 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness study of the bio-inspired musculoskeletal arm robot based on the data-driven iterative learning algorithm
Nov 08, 2025The human arm exhibits remarkable capabilities, including both explosive power and precision, which demonstrate dexterity, compliance, and robustness in unstructured environments. Developing robotic systems that emulate human-like operational characteristics through musculoskeletal structures has long been a research focus. In this study, we designed a novel lightweight tendon-driven musculoskeletal arm (LTDM-Arm), featuring a seven degree-of-freedom (DOF) skeletal joint system and a modularized artificial muscular system (MAMS) with 15 actuators. Additionally, we employed a Hilly-type muscle model and data-driven iterative learning control (DDILC) to learn and refine activation signals for repetitive tasks within a finite time frame. We validated the anti-interference capabilities of the musculoskeletal system through both simulations and experiments. The results show that the LTDM-Arm system can effectively achieve desired trajectory tracking tasks, even under load disturbances of 20 % in simulation and 15 % in experiments. This research lays the foundation for developing advanced robotic systems with human-like operational performance.
* 20 pages, 13 figures
Development of the Bioinspired Tendon-Driven DexHand 021 with Proprioceptive Compliance Control
Nov 05, 2025The human hand plays a vital role in daily life and industrial applications, yet replicating its multifunctional capabilities-including motion, sensing, and coordinated manipulation-with robotic systems remains a formidable challenge. Developing a dexterous robotic hand requires balancing human-like agility with engineering constraints such as complexity, size-to-weight ratio, durability, and force-sensing performance. This letter presents Dex-Hand 021, a high-performance, cable-driven five-finger robotic hand with 12 active and 7 passive degrees of freedom (DoFs), achieving 19 DoFs dexterity in a lightweight 1 kg design. We propose a proprioceptive force-sensing-based admittance control method to enhance manipulation. Experimental results demonstrate its superior performance: a single-finger load capacity exceeding 10 N, fingertip repeatability under 0.001 m, and force estimation errors below 0.2 N. Compared to PID control, joint torques in multi-object grasping are reduced by 31.19%, significantly improves force-sensing capability while preventing overload during collisions. The hand excels in both power and precision grasps, successfully executing 33 GRASP taxonomy motions and complex manipulation tasks. This work advances the design of lightweight, industrial-grade dexterous hands and enhances proprioceptive control, contributing to robotic manipulation and intelligent manufacturing.
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
May 29, 2025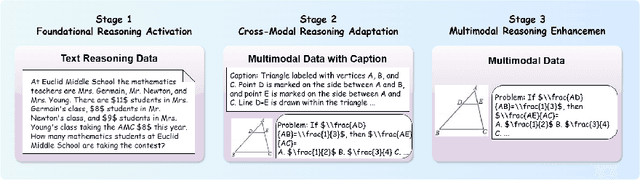
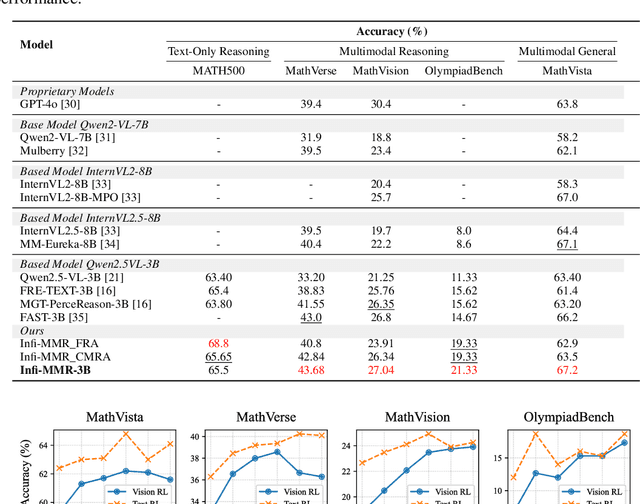
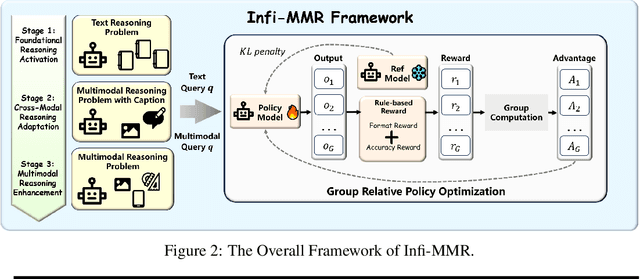
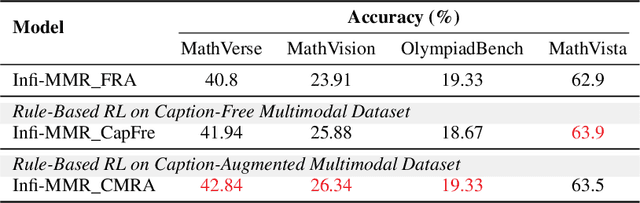
Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model's logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).
InfiR : Crafting Effective Small Language Models and Multimodal Small Language Models in Reasoning
Feb 17, 2025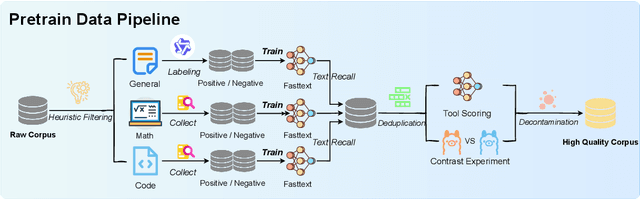

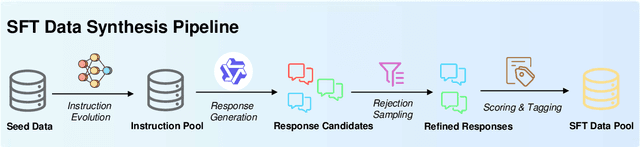

Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have made significant advancements in reasoning capabilities. However, they still face challenges such as high computational demands and privacy concerns. This paper focuses on developing efficient Small Language Models (SLMs) and Multimodal Small Language Models (MSLMs) that retain competitive reasoning abilities. We introduce a novel training pipeline that enhances reasoning capabilities and facilitates deployment on edge devices, achieving state-of-the-art performance while minimizing development costs. \InfR~ aims to advance AI systems by improving reasoning, reducing adoption barriers, and addressing privacy concerns through smaller model sizes. Resources are available at https://github. com/Reallm-Labs/InfiR.
Unconstrained Model Merging for Enhanced LLM Reasoning
Oct 17, 2024



Recent advancements in building domain-specific large language models (LLMs) have shown remarkable success, especially in tasks requiring reasoning abilities like logical inference over complex relationships and multi-step problem solving. However, creating a powerful all-in-one LLM remains challenging due to the need for proprietary data and vast computational resources. As a resource-friendly alternative, we explore the potential of merging multiple expert models into a single LLM. Existing studies on model merging mainly focus on generalist LLMs instead of domain experts, or the LLMs under the same architecture and size. In this work, we propose an unconstrained model merging framework that accommodates both homogeneous and heterogeneous model architectures with a focus on reasoning tasks. A fine-grained layer-wise weight merging strategy is designed for homogeneous models merging, while heterogeneous model merging is built upon the probabilistic distribution knowledge derived from instruction-response fine-tuning data. Across 7 benchmarks and 9 reasoning-optimized LLMs, we reveal key findings that combinatorial reasoning emerges from merging which surpasses simple additive effects. We propose that unconstrained model merging could serve as a foundation for decentralized LLMs, marking a notable progression from the existing centralized LLM framework. This evolution could enhance wider participation and stimulate additional advancement in the field of artificial intelligence, effectively addressing the constraints posed by centralized models.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.
Law of Vision Representation in MLLMs
Aug 29, 2024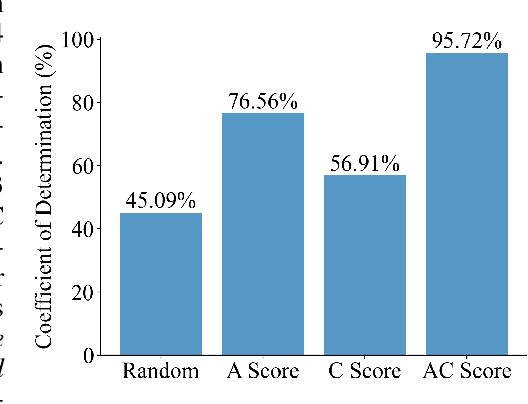
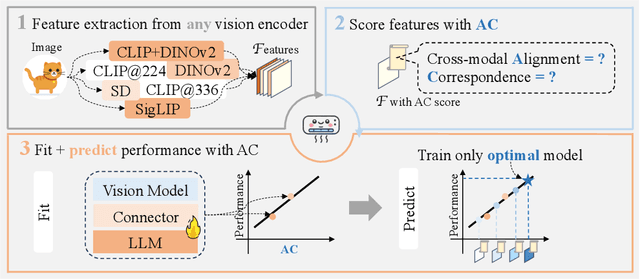

We present the "Law of Vision Representation" in multimodal large language models (MLLMs). It reveals a strong correlation between the combination of cross-modal alignment, correspondence in vision representation, and MLLM performance. We quantify the two factors using the cross-modal Alignment and Correspondence score (AC score). Through extensive experiments involving thirteen different vision representation settings and evaluations across eight benchmarks, we find that the AC score is linearly correlated to model performance. By leveraging this relationship, we are able to identify and train the optimal vision representation only, which does not require finetuning the language model every time, resulting in a 99.7% reduction in computational cost.
An Expert is Worth One Token: Synergizing Multiple Expert LLMs as Generalist via Expert Token Routing
Mar 25, 2024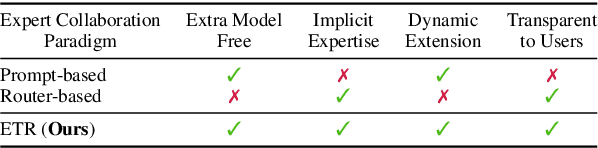
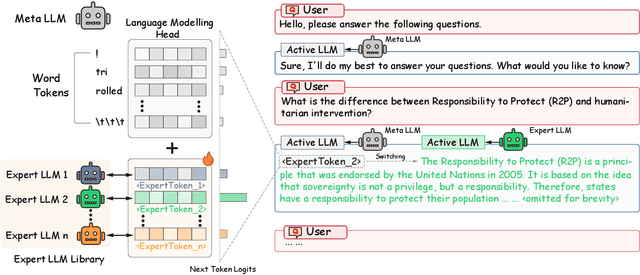
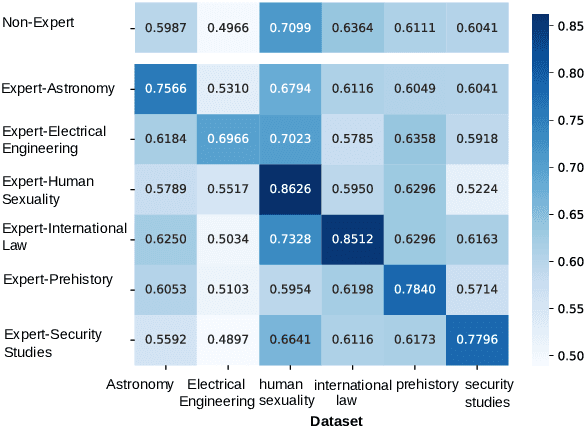
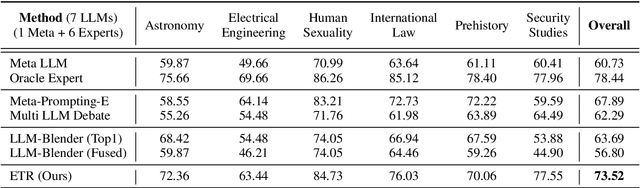
We present Expert-Token-Routing, a unified generalist framework that facilitates seamless integration of multiple expert LLMs. Our framework represents expert LLMs as special expert tokens within the vocabulary of a meta LLM. The meta LLM can route to an expert LLM like generating new tokens. Expert-Token-Routing not only supports learning the implicit expertise of expert LLMs from existing instruction dataset but also allows for dynamic extension of new expert LLMs in a plug-and-play manner. It also conceals the detailed collaboration process from the user's perspective, facilitating interaction as though it were a singular LLM. Our framework outperforms various existing multi-LLM collaboration paradigms across benchmarks that incorporate six diverse expert domains, demonstrating effectiveness and robustness in building generalist LLM system via synergizing multiple expert LLMs.
How Can LLM Guide RL? A Value-Based Approach
Feb 25, 2024
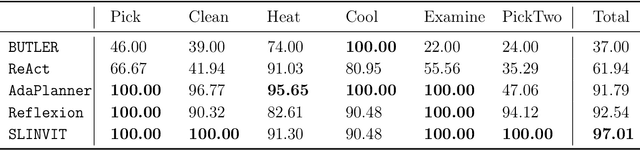

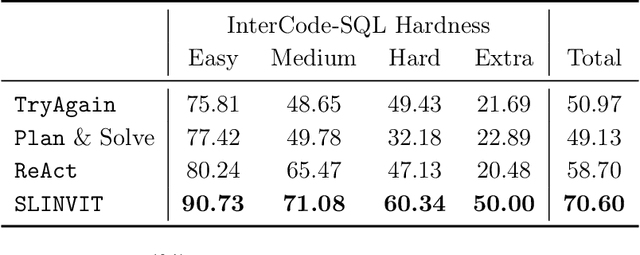
Reinforcement learning (RL) has become the de facto standard practice for sequential decision-making problems by improving future acting policies with feedback. However, RL algorithms may require extensive trial-and-error interactions to collect useful feedback for improvement. On the other hand, recent developments in large language models (LLMs) have showcased impressive capabilities in language understanding and generation, yet they fall short in exploration and self-improvement capabilities for planning tasks, lacking the ability to autonomously refine their responses based on feedback. Therefore, in this paper, we study how the policy prior provided by the LLM can enhance the sample efficiency of RL algorithms. Specifically, we develop an algorithm named LINVIT that incorporates LLM guidance as a regularization factor in value-based RL, leading to significant reductions in the amount of data needed for learning, particularly when the difference between the ideal policy and the LLM-informed policy is small, which suggests that the initial policy is close to optimal, reducing the need for further exploration. Additionally, we present a practical algorithm SLINVIT that simplifies the construction of the value function and employs subgoals to reduce the search complexity. Our experiments across three interactive environments ALFWorld, InterCode, and BlocksWorld demonstrate that our method achieves state-of-the-art success rates and also surpasses previous RL and LLM approaches in terms of sample efficiency. Our code is available at https://github.com/agentification/Language-Integrated-VI.
Exploring the Reasoning Abilities of Multimodal Large Language Models (MLLMs): A Comprehensive Survey on Emerging Trends in Multimodal Reasoning
Jan 18, 2024



Strong Artificial Intelligence (Strong AI) or Artificial General Intelligence (AGI) with abstract reasoning ability is the goal of next-generation AI. Recent advancements in Large Language Models (LLMs), along with the emerging field of Multimodal Large Language Models (MLLMs), have demonstrated impressive capabilities across a wide range of multimodal tasks and applications. Particularly, various MLLMs, each with distinct model architectures, training data, and training stages, have been evaluated across a broad range of MLLM benchmarks. These studies have, to varying degrees, revealed different aspects of the current capabilities of MLLMs. However, the reasoning abilities of MLLMs have not been systematically investigated. In this survey, we comprehensively review the existing evaluation protocols of multimodal reasoning, categorize and illustrate the frontiers of MLLMs, introduce recent trends in applications of MLLMs on reasoning-intensive tasks, and finally discuss current practices and future directions. We believe our survey establishes a solid base and sheds light on this important topic, multimodal reasoning.