 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Multimodal Moxin Models with Moxin-VLM and Moxin-VLA
Dec 22, 2025Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Moxin 7B is introduced as a fully open-source LLM developed in accordance with the Model Openness Framework, which moves beyond the simple sharing of model weights to embrace complete transparency in training, datasets, and implementation detail, thus fostering a more inclusive and collaborative research environment that can sustain a healthy open-source ecosystem. To further equip Moxin with various capabilities in different tasks, we develop three variants based on Moxin, including Moxin-VLM, Moxin-VLA, and Moxin-Chinese, which target the vision-language, vision-language-action, and Chinese capabilities, respectively. Experiments show that our models achieve superior performance in various evaluations. We adopt open-source framework and open data for the training. We release our models, along with the available data and code to derive these models.
TSLA: A Task-Specific Learning Adaptation for Semantic Segmentation on Autonomous Vehicles Platform
Aug 17, 2025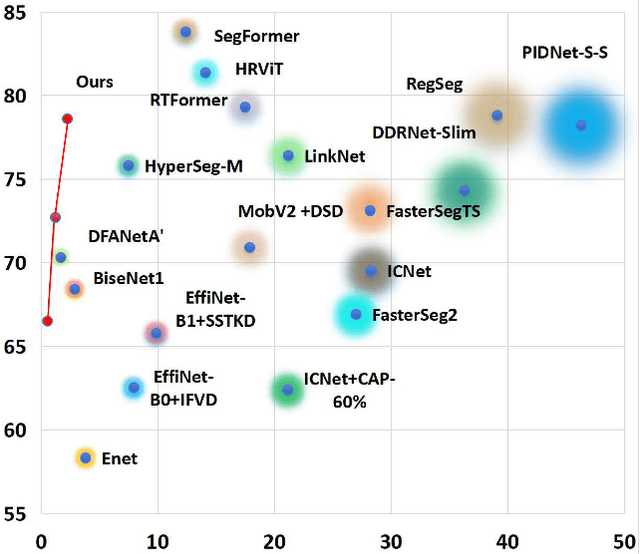
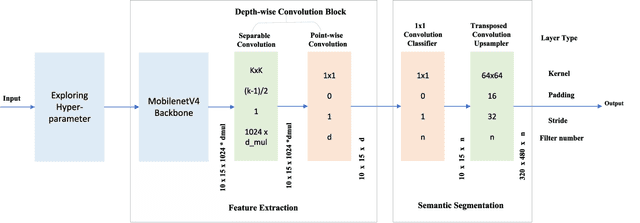
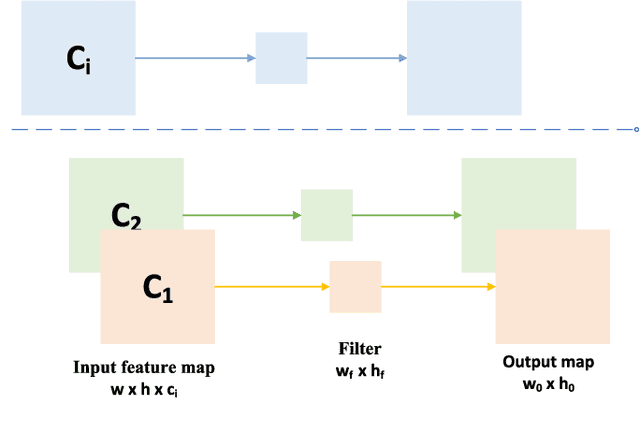
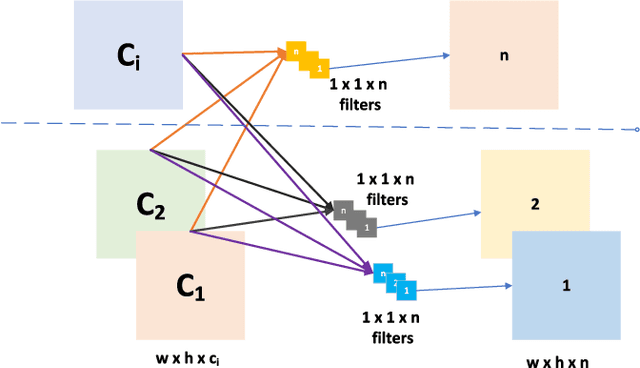
Autonomous driving platforms encounter diverse driving scenarios, each with varying hardware resources and precision requirements. Given the computational limitations of embedded devices, it is crucial to consider computing costs when deploying on target platforms like the NVIDIA\textsuperscript{\textregistered} DRIVE PX 2. Our objective is to customize the semantic segmentation network according to the computing power and specific scenarios of autonomous driving hardware. We implement dynamic adaptability through a three-tier control mechanism -- width multiplier, classifier depth, and classifier kernel -- allowing fine-grained control over model components based on hardware constraints and task requirements. This adaptability facilitates broad model scaling, targeted refinement of the final layers, and scenario-specific optimization of kernel sizes, leading to improved resource allocation and performance. Additionally, we leverage Bayesian Optimization with surrogate modeling to efficiently explore hyperparameter spaces under tight computational budgets. Our approach addresses scenario-specific and task-specific requirements through automatic parameter search, accommodating the unique computational complexity and accuracy needs of autonomous driving. It scales its Multiply-Accumulate Operations (MACs) for Task-Specific Learning Adaptation (TSLA), resulting in alternative configurations tailored to diverse self-driving tasks. These TSLA customizations maximize computational capacity and model accuracy, optimizing hardware utilization.
RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
Token Transforming: A Unified and Training-Free Token Compression Framework for Vision Transformer Acceleration
Jun 06, 2025Vision transformers have been widely explored in various vision tasks. Due to heavy computational cost, much interest has aroused for compressing vision transformer dynamically in the aspect of tokens. Current methods mainly pay attention to token pruning or merging to reduce token numbers, in which tokens are compressed exclusively, causing great information loss and therefore post-training is inevitably required to recover the performance. In this paper, we rethink token reduction and unify the process as an explicit form of token matrix transformation, in which all existing methods are constructing special forms of matrices within the framework. Furthermore, we propose a many-to-many Token Transforming framework that serves as a generalization of all existing methods and reserves the most information, even enabling training-free acceleration. We conduct extensive experiments to validate our framework. Specifically, we reduce 40% FLOPs and accelerate DeiT-S by $\times$1.5 with marginal 0.1% accuracy drop. Furthermore, we extend the method to dense prediction tasks including segmentation, object detection, depth estimation, and language model generation. Results demonstrate that the proposed method consistently achieves substantial improvements, offering a better computation-performance trade-off, impressive budget reduction and inference acceleration.
Enabling Flexible Multi-LLM Integration for Scalable Knowledge Aggregation
May 28, 2025



Large language models (LLMs) have shown remarkable promise but remain challenging to continually improve through traditional finetuning, particularly when integrating capabilities from other specialized LLMs. Popular methods like ensemble and weight merging require substantial memory and struggle to adapt to changing data environments. Recent efforts have transferred knowledge from multiple LLMs into a single target model; however, they suffer from interference and degraded performance among tasks, largely due to limited flexibility in candidate selection and training pipelines. To address these issues, we propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. Specifically, we design an adaptive selection network that identifies the most relevant source LLMs based on their scores, thereby reducing knowledge interference. We further propose a dynamic weighted fusion strategy that accounts for the inherent strengths of candidate LLMs, along with a feedback-driven loss function that prevents the selector from converging on a single subset of sources. Experimental results demonstrate that our method can enable a more stable and scalable knowledge aggregation process while reducing knowledge interference by up to 50% compared to existing approaches. Code is avaliable at https://github.com/ZLKong/LLM_Integration
ACE: Exploring Activation Cosine Similarity and Variance for Accurate and Calibration-Efficient LLM Pruning
May 28, 2025



With the rapid expansion of large language models (LLMs), the demand for memory and computational resources has grown significantly. Recent advances in LLM pruning aim to reduce the size and computational cost of these models. However, existing methods often suffer from either suboptimal pruning performance or low time efficiency during the pruning process. In this work, we propose an efficient and effective pruning method that simultaneously achieves high pruning performance and fast pruning speed with improved calibration efficiency. Our approach introduces two key innovations: (1) An activation cosine similarity loss-guided pruning metric, which considers the angular deviation of the output activation between the dense and pruned models. (2) An activation variance-guided pruning metric, which helps preserve semantic distinctions in output activations after pruning, enabling effective pruning with shorter input sequences. These two components can be readily combined to enhance LLM pruning in both accuracy and efficiency. Experimental results show that our method achieves up to an 18% reduction in perplexity and up to 63% decrease in pruning time on prevalent LLMs such as LLaMA, LLaMA-2, and OPT.
Token Reduction Should Go Beyond Efficiency in Generative Models -- From Vision, Language to Multimodality
May 23, 2025In Transformer architectures, tokens\textemdash discrete units derived from raw data\textemdash are formed by segmenting inputs into fixed-length chunks. Each token is then mapped to an embedding, enabling parallel attention computations while preserving the input's essential information. Due to the quadratic computational complexity of transformer self-attention mechanisms, token reduction has primarily been used as an efficiency strategy. This is especially true in single vision and language domains, where it helps balance computational costs, memory usage, and inference latency. Despite these advances, this paper argues that token reduction should transcend its traditional efficiency-oriented role in the era of large generative models. Instead, we position it as a fundamental principle in generative modeling, critically influencing both model architecture and broader applications. Specifically, we contend that across vision, language, and multimodal systems, token reduction can: (i) facilitate deeper multimodal integration and alignment, (ii) mitigate "overthinking" and hallucinations, (iii) maintain coherence over long inputs, and (iv) enhance training stability, etc. We reframe token reduction as more than an efficiency measure. By doing so, we outline promising future directions, including algorithm design, reinforcement learning-guided token reduction, token optimization for in-context learning, and broader ML and scientific domains. We highlight its potential to drive new model architectures and learning strategies that improve robustness, increase interpretability, and better align with the objectives of generative modeling.
Structured Agent Distillation for Large Language Model
May 20, 2025



Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.
TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools
Mar 14, 2025Precision therapeutics require multimodal adaptive models that generate personalized treatment recommendations. We introduce TxAgent, an AI agent that leverages multi-step reasoning and real-time biomedical knowledge retrieval across a toolbox of 211 tools to analyze drug interactions, contraindications, and patient-specific treatment strategies. TxAgent evaluates how drugs interact at molecular, pharmacokinetic, and clinical levels, identifies contraindications based on patient comorbidities and concurrent medications, and tailors treatment strategies to individual patient characteristics. It retrieves and synthesizes evidence from multiple biomedical sources, assesses interactions between drugs and patient conditions, and refines treatment recommendations through iterative reasoning. It selects tools based on task objectives and executes structured function calls to solve therapeutic tasks that require clinical reasoning and cross-source validation. The ToolUniverse consolidates 211 tools from trusted sources, including all US FDA-approved drugs since 1939 and validated clinical insights from Open Targets. TxAgent outperforms leading LLMs, tool-use models, and reasoning agents across five new benchmarks: DrugPC, BrandPC, GenericPC, TreatmentPC, and DescriptionPC, covering 3,168 drug reasoning tasks and 456 personalized treatment scenarios. It achieves 92.1% accuracy in open-ended drug reasoning tasks, surpassing GPT-4o and outperforming DeepSeek-R1 (671B) in structured multi-step reasoning. TxAgent generalizes across drug name variants and descriptions. By integrating multi-step inference, real-time knowledge grounding, and tool-assisted decision-making, TxAgent ensures that treatment recommendations align with established clinical guidelines and real-world evidence, reducing the risk of adverse events and improving therapeutic decision-making.
RoRA: Efficient Fine-Tuning of LLM with Reliability Optimization for Rank Adaptation
Jan 08, 2025



Fine-tuning helps large language models (LLM) recover degraded information and enhance task performance.Although Low-Rank Adaptation (LoRA) is widely used and effective for fine-tuning, we have observed that its scaling factor can limit or even reduce performance as the rank size increases. To address this issue, we propose RoRA (Rank-adaptive Reliability Optimization), a simple yet effective method for optimizing LoRA's scaling factor. By replacing $\alpha/r$ with $\alpha/\sqrt{r}$, RoRA ensures improved performance as rank size increases. Moreover, RoRA enhances low-rank adaptation in fine-tuning uncompressed models and excels in the more challenging task of accuracy recovery when fine-tuning pruned models. Extensive experiments demonstrate the effectiveness of RoRA in fine-tuning both uncompressed and pruned models. RoRA surpasses the state-of-the-art (SOTA) in average accuracy and robustness on LLaMA-7B/13B, LLaMA2-7B, and LLaMA3-8B, specifically outperforming LoRA and DoRA by 6.5% and 2.9% on LLaMA-7B, respectively. In pruned model fine-tuning, RoRA shows significant advantages; for SHEARED-LLAMA-1.3, a LLaMA-7B with 81.4% pruning, RoRA achieves 5.7% higher average accuracy than LoRA and 3.9% higher than DoRA.