 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRTriton: Large-Scale Synthetic Data Reinforcement Learning for Triton Kernel Generation
Mar 23, 2026Developing efficient CUDA kernels is a fundamental yet challenging task in the generative AI industry. Recent researches leverage Large Language Models (LLMs) to automatically convert PyTorch reference implementations to CUDA kernels, significantly reducing the engineering efforts. State-of-the-art LLMs, such as GPT-5.2 and Claude-Sonnet-4.5, still struggle in this specific task. To address this challenge, we propose DRTriton, a scalable learning framework for training LLMs to convert PyTorch codes into highly optimized Triton kernels, which are then compiled to CUDA kernels at runtime. DRTriton consists of three key components: (i) a data synthetic algorithm CSP-DAG that guarantees full coverage and unbiased uniform sampling over the operator space with controlled difficulty; (ii) a curriculum reinforcement learning with decoupled reward efficiently optimizes conversion success rate and inference speed simultaneously; and (iii) a test-time search algorithm that further improves the inference speed of the generated Triton kernels. Notably, despite being trained exclusively on synthetic data, DRTriton generalizes effectively to real-world CUDA kernels that are challenging even for human experts. Experimental results show that DRTriton-7B achieves speedup on 92% of the KernelBench Level 2, compared to 23% for GPT-5.2 and 19% for Claude-Sonnet-4.5.
Beyond Test-Time Training: Learning to Reason via Hardware-Efficient Optimal Control
Mar 10, 2026Associative memory has long underpinned the design of sequential models. Beyond recall, humans reason by projecting future states and selecting goal-directed actions, a capability that modern language models increasingly require but do not natively encode. While prior work uses reinforcement learning or test-time training, planning remains external to the model architecture. We formulate reasoning as optimal control and introduce the Test-Time Control (TTC) layer, which performs finite-horizon LQR planning over latent states at inference time, represents a value function within neural architectures, and leverages it as the nested objective to enable planning before prediction. To ensure scalability, we derive a hardware-efficient LQR solver based on a symplectic formulation and implement it as a fused CUDA kernel, enabling parallel execution with minimal overhead. Integrated as an adapter into pretrained LLMs, TTC layers improve mathematical reasoning performance by up to +27.8% on MATH-500 and 2-3x Pass@8 improvements on AMC and AIME, demonstrating that embedding optimal control as an architectural component provides an effective and scalable mechanism for reasoning beyond test-time training.
Active Asymmetric Multi-Agent Multimodal Learning under Uncertainty
Feb 04, 2026Multi-agent systems are increasingly equipped with heterogeneous multimodal sensors, enabling richer perception but introducing modality-specific and agent-dependent uncertainty. Existing multi-agent collaboration frameworks typically reason at the agent level, assume homogeneous sensing, and handle uncertainty implicitly, limiting robustness under sensor corruption. We propose Active Asymmetric Multi-Agent Multimodal Learning under Uncertainty (A2MAML), a principled approach for uncertainty-aware, modality-level collaboration. A2MAML models each modality-specific feature as a stochastic estimate with uncertainty prediction, actively selects reliable agent-modality pairs, and aggregates information via Bayesian inverse-variance weighting. This formulation enables fine-grained, modality-level fusion, supports asymmetric modality availability, and provides a principled mechanism to suppress corrupted or noisy modalities. Extensive experiments on connected autonomous driving scenarios for collaborative accident detection demonstrate that A2MAML consistently outperforms both single-agent and collaborative baselines, achieving up to 18.7% higher accident detection rate.
DRPO: Efficient Reasoning via Decoupled Reward Policy Optimization
Oct 06, 2025Recent large reasoning models (LRMs) driven by reinforcement learning algorithms (e.g., GRPO) have achieved remarkable performance on challenging reasoning tasks. However, these models suffer from overthinking, generating unnecessarily long and redundant reasoning even for simple questions, which substantially increases computational cost and response latency. While existing methods incorporate length rewards to GRPO to promote concise reasoning, they incur significant performance degradation. We identify the root cause: when rewards for correct but long rollouts are penalized, GRPO's group-relative advantage function can assign them negative advantages, actively discouraging valid reasoning. To overcome this, we propose Decoupled Reward Policy Optimization (DRPO), a novel framework that decouples the length-based learning signal of correct rollouts from incorrect ones. DRPO ensures that reward signals for correct rollouts are normalized solely within the positive group, shielding them from interference by negative samples. The DRPO's objective is grounded in integrating an optimized positive data distribution, which maximizes length-based rewards under a KL regularization, into a discriminative objective. We derive a closed-form solution for this distribution, enabling efficient computation of the objective and its gradients using only on-policy data and importance weighting. Of independent interest, this formulation is general and can incorporate other preference rewards of positive data beyond length. Experiments on mathematical reasoning tasks demonstrate DRPO's significant superiority over six efficient reasoning baselines. Notably, with a 1.5B model, our method achieves 77\% length reduction with only 1.1\% performance loss on simple questions like GSM8k dataset, while the follow-up baseline sacrifices 4.3\% for 68\% length reduction.
HART: Human Aligned Reconstruction Transformer
Sep 30, 2025



We introduce HART, a unified framework for sparse-view human reconstruction. Given a small set of uncalibrated RGB images of a person as input, it outputs a watertight clothed mesh, the aligned SMPL-X body mesh, and a Gaussian-splat representation for photorealistic novel-view rendering. Prior methods for clothed human reconstruction either optimize parametric templates, which overlook loose garments and human-object interactions, or train implicit functions under simplified camera assumptions, limiting applicability in real scenes. In contrast, HART predicts per-pixel 3D point maps, normals, and body correspondences, and employs an occlusion-aware Poisson reconstruction to recover complete geometry, even in self-occluded regions. These predictions also align with a parametric SMPL-X body model, ensuring that reconstructed geometry remains consistent with human structure while capturing loose clothing and interactions. These human-aligned meshes initialize Gaussian splats to further enable sparse-view rendering. While trained on only 2.3K synthetic scans, HART achieves state-of-the-art results: Chamfer Distance improves by 18-23 percent for clothed-mesh reconstruction, PA-V2V drops by 6-27 percent for SMPL-X estimation, LPIPS decreases by 15-27 percent for novel-view synthesis on a wide range of datasets. These results suggest that feed-forward transformers can serve as a scalable model for robust human reconstruction in real-world settings. Code and models will be released.
Time-Aware World Model for Adaptive Prediction and Control
Jun 10, 2025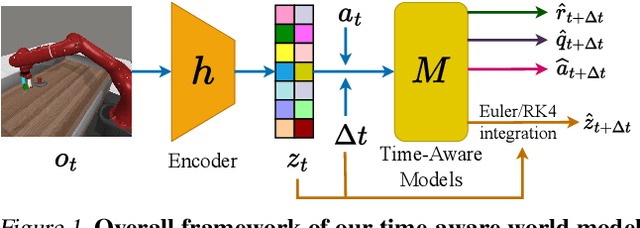



In this work, we introduce the Time-Aware World Model (TAWM), a model-based approach that explicitly incorporates temporal dynamics. By conditioning on the time-step size, {\Delta}t, and training over a diverse range of {\Delta}t values -- rather than sampling at a fixed time-step -- TAWM learns both high- and low-frequency task dynamics across diverse control problems. Grounded in the information-theoretic insight that the optimal sampling rate depends on a system's underlying dynamics, this time-aware formulation improves both performance and data efficiency. Empirical evaluations show that TAWM consistently outperforms conventional models across varying observation rates in a variety of control tasks, using the same number of training samples and iterations. Our code can be found online at: github.com/anh-nn01/Time-Aware-World-Model.
DisCO: Reinforcing Large Reasoning Models with Discriminative Constrained Optimization
May 18, 2025The recent success and openness of DeepSeek-R1 have brought widespread attention to Group Relative Policy Optimization (GRPO) as a reinforcement learning method for large reasoning models (LRMs). In this work, we analyze the GRPO objective under a binary reward setting and reveal an inherent limitation of question-level difficulty bias. We also identify a connection between GRPO and traditional discriminative methods in supervised learning. Motivated by these insights, we introduce a new Discriminative Constrained Optimization (DisCO) framework for reinforcing LRMs, grounded in the principle of discriminative learning. The main differences between DisCO and GRPO and its recent variants are: (1) it replaces the group relative objective with a discriminative objective defined by a scoring function; (2) it abandons clipping-based surrogates in favor of non-clipping RL surrogate objectives used as scoring functions; (3) it employs a simple yet effective constrained optimization approach to enforce the KL divergence constraint, ensuring stable training. As a result, DisCO offers notable advantages over GRPO and its variants: (i) it completely eliminates difficulty bias by adopting discriminative objectives; (ii) it addresses the entropy instability in GRPO and its variants through the use of non-clipping scoring functions and a constrained optimization approach; (iii) it allows the incorporation of advanced discriminative learning techniques to address data imbalance, where a significant number of questions have more negative than positive generated answers during training. Our experiments on enhancing the mathematical reasoning capabilities of SFT-finetuned models show that DisCO significantly outperforms GRPO and its improved variants such as DAPO, achieving average gains of 7\% over GRPO and 6\% over DAPO across six benchmark tasks for an 1.5B model.
Model Steering: Learning with a Reference Model Improves Generalization Bounds and Scaling Laws
May 13, 2025This paper formalizes an emerging learning paradigm that uses a trained model as a reference to guide and enhance the training of a target model through strategic data selection or weighting, named $\textbf{model steering}$. While ad-hoc methods have been used in various contexts, including the training of large foundation models, its underlying principles remain insufficiently understood, leading to sub-optimal performance. In this work, we propose a theory-driven framework for model steering called $\textbf{DRRho risk minimization}$, which is rooted in Distributionally Robust Optimization (DRO). Through a generalization analysis, we provide theoretical insights into why this approach improves generalization and data efficiency compared to training without a reference model. To the best of our knowledge, this is the first time such theoretical insights are provided for the new learning paradigm, which significantly enhance our understanding and practice of model steering. Building on these insights and the connection between contrastive learning and DRO, we introduce a novel method for Contrastive Language-Image Pretraining (CLIP) with a reference model, termed DRRho-CLIP. Extensive experiments validate the theoretical insights, reveal a superior scaling law compared to CLIP without a reference model, and demonstrate its strength over existing heuristic approaches.
AUKT: Adaptive Uncertainty-Guided Knowledge Transfer with Conformal Prediction
Feb 25, 2025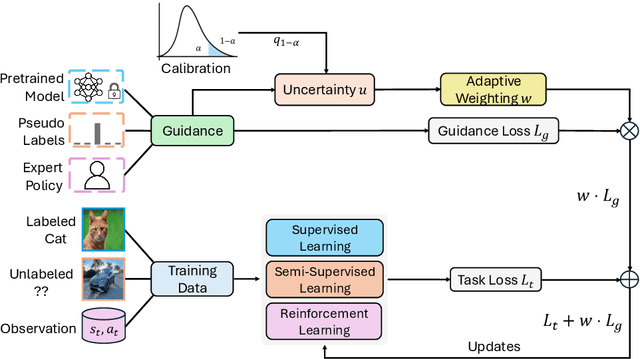
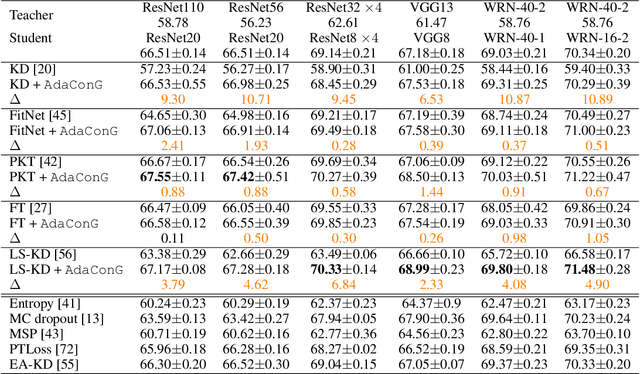

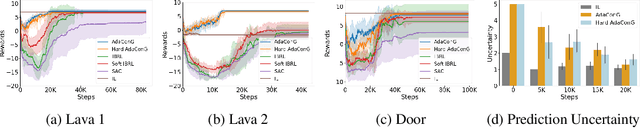
Knowledge transfer between teacher and student models has proven effective across various machine learning applications. However, challenges arise when the teacher's predictions are noisy, or the data domain during student training shifts from the teacher's pretraining data. In such scenarios, blindly relying on the teacher's predictions can lead to suboptimal knowledge transfer. To address these challenges, we propose a novel and universal framework, Adaptive Uncertainty-guided Knowledge Transfer ($\textbf{AUKT}$), which leverages Conformal Prediction (CP) to dynamically adjust the student's reliance on the teacher's guidance based on the teacher's prediction uncertainty. CP is a distribution-free, model-agnostic approach that provides reliable prediction sets with statistical coverage guarantees and minimal computational overhead. This adaptive mechanism mitigates the risk of learning undesirable or incorrect knowledge. We validate the proposed framework across diverse applications, including image classification, imitation-guided reinforcement learning, and autonomous driving. Experimental results consistently demonstrate that our approach improves performance, robustness and transferability, offering a promising direction for enhanced knowledge transfer in real-world applications.
CAML: Collaborative Auxiliary Modality Learning for Multi-Agent Systems
Feb 25, 2025Multi-modality learning has become a crucial technique for improving the performance of machine learning applications across domains such as autonomous driving, robotics, and perception systems. While existing frameworks such as Auxiliary Modality Learning (AML) effectively utilize multiple data sources during training and enable inference with reduced modalities, they primarily operate in a single-agent context. This limitation is particularly critical in dynamic environments, such as connected autonomous vehicles (CAV), where incomplete data coverage can lead to decision-making blind spots. To address these challenges, we propose Collaborative Auxiliary Modality Learning ($\textbf{CAML}$), a novel multi-agent multi-modality framework that enables agents to collaborate and share multimodal data during training while allowing inference with reduced modalities per agent during testing. We systematically analyze the effectiveness of $\textbf{CAML}$ from the perspective of uncertainty reduction and data coverage, providing theoretical insights into its advantages over AML. Experimental results in collaborative decision-making for CAV in accident-prone scenarios demonstrate that \ours~achieves up to a ${\bf 58.13}\%$ improvement in accident detection. Additionally, we validate $\textbf{CAML}$ on real-world aerial-ground robot data for collaborative semantic segmentation, achieving up to a ${\bf 10.61}\%$ improvement in mIoU.