 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENTER: Event Based Interpretable Reasoning for VideoQA
Jan 24, 2025



In this paper, we present ENTER, an interpretable Video Question Answering (VideoQA) system based on event graphs. Event graphs convert videos into graphical representations, where video events form the nodes and event-event relationships (temporal/causal/hierarchical) form the edges. This structured representation offers many benefits: 1) Interpretable VideoQA via generated code that parses event-graph; 2) Incorporation of contextual visual information in the reasoning process (code generation) via event graphs; 3) Robust VideoQA via Hierarchical Iterative Update of the event graphs. Existing interpretable VideoQA systems are often top-down, disregarding low-level visual information in the reasoning plan generation, and are brittle. While bottom-up approaches produce responses from visual data, they lack interpretability. Experimental results on NExT-QA, IntentQA, and EgoSchema demonstrate that not only does our method outperform existing top-down approaches while obtaining competitive performance against bottom-up approaches, but more importantly, offers superior interpretability and explainability in the reasoning process.
PuzzleGPT: Emulating Human Puzzle-Solving Ability for Time and Location Prediction
Jan 24, 2025



The task of predicting time and location from images is challenging and requires complex human-like puzzle-solving ability over different clues. In this work, we formalize this ability into core skills and implement them using different modules in an expert pipeline called PuzzleGPT. PuzzleGPT consists of a perceiver to identify visual clues, a reasoner to deduce prediction candidates, a combiner to combinatorially combine information from different clues, a web retriever to get external knowledge if the task can't be solved locally, and a noise filter for robustness. This results in a zero-shot, interpretable, and robust approach that records state-of-the-art performance on two datasets -- TARA and WikiTilo. PuzzleGPT outperforms large VLMs such as BLIP-2, InstructBLIP, LLaVA, and even GPT-4V, as well as automatically generated reasoning pipelines like VisProg, by at least 32% and 38%, respectively. It even rivals or surpasses finetuned models.
HaloQuest: A Visual Hallucination Dataset for Advancing Multimodal Reasoning
Jul 22, 2024

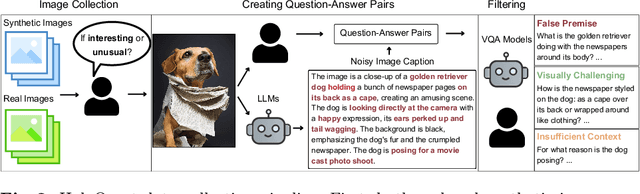
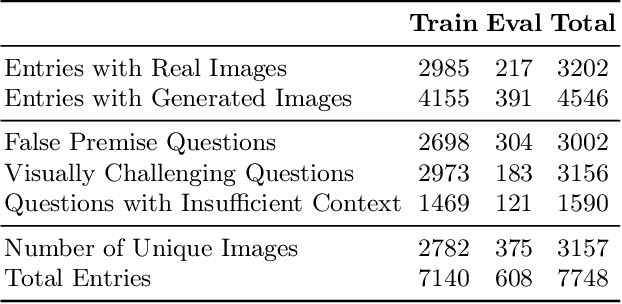
Hallucination has been a major problem for large language models and remains a critical challenge when it comes to multimodality in which vision-language models (VLMs) have to deal with not just textual but also visual inputs. Despite rapid progress in VLMs, resources for evaluating and addressing multimodal hallucination are limited and mostly focused on evaluation. This work introduces HaloQuest, a novel visual question answering dataset that captures various aspects of multimodal hallucination such as false premises, insufficient contexts, and visual challenges. A novel idea from HaloQuest is to leverage synthetic images, apart from real ones, to enable dataset creation at scale. With over 7.7K examples spanning across a wide variety of categories, HaloQuest was designed to be both a challenging benchmark for VLMs and a fine-tuning dataset for advancing multimodal reasoning. Our experiments reveal that current models struggle with HaloQuest, with all open-source VLMs achieving below 36% accuracy. On the other hand, fine-tuning on HaloQuest significantly reduces hallucination rates while preserving performance on standard reasoning tasks. Our results discover that benchmarking with generated images is highly correlated (r=0.97) with real images. Last but not least, we propose a novel Auto-Eval mechanism that is highly correlated with human raters (r=0.99) for evaluating VLMs. In sum, this work makes concrete strides towards understanding, evaluating, and mitigating hallucination in VLMs, serving as an important step towards more reliable multimodal AI systems in the future.
Detecting Multimodal Situations with Insufficient Context and Abstaining from Baseless Predictions
May 23, 2024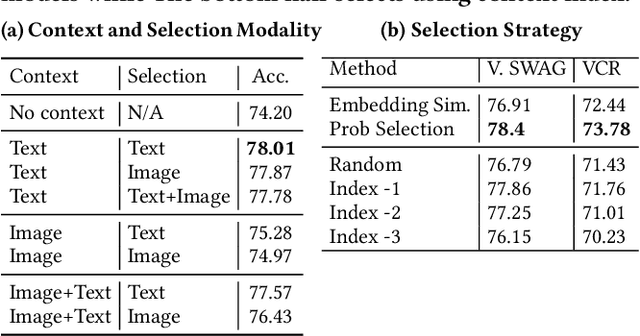
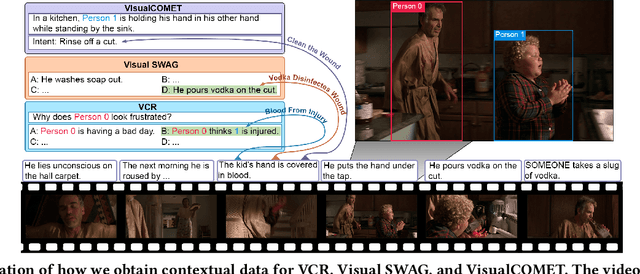
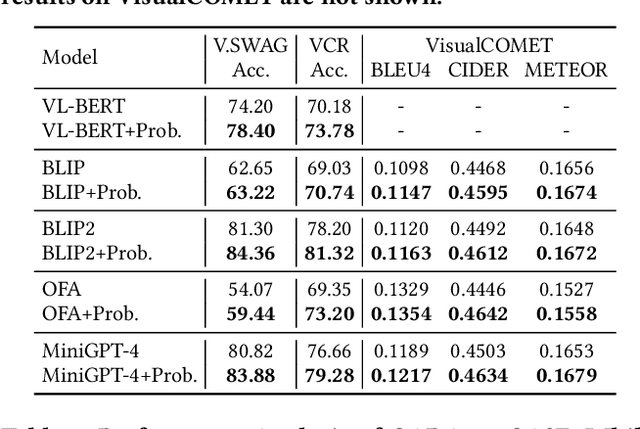
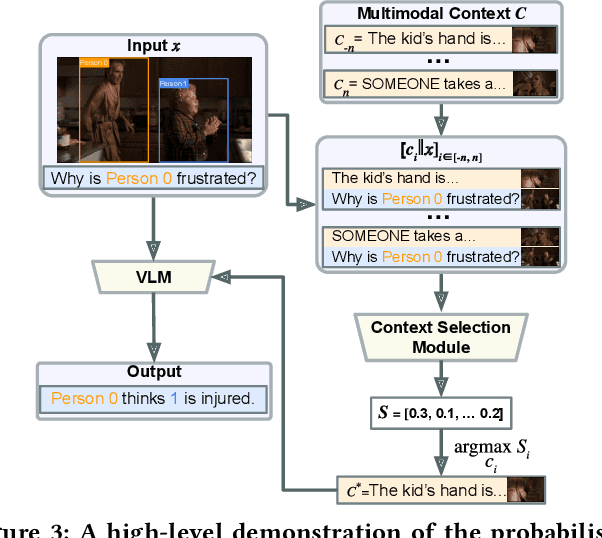
Despite the widespread adoption of Vision-Language Understanding (VLU) benchmarks such as VQA v2, OKVQA, A-OKVQA, GQA, VCR, SWAG, and VisualCOMET, our analysis reveals a pervasive issue affecting their integrity: these benchmarks contain samples where answers rely on assumptions unsupported by the provided context. Training models on such data foster biased learning and hallucinations as models tend to make similar unwarranted assumptions. To address this issue, we collect contextual data for each sample whenever available and train a context selection module to facilitate evidence-based model predictions. Strong improvements across multiple benchmarks demonstrate the effectiveness of our approach. Further, we develop a general-purpose Context-AwaRe Abstention (CARA) detector to identify samples lacking sufficient context and enhance model accuracy by abstaining from responding if the required context is absent. CARA exhibits generalization to new benchmarks it wasn't trained on, underscoring its utility for future VLU benchmarks in detecting or cleaning samples with inadequate context. Finally, we curate a Context Ambiguity and Sufficiency Evaluation (CASE) set to benchmark the performance of insufficient context detectors. Overall, our work represents a significant advancement in ensuring that vision-language models generate trustworthy and evidence-based outputs in complex real-world scenarios.
Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond
Oct 31, 2023



Vision-language (VL) understanding tasks evaluate models' comprehension of complex visual scenes through multiple-choice questions. However, we have identified two dataset biases that models can exploit as shortcuts to resolve various VL tasks correctly without proper understanding. The first type of dataset bias is \emph{Unbalanced Matching} bias, where the correct answer overlaps the question and image more than the incorrect answers. The second type of dataset bias is \emph{Distractor Similarity} bias, where incorrect answers are overly dissimilar to the correct answer but significantly similar to other incorrect answers within the same sample. To address these dataset biases, we first propose Adversarial Data Synthesis (ADS) to generate synthetic training and debiased evaluation data. We then introduce Intra-sample Counterfactual Training (ICT) to assist models in utilizing the synthesized training data, particularly the counterfactual data, via focusing on intra-sample differentiation. Extensive experiments demonstrate the effectiveness of ADS and ICT in consistently improving model performance across different benchmarks, even in domain-shifted scenarios.
* EMNLP 2023
UniFine: A Unified and Fine-grained Approach for Zero-shot Vision-Language Understanding
Jul 03, 2023



Vision-language tasks, such as VQA, SNLI-VE, and VCR are challenging because they require the model's reasoning ability to understand the semantics of the visual world and natural language. Supervised methods working for vision-language tasks have been well-studied. However, solving these tasks in a zero-shot setting is less explored. Since Contrastive Language-Image Pre-training (CLIP) has shown remarkable zero-shot performance on image-text matching, previous works utilized its strong zero-shot ability by converting vision-language tasks into an image-text matching problem, and they mainly consider global-level matching (e.g., the whole image or sentence). However, we find visual and textual fine-grained information, e.g., keywords in the sentence and objects in the image, can be fairly informative for semantics understanding. Inspired by this, we propose a unified framework to take advantage of the fine-grained information for zero-shot vision-language learning, covering multiple tasks such as VQA, SNLI-VE, and VCR. Our experiments show that our framework outperforms former zero-shot methods on VQA and achieves substantial improvement on SNLI-VE and VCR. Furthermore, our ablation studies confirm the effectiveness and generalizability of our proposed method. Code will be available at https://github.com/ThreeSR/UniFine
IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models
May 24, 2023



The field of vision-and-language (VL) understanding has made unprecedented progress with end-to-end large pre-trained VL models (VLMs). However, they still fall short in zero-shot reasoning tasks that require multi-step inferencing. To achieve this goal, previous works resort to a divide-and-conquer pipeline. In this paper, we argue that previous efforts have several inherent shortcomings: 1) They rely on domain-specific sub-question decomposing models. 2) They force models to predict the final answer even if the sub-questions or sub-answers provide insufficient information. We address these limitations via IdealGPT, a framework that iteratively decomposes VL reasoning using large language models (LLMs). Specifically, IdealGPT utilizes an LLM to generate sub-questions, a VLM to provide corresponding sub-answers, and another LLM to reason to achieve the final answer. These three modules perform the divide-and-conquer procedure iteratively until the model is confident about the final answer to the main question. We evaluate IdealGPT on multiple challenging VL reasoning tasks under a zero-shot setting. In particular, our IdealGPT outperforms the best existing GPT-4-like models by an absolute 10% on VCR and 15% on SNLI-VE. Code is available at https://github.com/Hxyou/IdealGPT
CoBIT: A Contrastive Bi-directional Image-Text Generation Model
Mar 23, 2023
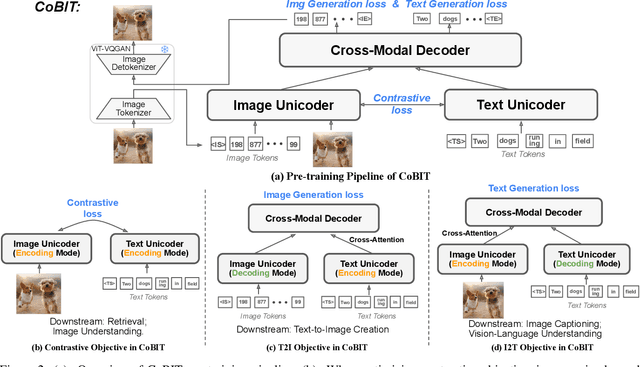
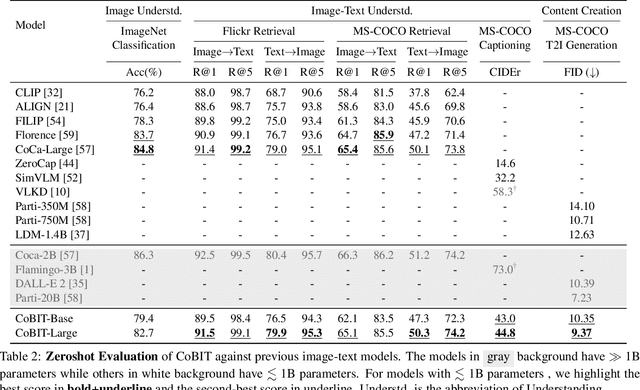
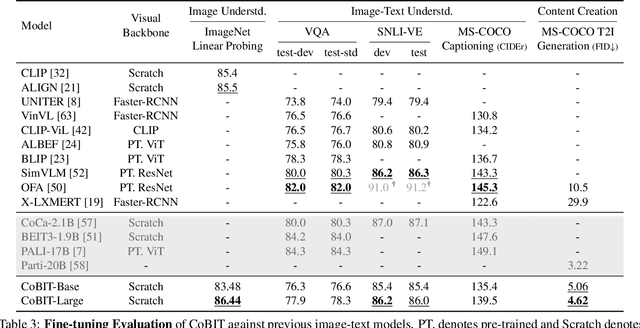
The field of vision and language has witnessed a proliferation of pre-trained foundation models. Most existing methods are independently pre-trained with contrastive objective like CLIP, image-to-text generative objective like PaLI, or text-to-image generative objective like Parti. However, the three objectives can be pre-trained on the same data, image-text pairs, and intuitively they complement each other as contrasting provides global alignment capacity and generation grants fine-grained understanding. In this work, we present a Contrastive Bi-directional Image-Text generation model (CoBIT), which attempts to unify the three pre-training objectives in one framework. Specifically, CoBIT employs a novel unicoder-decoder structure, consisting of an image unicoder, a text unicoder and a cross-modal decoder. The image/text unicoders can switch between encoding and decoding in different tasks, enabling flexibility and shared knowledge that benefits both image-to-text and text-to-image generations. CoBIT achieves superior performance in image understanding, image-text understanding (Retrieval, Captioning, VQA, SNLI-VE) and text-based content creation, particularly in zero-shot scenarios. For instance, 82.7% in zero-shot ImageNet classification, 9.37 FID score in zero-shot text-to-image generation and 44.8 CIDEr in zero-shot captioning.
Find Someone Who: Visual Commonsense Understanding in Human-Centric Grounding
Dec 14, 2022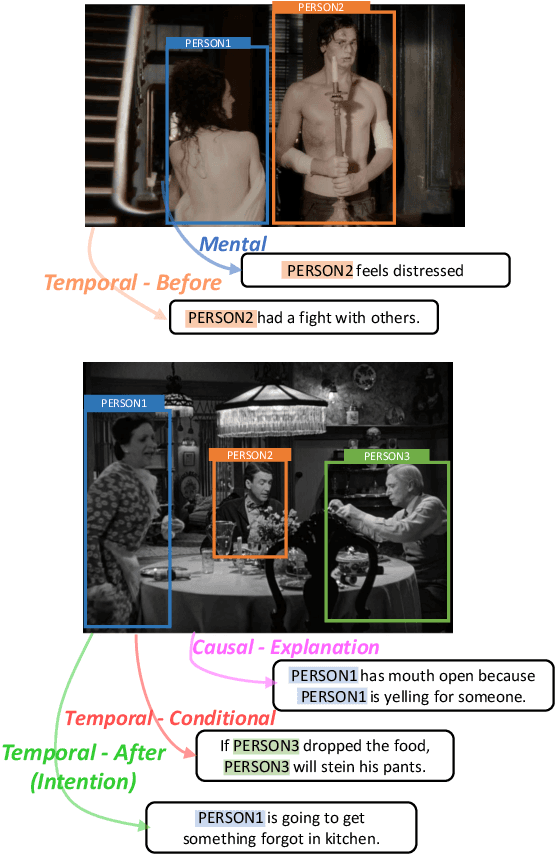



From a visual scene containing multiple people, human is able to distinguish each individual given the context descriptions about what happened before, their mental/physical states or intentions, etc. Above ability heavily relies on human-centric commonsense knowledge and reasoning. For example, if asked to identify the "person who needs healing" in an image, we need to first know that they usually have injuries or suffering expressions, then find the corresponding visual clues before finally grounding the person. We present a new commonsense task, Human-centric Commonsense Grounding, that tests the models' ability to ground individuals given the context descriptions about what happened before, and their mental/physical states or intentions. We further create a benchmark, HumanCog, a dataset with 130k grounded commonsensical descriptions annotated on 67k images, covering diverse types of commonsense and visual scenes. We set up a context-object-aware method as a strong baseline that outperforms previous pre-trained and non-pretrained models. Further analysis demonstrates that rich visual commonsense and powerful integration of multi-modal commonsense are essential, which sheds light on future works. Data and code will be available https://github.com/Hxyou/HumanCog.
Understanding ME? Multimodal Evaluation for Fine-grained Visual Commonsense
Nov 10, 2022
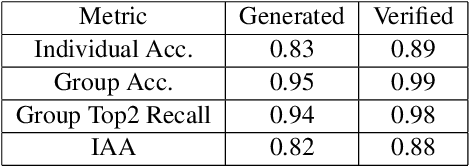
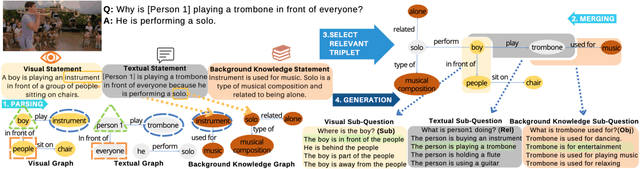
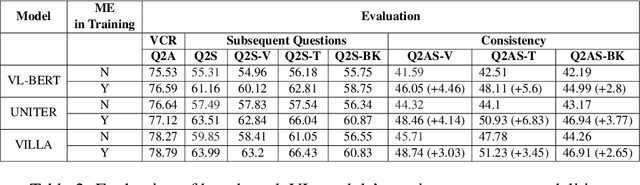
Visual commonsense understanding requires Vision Language (VL) models to not only understand image and text but also cross-reference in-between to fully integrate and achieve comprehension of the visual scene described. Recently, various approaches have been developed and have achieved high performance on visual commonsense benchmarks. However, it is unclear whether the models really understand the visual scene and underlying commonsense knowledge due to limited evaluation data resources. To provide an in-depth analysis, we present a Multimodal Evaluation (ME) pipeline to automatically generate question-answer pairs to test models' understanding of the visual scene, text, and related knowledge. We then take a step further to show that training with the ME data boosts the model's performance in standard VCR evaluation. Lastly, our in-depth analysis and comparison reveal interesting findings: (1) semantically low-level information can assist the learning of high-level information but not the opposite; (2) visual information is generally under utilization compared with text.