 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Sign Momentum with Local Steps for Training Transformers
Nov 26, 2024Pre-training Transformer models is resource-intensive, and recent studies have shown that sign momentum is an efficient technique for training large-scale deep learning models, particularly Transformers. However, its application in distributed training or federated learning remains underexplored. This paper investigates a novel communication-efficient distributed sign momentum method with local updates. Our proposed method allows for a broad class of base optimizers for local updates, and uses sign momentum in global updates, where momentum is generated from differences accumulated during local steps. We evaluate our method on the pre-training of various GPT-2 models, and the empirical results show significant improvement compared to other distributed methods with local updates. Furthermore, by approximating the sign operator with a randomized version that acts as a continuous analog in expectation, we present an $O(1/\sqrt{T})$ convergence for one instance of the proposed method for nonconvex smooth functions.
MoE-Pruner: Pruning Mixture-of-Experts Large Language Model using the Hints from Its Router
Oct 15, 2024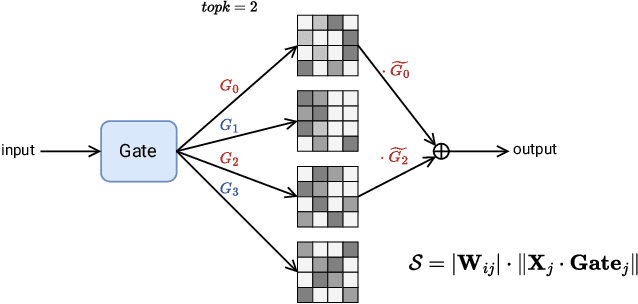

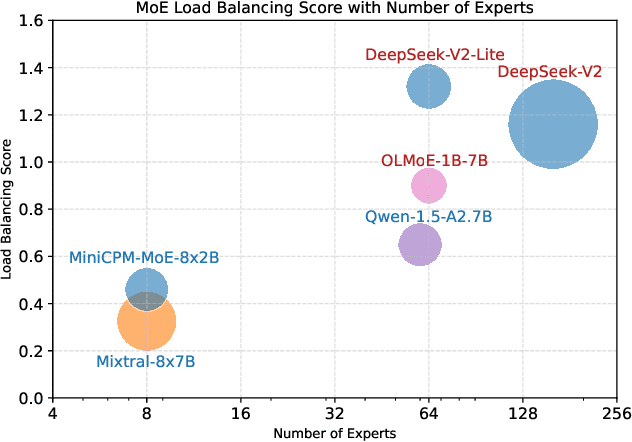
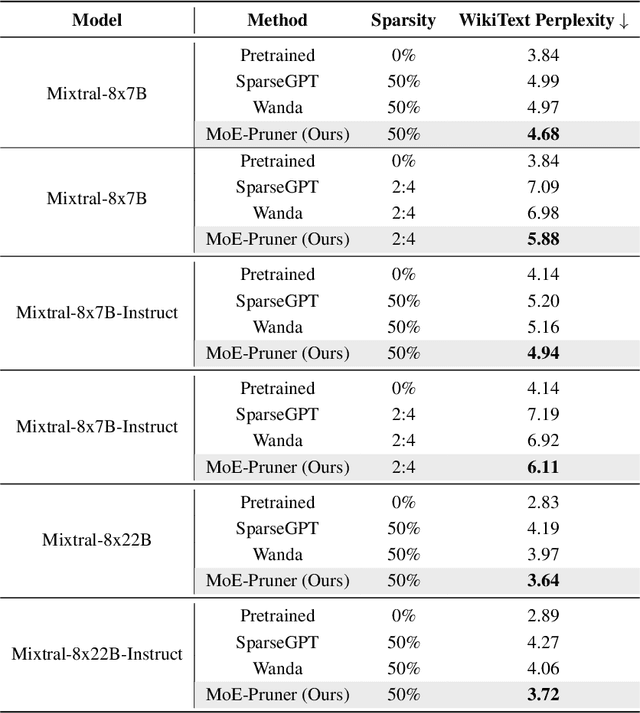
Mixture-of-Experts (MoE) architectures face challenges such as high memory consumption and redundancy in experts. Pruning MoE can reduce network weights while maintaining model performance. Motivated by the recent observation of emergent large magnitude features in Large Language Models (LLM) and MoE routing policy, we propose MoE-Pruner, a method that prunes weights with the smallest magnitudes multiplied by the corresponding input activations and router weights, on each output neuron. Our pruning method is one-shot, requiring no retraining or weight updates. We evaluate our method on Mixtral-8x7B and Mixtral-8x22B across multiple language benchmarks. Experimental results show that our pruning method significantly outperforms state-of-the-art LLM pruning methods. Furthermore, our pruned MoE models can benefit from a pretrained teacher model through expert-wise knowledge distillation, improving performance post-pruning. Experimental results demonstrate that the Mixtral-8x7B model with 50% sparsity maintains 99% of the performance of the original model after the expert-wise knowledge distillation.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Feb 23, 2024



We present the design, implementation and engineering experience in building and deploying MegaScale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs. Training LLMs at this scale brings unprecedented challenges to training efficiency and stability. We take a full-stack approach that co-designs the algorithmic and system components across model block and optimizer design, computation and communication overlapping, operator optimization, data pipeline, and network performance tuning. Maintaining high efficiency throughout the training process (i.e., stability) is an important consideration in production given the long extent of LLM training jobs. Many hard stability issues only emerge at large scale, and in-depth observability is the key to address them. We develop a set of diagnosis tools to monitor system components and events deep in the stack, identify root causes, and derive effective techniques to achieve fault tolerance and mitigate stragglers. MegaScale achieves 55.2% Model FLOPs Utilization (MFU) when training a 175B LLM model on 12,288 GPUs, improving the MFU by 1.34x compared to Megatron-LM. We share our operational experience in identifying and fixing failures and stragglers. We hope by articulating the problems and sharing our experience from a systems perspective, this work can inspire future LLM systems research.
Video-CSR: Complex Video Digest Creation for Visual-Language Models
Oct 08, 2023



We present a novel task and human annotated dataset for evaluating the ability for visual-language models to generate captions and summaries for real-world video clips, which we call Video-CSR (Captioning, Summarization and Retrieval). The dataset contains 4.8K YouTube video clips of 20-60 seconds in duration and covers a wide range of topics and interests. Each video clip corresponds to 5 independently annotated captions (1 sentence) and summaries (3-10 sentences). Given any video selected from the dataset and its corresponding ASR information, we evaluate visual-language models on either caption or summary generation that is grounded in both the visual and auditory content of the video. Additionally, models are also evaluated on caption- and summary-based retrieval tasks, where the summary-based retrieval task requires the identification of a target video given excerpts of a corresponding summary. Given the novel nature of the paragraph-length video summarization task, we perform extensive comparative analyses of different existing evaluation metrics and their alignment with human preferences. Finally, we propose a foundation model with competitive generation and retrieval capabilities that serves as a baseline for the Video-CSR task. We aim for Video-CSR to serve as a useful evaluation set in the age of large language models and complex multi-modal tasks.
Revisiting Multimodal Representation in Contrastive Learning: From Patch and Token Embeddings to Finite Discrete Tokens
Mar 27, 2023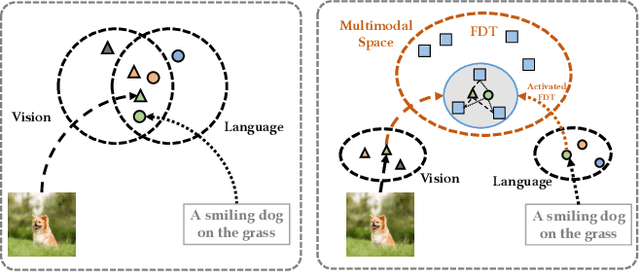

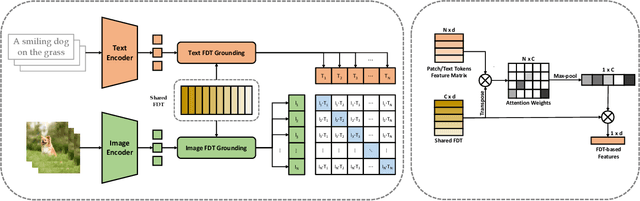

Contrastive learning-based vision-language pre-training approaches, such as CLIP, have demonstrated great success in many vision-language tasks. These methods achieve cross-modal alignment by encoding a matched image-text pair with similar feature embeddings, which are generated by aggregating information from visual patches and language tokens. However, direct aligning cross-modal information using such representations is challenging, as visual patches and text tokens differ in semantic levels and granularities. To alleviate this issue, we propose a Finite Discrete Tokens (FDT) based multimodal representation. FDT is a set of learnable tokens representing certain visual-semantic concepts. Both images and texts are embedded using shared FDT by first grounding multimodal inputs to FDT space and then aggregating the activated FDT representations. The matched visual and semantic concepts are enforced to be represented by the same set of discrete tokens by a sparse activation constraint. As a result, the granularity gap between the two modalities is reduced. Through both quantitative and qualitative analyses, we demonstrate that using FDT representations in CLIP-style models improves cross-modal alignment and performance in visual recognition and vision-language downstream tasks. Furthermore, we show that our method can learn more comprehensive representations, and the learned FDT capture meaningful cross-modal correspondence, ranging from objects to actions and attributes.
Learning identifiable and interpretable latent models of high-dimensional neural activity using pi-VAE
Nov 09, 2020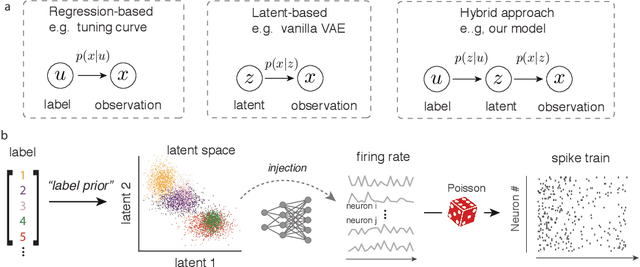
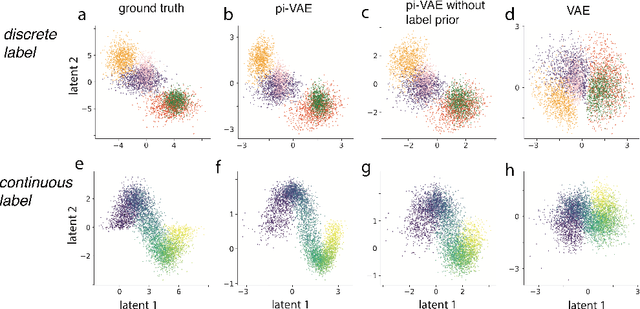
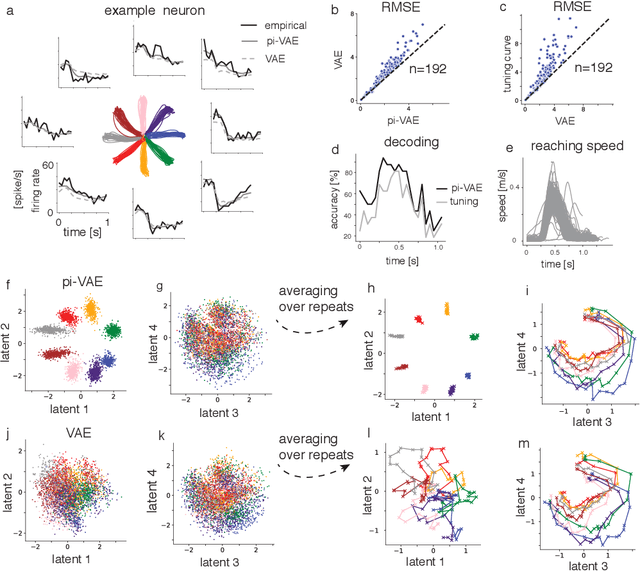
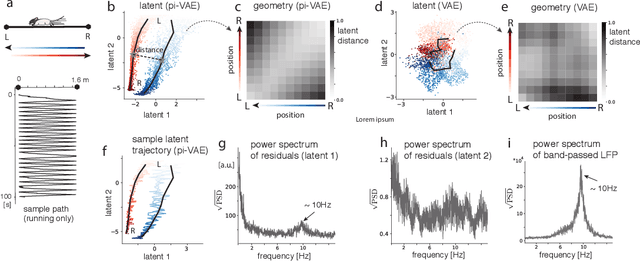
The ability to record activities from hundreds of neurons simultaneously in the brain has placed an increasing demand for developing appropriate statistical techniques to analyze such data. Recently, deep generative models have been proposed to fit neural population responses. While these methods are flexible and expressive, the downside is that they can be difficult to interpret and identify. To address this problem, we propose a method that integrates key ingredients from latent models and traditional neural encoding models. Our method, pi-VAE, is inspired by recent progress on identifiable variational auto-encoder, which we adapt to make appropriate for neuroscience applications. Specifically, we propose to construct latent variable models of neural activity while simultaneously modeling the relation between the latent and task variables (non-neural variables, e.g. sensory, motor, and other externally observable states). The incorporation of task variables results in models that are not only more constrained, but also show qualitative improvements in interpretability and identifiability. We validate pi-VAE using synthetic data, and apply it to analyze neurophysiological datasets from rat hippocampus and macaque motor cortex. We demonstrate that pi-VAE not only fits the data better, but also provides unexpected novel insights into the structure of the neural codes.
A zero-inflated gamma model for deconvolved calcium imaging traces
Jun 05, 2020Calcium imaging is a critical tool for measuring the activity of large neural populations. Much effort has been devoted to developing "pre-processing" tools for calcium video data, addressing the important issues of e.g., motion correction, denoising, compression, demixing, and deconvolution. However, statistical modeling of deconvolved calcium signals (i.e., the estimated activity extracted by a pre-processing pipeline) is just as critical for interpreting calcium measurements, and for incorporating these observations into downstream probabilistic encoding and decoding models. Surprisingly, these issues have to date received significantly less attention. In this work we examine the statistical properties of the deconvolved activity estimates, and compare probabilistic models for these random signals. In particular, we propose a zero-inflated gamma (ZIG) model, which characterizes the calcium responses as a mixture of a gamma distribution and a point mass that serves to model zero responses. We apply the resulting models to neural encoding and decoding problems. We find that the ZIG model outperforms simpler models (e.g., Poisson or Bernoulli models) in the context of both simulated and real neural data, and can therefore play a useful role in bridging calcium imaging analysis methods with tools for analyzing activity in large neural populations.
* Accepted for publication in Neurons, Behavior, Data analysis, and Theory
Disentangled sticky hierarchical Dirichlet process hidden Markov model
Apr 06, 2020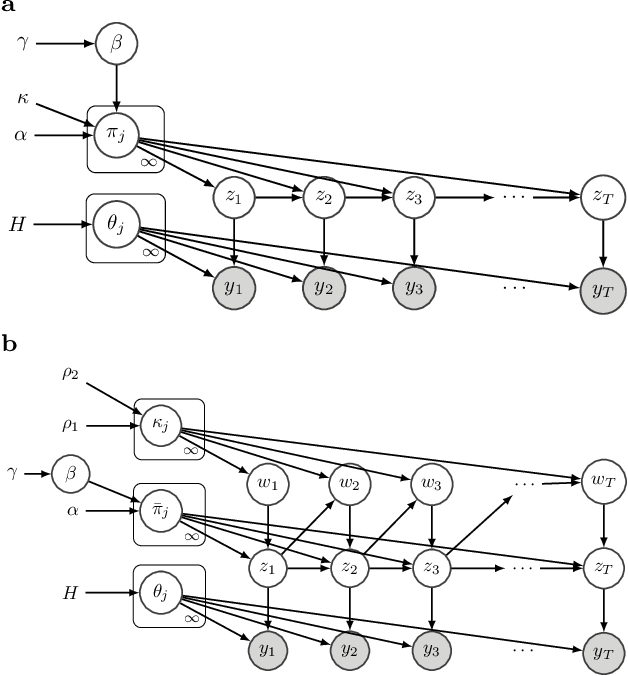

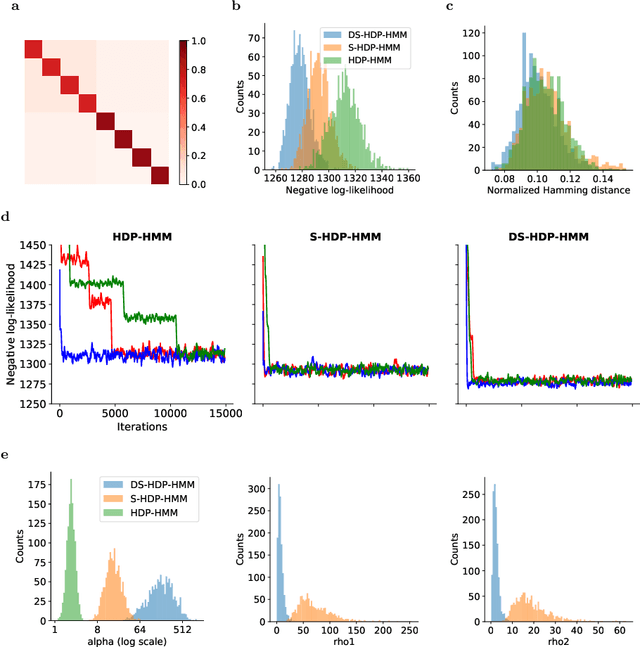
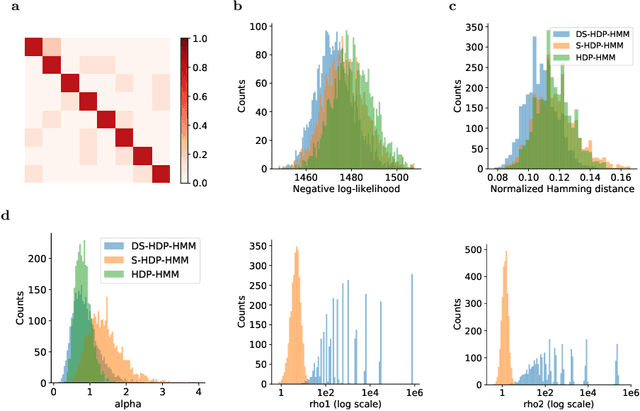
The Hierarchical Dirichlet Process Hidden Markov Model (HDP-HMM) has been used widely as a natural Bayesian nonparametric extension of the classical Hidden Markov Model for learning from sequential and time-series data. A sticky extension of the HDP-HMM has been proposed to strengthen the self-persistence probability in the HDP-HMM. However, the sticky HDP-HMM entangles the strength of the self-persistence prior and transition prior together, limiting its expressiveness. Here, we propose a more general model: the disentangled sticky HDP-HMM (DS-HDP-HMM). We develop novel Gibbs sampling algorithms for efficient inference in this model. We show that the disentangled sticky HDP-HMM outperforms the sticky HDP-HMM and HDP-HMM on both synthetic and real data, and apply the new approach to analyze neural data and segment behavioral video data.
Penalized matrix decomposition for denoising, compression, and improved demixing of functional imaging data
Jul 17, 2018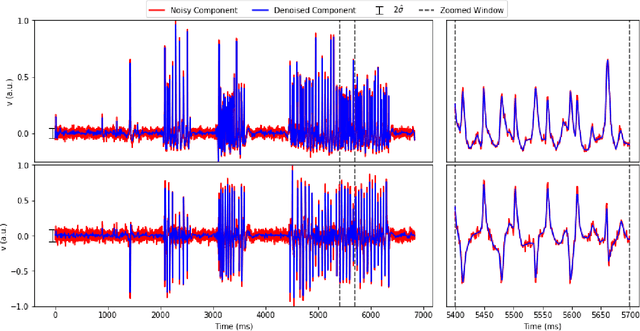
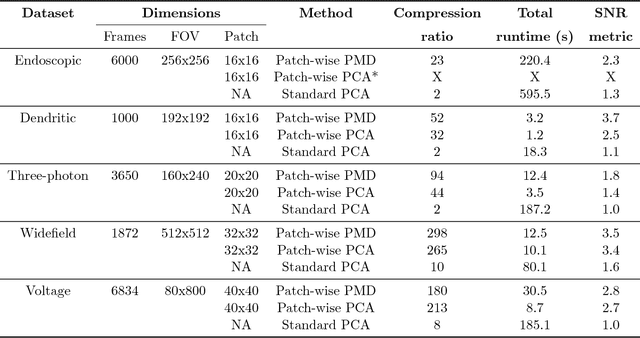

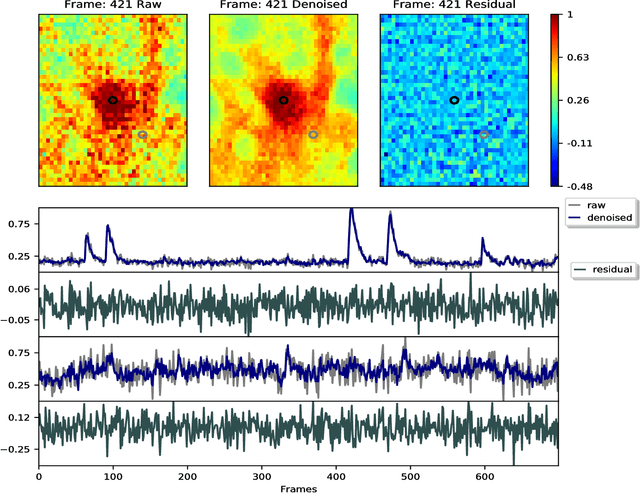
Calcium imaging has revolutionized systems neuroscience, providing the ability to image large neural populations with single-cell resolution. The resulting datasets are quite large, which has presented a barrier to routine open sharing of this data, slowing progress in reproducible research. State of the art methods for analyzing this data are based on non-negative matrix factorization (NMF); these approaches solve a non-convex optimization problem, and are effective when good initializations are available, but can break down in low-SNR settings where common initialization approaches fail. Here we introduce an approach to compressing and denoising functional imaging data. The method is based on a spatially-localized penalized matrix decomposition (PMD) of the data to separate (low-dimensional) signal from (temporally-uncorrelated) noise. This approach can be applied in parallel on local spatial patches and is therefore highly scalable, does not impose non-negativity constraints or require stringent identifiability assumptions (leading to significantly more robust results compared to NMF), and estimates all parameters directly from the data, so no hand-tuning is required. We have applied the method to a wide range of functional imaging data (including one-photon, two-photon, three-photon, widefield, somatic, axonal, dendritic, calcium, and voltage imaging datasets): in all cases, we observe ~2-4x increases in SNR and compression rates of 20-300x with minimal visible loss of signal, with no adjustment of hyperparameters; this in turn facilitates the process of demixing the observed activity into contributions from individual neurons. We focus on two challenging applications: dendritic calcium imaging data and voltage imaging data in the context of optogenetic stimulation. In both cases, we show that our new approach leads to faster and much more robust extraction of activity from the data.