 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-Pruner: Pruning Mixture-of-Experts Large Language Model using the Hints from Its Router
Oct 15, 2024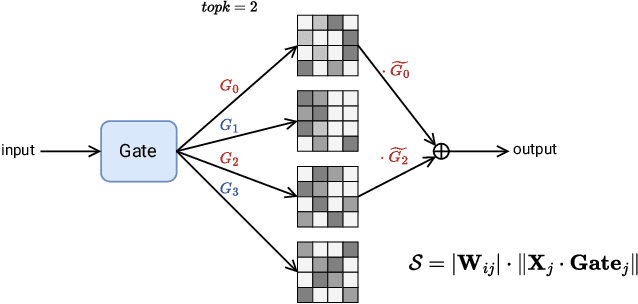

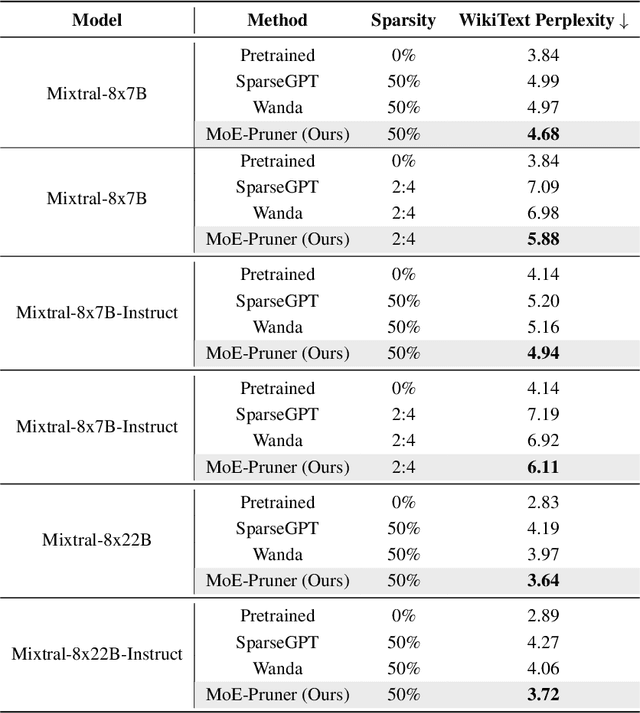
Mixture-of-Experts (MoE) architectures face challenges such as high memory consumption and redundancy in experts. Pruning MoE can reduce network weights while maintaining model performance. Motivated by the recent observation of emergent large magnitude features in Large Language Models (LLM) and MoE routing policy, we propose MoE-Pruner, a method that prunes weights with the smallest magnitudes multiplied by the corresponding input activations and router weights, on each output neuron. Our pruning method is one-shot, requiring no retraining or weight updates. We evaluate our method on Mixtral-8x7B and Mixtral-8x22B across multiple language benchmarks. Experimental results show that our pruning method significantly outperforms state-of-the-art LLM pruning methods. Furthermore, our pruned MoE models can benefit from a pretrained teacher model through expert-wise knowledge distillation, improving performance post-pruning. Experimental results demonstrate that the Mixtral-8x7B model with 50% sparsity maintains 99% of the performance of the original model after the expert-wise knowledge distillation.
Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers
Jul 25, 2024

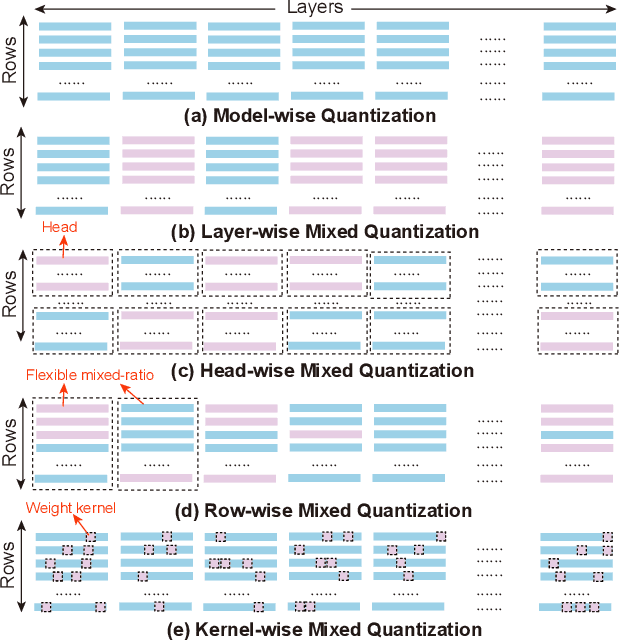

Vision transformers (ViTs) have demonstrated their superior accuracy for computer vision tasks compared to convolutional neural networks (CNNs). However, ViT models are often computation-intensive for efficient deployment on resource-limited edge devices. This work proposes Quasar-ViT, a hardware-oriented quantization-aware architecture search framework for ViTs, to design efficient ViT models for hardware implementation while preserving the accuracy. First, Quasar-ViT trains a supernet using our row-wise flexible mixed-precision quantization scheme, mixed-precision weight entanglement, and supernet layer scaling techniques. Then, it applies an efficient hardware-oriented search algorithm, integrated with hardware latency and resource modeling, to determine a series of optimal subnets from supernet under different inference latency targets. Finally, we propose a series of model-adaptive designs on the FPGA platform to support the architecture search and mitigate the gap between the theoretical computation reduction and the practical inference speedup. Our searched models achieve 101.5, 159.6, and 251.6 frames-per-second (FPS) inference speed on the AMD/Xilinx ZCU102 FPGA with 80.4%, 78.6%, and 74.9% top-1 accuracy, respectively, for the ImageNet dataset, consistently outperforming prior works.
HybridFlow: Infusing Continuity into Masked Codebook for Extreme Low-Bitrate Image Compression
Apr 20, 2024

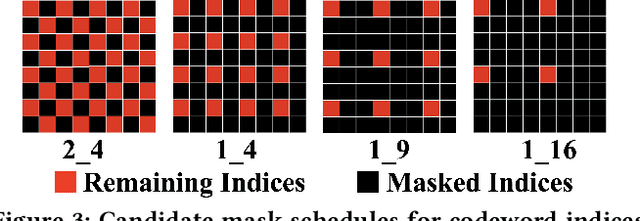

This paper investigates the challenging problem of learned image compression (LIC) with extreme low bitrates. Previous LIC methods based on transmitting quantized continuous features often yield blurry and noisy reconstruction due to the severe quantization loss. While previous LIC methods based on learned codebooks that discretize visual space usually give poor-fidelity reconstruction due to the insufficient representation power of limited codewords in capturing faithful details. We propose a novel dual-stream framework, HyrbidFlow, which combines the continuous-feature-based and codebook-based streams to achieve both high perceptual quality and high fidelity under extreme low bitrates. The codebook-based stream benefits from the high-quality learned codebook priors to provide high quality and clarity in reconstructed images. The continuous feature stream targets at maintaining fidelity details. To achieve the ultra low bitrate, a masked token-based transformer is further proposed, where we only transmit a masked portion of codeword indices and recover the missing indices through token generation guided by information from the continuous feature stream. We also develop a bridging correction network to merge the two streams in pixel decoding for final image reconstruction, where the continuous stream features rectify biases of the codebook-based pixel decoder to impose reconstructed fidelity details. Experimental results demonstrate superior performance across several datasets under extremely low bitrates, compared with existing single-stream codebook-based or continuous-feature-based LIC methods.
SupeRBNN: Randomized Binary Neural Network Using Adiabatic Superconductor Josephson Devices
Sep 21, 2023



Adiabatic Quantum-Flux-Parametron (AQFP) is a superconducting logic with extremely high energy efficiency. By employing the distinct polarity of current to denote logic `0' and `1', AQFP devices serve as excellent carriers for binary neural network (BNN) computations. Although recent research has made initial strides toward developing an AQFP-based BNN accelerator, several critical challenges remain, preventing the design from being a comprehensive solution. In this paper, we propose SupeRBNN, an AQFP-based randomized BNN acceleration framework that leverages software-hardware co-optimization to eventually make the AQFP devices a feasible solution for BNN acceleration. Specifically, we investigate the randomized behavior of the AQFP devices and analyze the impact of crossbar size on current attenuation, subsequently formulating the current amplitude into the values suitable for use in BNN computation. To tackle the accumulation problem and improve overall hardware performance, we propose a stochastic computing-based accumulation module and a clocking scheme adjustment-based circuit optimization method. We validate our SupeRBNN framework across various datasets and network architectures, comparing it with implementations based on different technologies, including CMOS, ReRAM, and superconducting RSFQ/ERSFQ. Experimental results demonstrate that our design achieves an energy efficiency of approximately 7.8x10^4 times higher than that of the ReRAM-based BNN framework while maintaining a similar level of model accuracy. Furthermore, when compared with superconductor-based counterparts, our framework demonstrates at least two orders of magnitude higher energy efficiency.
Peeling the Onion: Hierarchical Reduction of Data Redundancy for Efficient Vision Transformer Training
Nov 19, 2022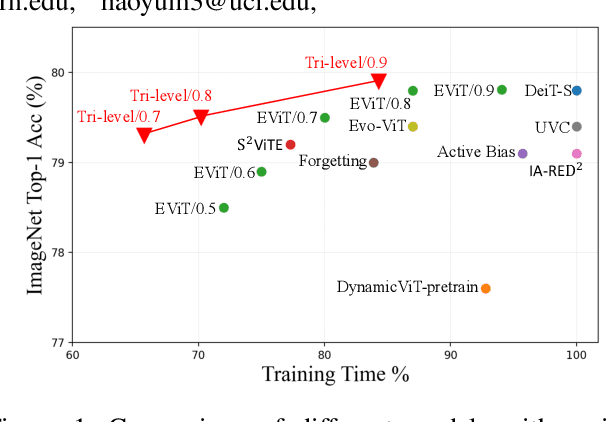
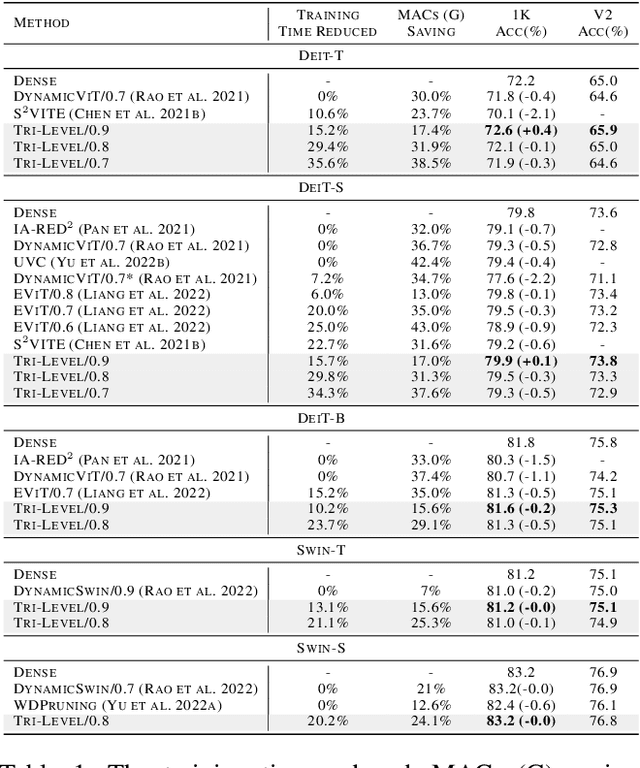


Vision transformers (ViTs) have recently obtained success in many applications, but their intensive computation and heavy memory usage at both training and inference time limit their generalization. Previous compression algorithms usually start from the pre-trained dense models and only focus on efficient inference, while time-consuming training is still unavoidable. In contrast, this paper points out that the million-scale training data is redundant, which is the fundamental reason for the tedious training. To address the issue, this paper aims to introduce sparsity into data and proposes an end-to-end efficient training framework from three sparse perspectives, dubbed Tri-Level E-ViT. Specifically, we leverage a hierarchical data redundancy reduction scheme, by exploring the sparsity under three levels: number of training examples in the dataset, number of patches (tokens) in each example, and number of connections between tokens that lie in attention weights. With extensive experiments, we demonstrate that our proposed technique can noticeably accelerate training for various ViT architectures while maintaining accuracy. Remarkably, under certain ratios, we are able to improve the ViT accuracy rather than compromising it. For example, we can achieve 15.2% speedup with 72.6% (+0.4) Top-1 accuracy on Deit-T, and 15.7% speedup with 79.9% (+0.1) Top-1 accuracy on Deit-S. This proves the existence of data redundancy in ViT.
HeatViT: Hardware-Efficient Adaptive Token Pruning for Vision Transformers
Nov 15, 2022



While vision transformers (ViTs) have continuously achieved new milestones in the field of computer vision, their sophisticated network architectures with high computation and memory costs have impeded their deployment on resource-limited edge devices. In this paper, we propose a hardware-efficient image-adaptive token pruning framework called HeatViT for efficient yet accurate ViT acceleration on embedded FPGAs. By analyzing the inherent computational patterns in ViTs, we first design an effective attention-based multi-head token selector, which can be progressively inserted before transformer blocks to dynamically identify and consolidate the non-informative tokens from input images. Moreover, we implement the token selector on hardware by adding miniature control logic to heavily reuse existing hardware components built for the backbone ViT. To improve the hardware efficiency, we further employ 8-bit fixed-point quantization, and propose polynomial approximations with regularization effect on quantization error for the frequently used nonlinear functions in ViTs. Finally, we propose a latency-aware multi-stage training strategy to determine the transformer blocks for inserting token selectors and optimize the desired (average) pruning rates for inserted token selectors, in order to improve both the model accuracy and inference latency on hardware. Compared to existing ViT pruning studies, under the similar computation cost, HeatViT can achieve 0.7%$\sim$8.9% higher accuracy; while under the similar model accuracy, HeatViT can achieve more than 28.4%$\sim$65.3% computation reduction, for various widely used ViTs, including DeiT-T, DeiT-S, DeiT-B, LV-ViT-S, and LV-ViT-M, on the ImageNet dataset. Compared to the baseline hardware accelerator, our implementations of HeatViT on the Xilinx ZCU102 FPGA achieve 3.46$\times$$\sim$4.89$\times$ speedup.
Auto-ViT-Acc: An FPGA-Aware Automatic Acceleration Framework for Vision Transformer with Mixed-Scheme Quantization
Aug 10, 2022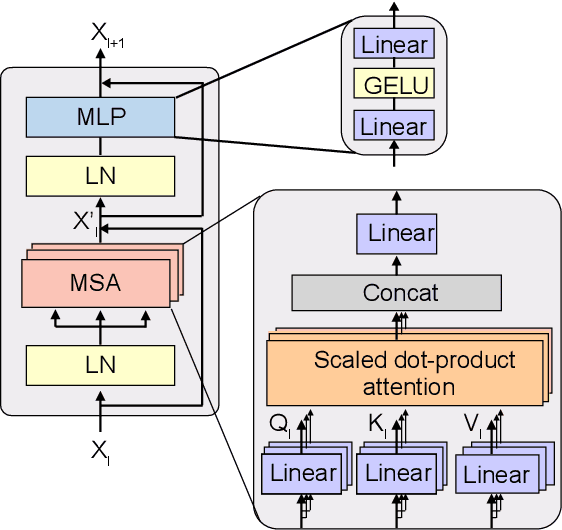
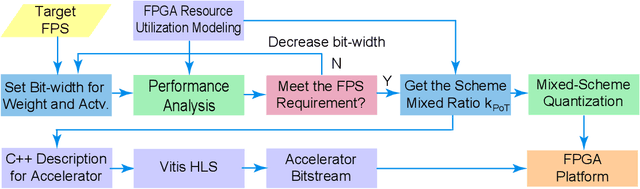
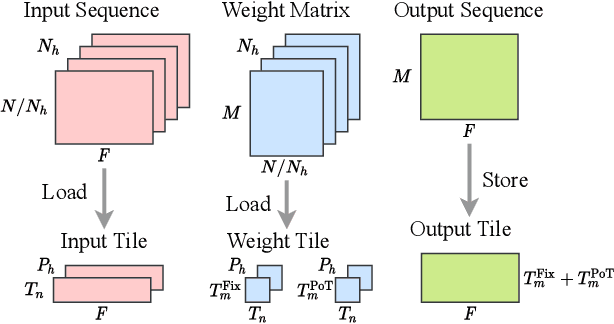
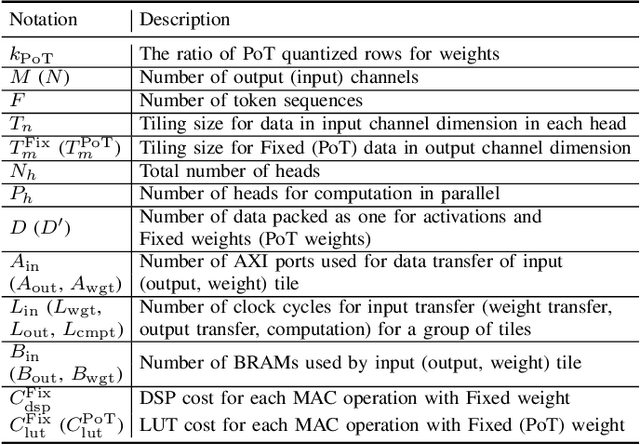
Vision transformers (ViTs) are emerging with significantly improved accuracy in computer vision tasks. However, their complex architecture and enormous computation/storage demand impose urgent needs for new hardware accelerator design methodology. This work proposes an FPGA-aware automatic ViT acceleration framework based on the proposed mixed-scheme quantization. To the best of our knowledge, this is the first FPGA-based ViT acceleration framework exploring model quantization. Compared with state-of-the-art ViT quantization work (algorithmic approach only without hardware acceleration), our quantization achieves 0.47% to 1.36% higher Top-1 accuracy under the same bit-width. Compared with the 32-bit floating-point baseline FPGA accelerator, our accelerator achieves around 5.6x improvement on the frame rate (i.e., 56.8 FPS vs. 10.0 FPS) with 0.71% accuracy drop on ImageNet dataset for DeiT-base.