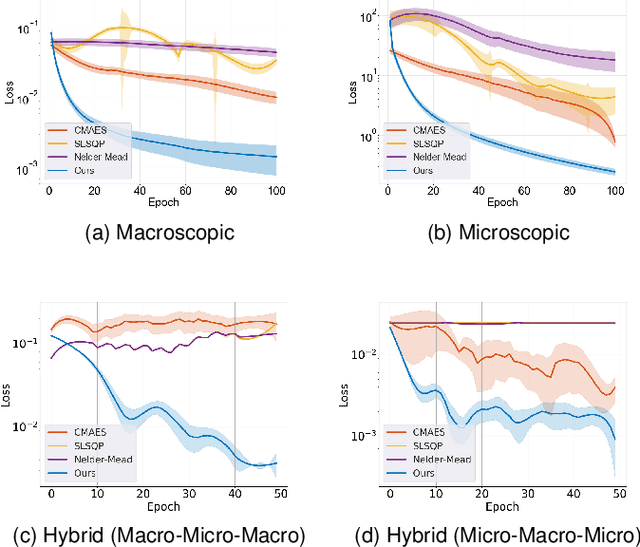
We introduce a novel differentiable hybrid traffic simulator, which simulates traffic using a hybrid model of both macroscopic and microscopic models and can be directly integrated into a neural network for traffic control and flow optimization. This is the first differentiable traffic simulator for macroscopic and hybrid models that can compute gradients for traffic states across time steps and inhomogeneous lanes. To compute the gradient flow between two types of traffic models in a hybrid framework, we present a novel intermediate conversion component that bridges the lanes in a differentiable manner as well. We also show that we can use analytical gradients to accelerate the overall process and enhance scalability. Thanks to these gradients, our simulator can provide more efficient and scalable solutions for complex learning and control problems posed in traffic engineering than other existing algorithms. Refer to https://sites.google.com/umd.edu/diff-hybrid-traffic-sim for our project.
Traffic-Aware Autonomous Driving with Differentiable Traffic Simulation
Oct 07, 2022



While there have been advancements in autonomous driving control and traffic simulation, there have been little to no works exploring the unification of both with deep learning. Works in both areas seem to focus on entirely different exclusive problems, yet traffic and driving have inherent semantic relations in the real world. In this paper, we present a generalizable distillation-style method for traffic-informed imitation learning that directly optimizes a autonomous driving policy for the overall benefit of faster traffic flow and lower energy consumption. We capitalize on improving the arbitrarily defined supervision of speed control in imitation learning systems, as most driving research focus on perception and steering. Moreover, our method addresses the lack of co-simulation between traffic and driving simulators and lays groundwork for directly involving traffic simulation with autonomous driving in future work. Our results show that, with information from traffic simulation involved in supervision of imitation learning methods, an autonomous vehicle can learn how to accelerate in a fashion that is beneficial for traffic flow and overall energy consumption for all nearby vehicles.