 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENTER: Event Based Interpretable Reasoning for VideoQA
Jan 24, 2025



In this paper, we present ENTER, an interpretable Video Question Answering (VideoQA) system based on event graphs. Event graphs convert videos into graphical representations, where video events form the nodes and event-event relationships (temporal/causal/hierarchical) form the edges. This structured representation offers many benefits: 1) Interpretable VideoQA via generated code that parses event-graph; 2) Incorporation of contextual visual information in the reasoning process (code generation) via event graphs; 3) Robust VideoQA via Hierarchical Iterative Update of the event graphs. Existing interpretable VideoQA systems are often top-down, disregarding low-level visual information in the reasoning plan generation, and are brittle. While bottom-up approaches produce responses from visual data, they lack interpretability. Experimental results on NExT-QA, IntentQA, and EgoSchema demonstrate that not only does our method outperform existing top-down approaches while obtaining competitive performance against bottom-up approaches, but more importantly, offers superior interpretability and explainability in the reasoning process.
PuzzleGPT: Emulating Human Puzzle-Solving Ability for Time and Location Prediction
Jan 24, 2025



The task of predicting time and location from images is challenging and requires complex human-like puzzle-solving ability over different clues. In this work, we formalize this ability into core skills and implement them using different modules in an expert pipeline called PuzzleGPT. PuzzleGPT consists of a perceiver to identify visual clues, a reasoner to deduce prediction candidates, a combiner to combinatorially combine information from different clues, a web retriever to get external knowledge if the task can't be solved locally, and a noise filter for robustness. This results in a zero-shot, interpretable, and robust approach that records state-of-the-art performance on two datasets -- TARA and WikiTilo. PuzzleGPT outperforms large VLMs such as BLIP-2, InstructBLIP, LLaVA, and even GPT-4V, as well as automatically generated reasoning pipelines like VisProg, by at least 32% and 38%, respectively. It even rivals or surpasses finetuned models.
Unveiling Narrative Reasoning Limits of Large Language Models with Trope in Movie Synopses
Sep 22, 2024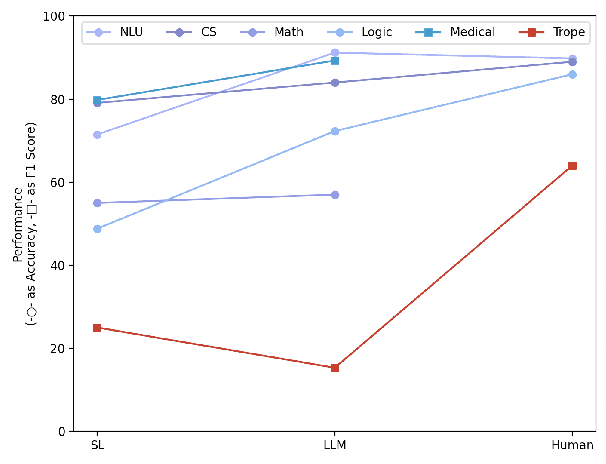


Large language models (LLMs) equipped with chain-of-thoughts (CoT) prompting have shown significant multi-step reasoning capabilities in factual content like mathematics, commonsense, and logic. However, their performance in narrative reasoning, which demands greater abstraction capabilities, remains unexplored. This study utilizes tropes in movie synopses to assess the abstract reasoning abilities of state-of-the-art LLMs and uncovers their low performance. We introduce a trope-wise querying approach to address these challenges and boost the F1 score by 11.8 points. Moreover, while prior studies suggest that CoT enhances multi-step reasoning, this study shows CoT can cause hallucinations in narrative content, reducing GPT-4's performance. We also introduce an Adversarial Injection method to embed trope-related text tokens into movie synopses without explicit tropes, revealing CoT's heightened sensitivity to such injections. Our comprehensive analysis provides insights for future research directions.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


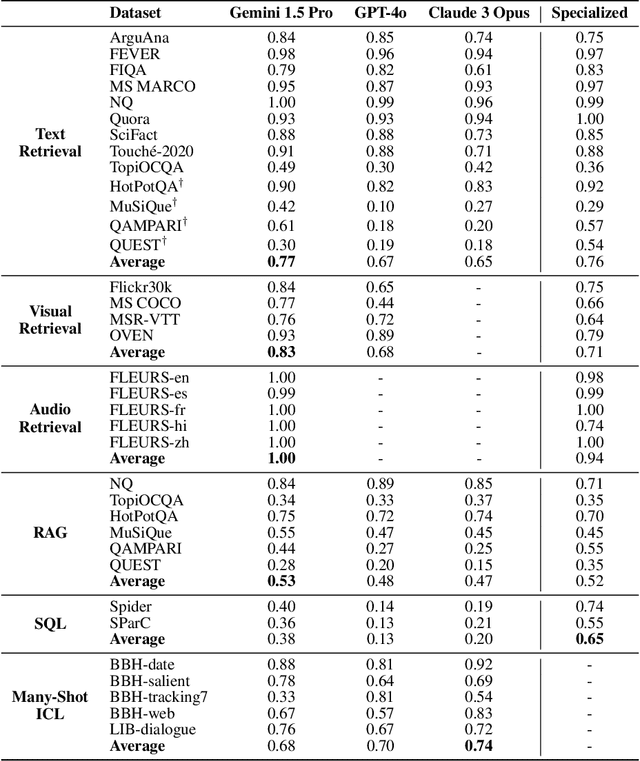
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
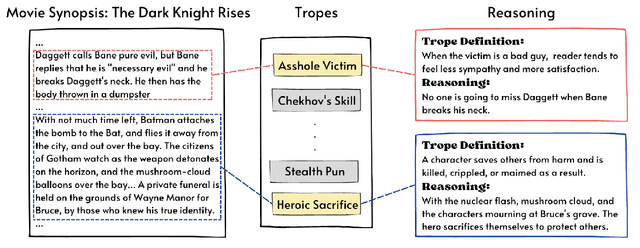
Investigating Video Reasoning Capability of Large Language Models with Tropes in Movies
Jun 16, 2024



Large Language Models (LLMs) have demonstrated effectiveness not only in language tasks but also in video reasoning. This paper introduces a novel dataset, Tropes in Movies (TiM), designed as a testbed for exploring two critical yet previously overlooked video reasoning skills: (1) Abstract Perception: understanding and tokenizing abstract concepts in videos, and (2) Long-range Compositional Reasoning: planning and integrating intermediate reasoning steps for understanding long-range videos with numerous frames. Utilizing tropes from movie storytelling, TiM evaluates the reasoning capabilities of state-of-the-art LLM-based approaches. Our experiments show that current methods, including Captioner-Reasoner, Large Multimodal Model Instruction Fine-tuning, and Visual Programming, only marginally outperform a random baseline when tackling the challenges of Abstract Perception and Long-range Compositional Reasoning. To address these deficiencies, we propose Face-Enhanced Viper of Role Interactions (FEVoRI) and Context Query Reduction (ConQueR), which enhance Visual Programming by fostering role interaction awareness and progressively refining movie contexts and trope queries during reasoning processes, significantly improving performance by 15 F1 points. However, this performance still lags behind human levels (40 vs. 65 F1). Additionally, we introduce a new protocol to evaluate the necessity of Abstract Perception and Long-range Compositional Reasoning for task resolution. This is done by analyzing the code generated through Visual Programming using an Abstract Syntax Tree (AST), thereby confirming the increased complexity of TiM. The dataset and code are available at: https://ander1119.github.io/TiM
BLINK: Multimodal Large Language Models Can See but Not Perceive
Apr 18, 2024



We introduce Blink, a new benchmark for multimodal language models (LLMs) that focuses on core visual perception abilities not found in other evaluations. Most of the Blink tasks can be solved by humans "within a blink" (e.g., relative depth estimation, visual correspondence, forensics detection, and multi-view reasoning). However, we find these perception-demanding tasks cast significant challenges for current multimodal LLMs because they resist mediation through natural language. Blink reformats 14 classic computer vision tasks into 3,807 multiple-choice questions, paired with single or multiple images and visual prompting. While humans get 95.70% accuracy on average, Blink is surprisingly challenging for existing multimodal LLMs: even the best-performing GPT-4V and Gemini achieve accuracies of 51.26% and 45.72%, only 13.17% and 7.63% higher than random guessing, indicating that such perception abilities have not "emerged" yet in recent multimodal LLMs. Our analysis also highlights that specialist CV models could solve these problems much better, suggesting potential pathways for future improvements. We believe Blink will stimulate the community to help multimodal LLMs catch up with human-level visual perception.
SCHEMA: State CHangEs MAtter for Procedure Planning in Instructional Videos
Mar 03, 2024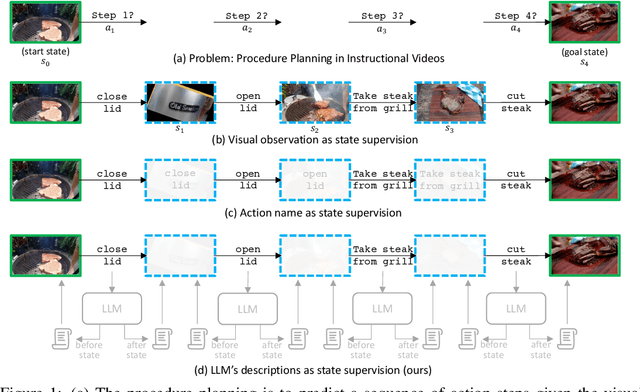
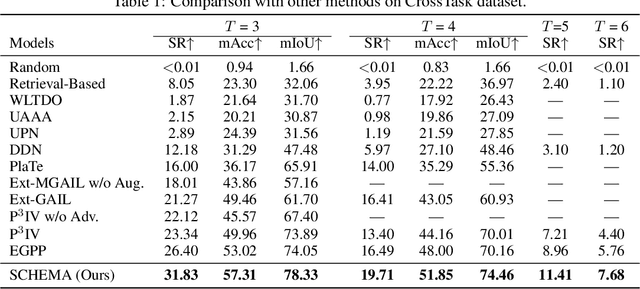

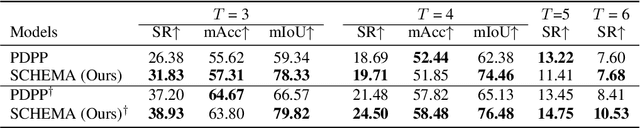
We study the problem of procedure planning in instructional videos, which aims to make a goal-oriented sequence of action steps given partial visual state observations. The motivation of this problem is to learn a structured and plannable state and action space. Recent works succeeded in sequence modeling of steps with only sequence-level annotations accessible during training, which overlooked the roles of states in the procedures. In this work, we point out that State CHangEs MAtter (SCHEMA) for procedure planning in instructional videos. We aim to establish a more structured state space by investigating the causal relations between steps and states in procedures. Specifically, we explicitly represent each step as state changes and track the state changes in procedures. For step representation, we leveraged the commonsense knowledge in large language models (LLMs) to describe the state changes of steps via our designed chain-of-thought prompting. For state change tracking, we align visual state observations with language state descriptions via cross-modal contrastive learning, and explicitly model the intermediate states of the procedure using LLM-generated state descriptions. Experiments on CrossTask, COIN, and NIV benchmark datasets demonstrate that our proposed SCHEMA model achieves state-of-the-art performance and obtains explainable visualizations.
Exploring the Reasoning Abilities of Multimodal Large Language Models (MLLMs): A Comprehensive Survey on Emerging Trends in Multimodal Reasoning
Jan 18, 2024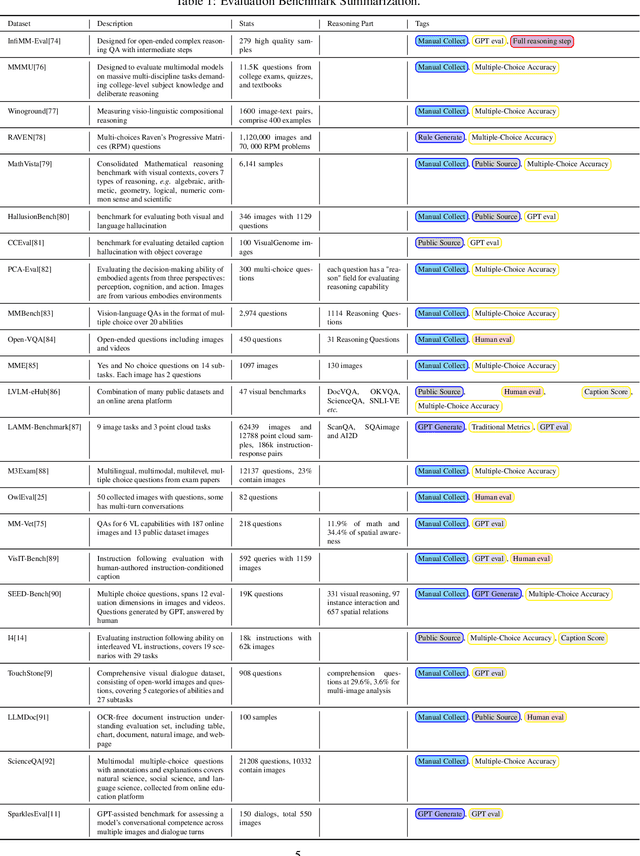



Strong Artificial Intelligence (Strong AI) or Artificial General Intelligence (AGI) with abstract reasoning ability is the goal of next-generation AI. Recent advancements in Large Language Models (LLMs), along with the emerging field of Multimodal Large Language Models (MLLMs), have demonstrated impressive capabilities across a wide range of multimodal tasks and applications. Particularly, various MLLMs, each with distinct model architectures, training data, and training stages, have been evaluated across a broad range of MLLM benchmarks. These studies have, to varying degrees, revealed different aspects of the current capabilities of MLLMs. However, the reasoning abilities of MLLMs have not been systematically investigated. In this survey, we comprehensively review the existing evaluation protocols of multimodal reasoning, categorize and illustrate the frontiers of MLLMs, introduce recent trends in applications of MLLMs on reasoning-intensive tasks, and finally discuss current practices and future directions. We believe our survey establishes a solid base and sheds light on this important topic, multimodal reasoning.
InfiMM-Eval: Complex Open-Ended Reasoning Evaluation For Multi-Modal Large Language Models
Dec 04, 2023
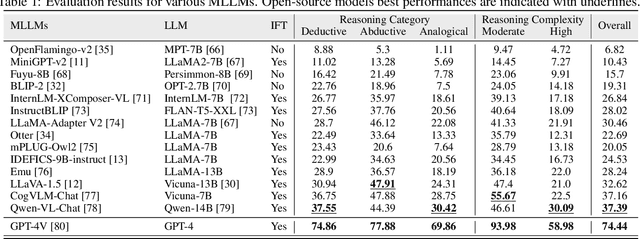
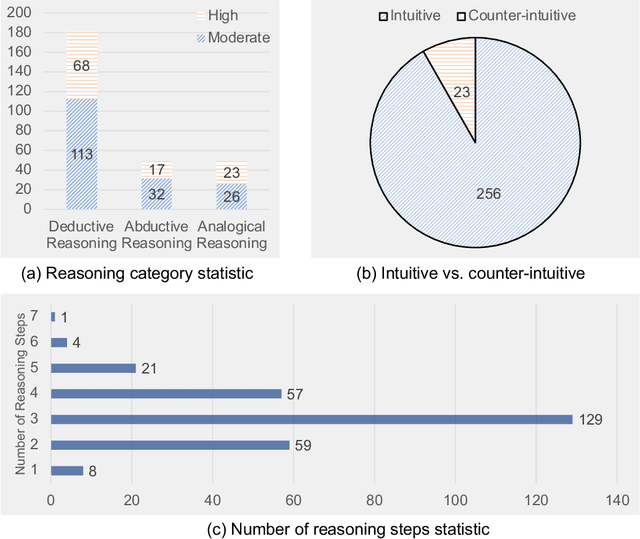
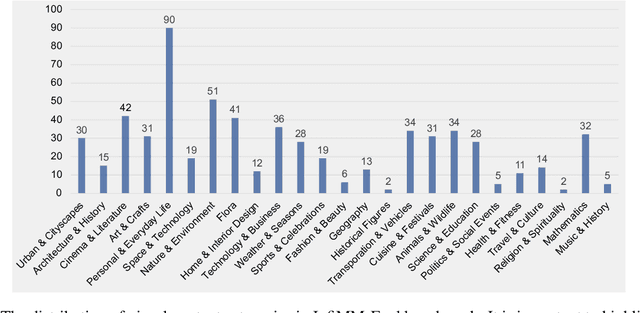
Multi-modal Large Language Models (MLLMs) are increasingly prominent in the field of artificial intelligence. These models not only excel in traditional vision-language tasks but also demonstrate impressive performance in contemporary multi-modal benchmarks. Although many of these benchmarks attempt to holistically evaluate MLLMs, they typically concentrate on basic reasoning tasks, often yielding only simple yes/no or multi-choice responses. These methods naturally lead to confusion and difficulties in conclusively determining the reasoning capabilities of MLLMs. To mitigate this issue, we manually curate a benchmark dataset specifically designed for MLLMs, with a focus on complex reasoning tasks. Our benchmark comprises three key reasoning categories: deductive, abductive, and analogical reasoning. The queries in our dataset are intentionally constructed to engage the reasoning capabilities of MLLMs in the process of generating answers. For a fair comparison across various MLLMs, we incorporate intermediate reasoning steps into our evaluation criteria. In instances where an MLLM is unable to produce a definitive answer, its reasoning ability is evaluated by requesting intermediate reasoning steps. If these steps align with our manual annotations, appropriate scores are assigned. This evaluation scheme resembles methods commonly used in human assessments, such as exams or assignments, and represents what we consider a more effective assessment technique compared with existing benchmarks. We evaluate a selection of representative MLLMs using this rigorously developed open-ended multi-step elaborate reasoning benchmark, designed to challenge and accurately measure their reasoning capabilities. The code and data will be released at https://infimm.github.io/InfiMM-Eval/
Video Summarization: Towards Entity-Aware Captions
Dec 01, 2023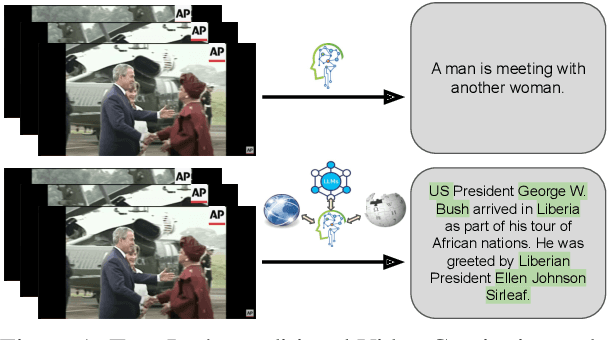
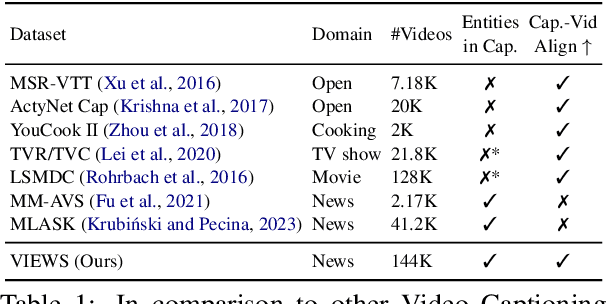
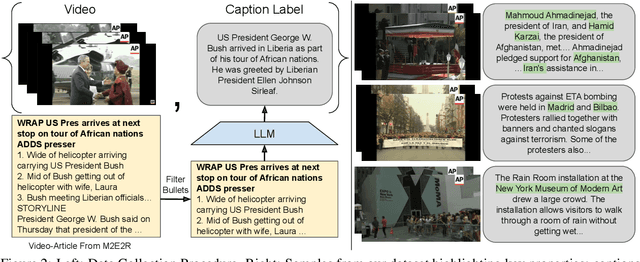
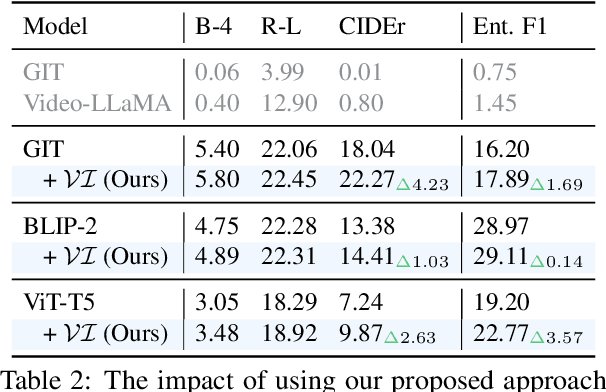
Existing popular video captioning benchmarks and models deal with generic captions devoid of specific person, place or organization named entities. In contrast, news videos present a challenging setting where the caption requires such named entities for meaningful summarization. As such, we propose the task of summarizing news video directly to entity-aware captions. We also release a large-scale dataset, VIEWS (VIdeo NEWS), to support research on this task. Further, we propose a method that augments visual information from videos with context retrieved from external world knowledge to generate entity-aware captions. We demonstrate the effectiveness of our approach on three video captioning models. We also show that our approach generalizes to existing news image captions dataset. With all the extensive experiments and insights, we believe we establish a solid basis for future research on this challenging task.