 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiMM-Eval: Complex Open-Ended Reasoning Evaluation For Multi-Modal Large Language Models
Paper and Code

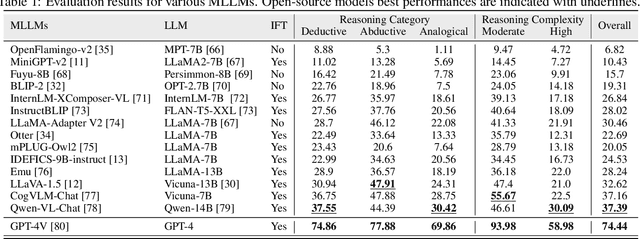
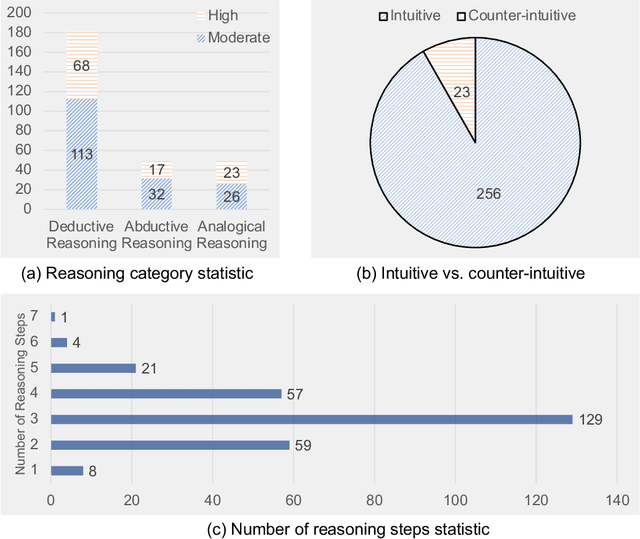
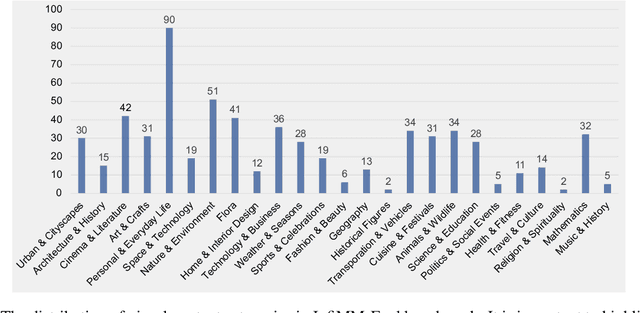
Multi-modal Large Language Models (MLLMs) are increasingly prominent in the field of artificial intelligence. These models not only excel in traditional vision-language tasks but also demonstrate impressive performance in contemporary multi-modal benchmarks. Although many of these benchmarks attempt to holistically evaluate MLLMs, they typically concentrate on basic reasoning tasks, often yielding only simple yes/no or multi-choice responses. These methods naturally lead to confusion and difficulties in conclusively determining the reasoning capabilities of MLLMs. To mitigate this issue, we manually curate a benchmark dataset specifically designed for MLLMs, with a focus on complex reasoning tasks. Our benchmark comprises three key reasoning categories: deductive, abductive, and analogical reasoning. The queries in our dataset are intentionally constructed to engage the reasoning capabilities of MLLMs in the process of generating answers. For a fair comparison across various MLLMs, we incorporate intermediate reasoning steps into our evaluation criteria. In instances where an MLLM is unable to produce a definitive answer, its reasoning ability is evaluated by requesting intermediate reasoning steps. If these steps align with our manual annotations, appropriate scores are assigned. This evaluation scheme resembles methods commonly used in human assessments, such as exams or assignments, and represents what we consider a more effective assessment technique compared with existing benchmarks. We evaluate a selection of representative MLLMs using this rigorously developed open-ended multi-step elaborate reasoning benchmark, designed to challenge and accurately measure their reasoning capabilities. The code and data will be released at https://infimm.github.io/InfiMM-Eval/