 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical token pruning for foundation models in few-shot conversational virtual assistant systems
Aug 21, 2024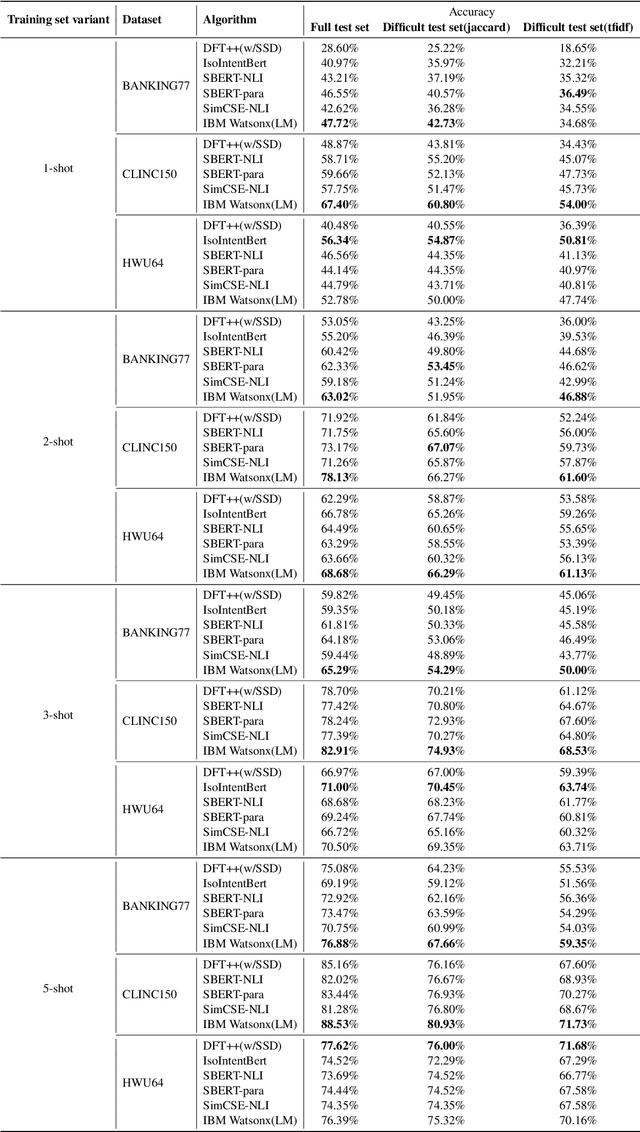
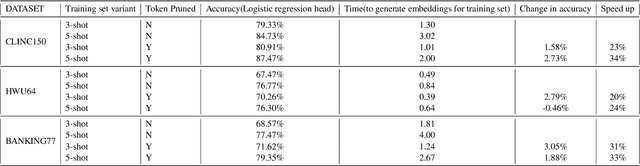
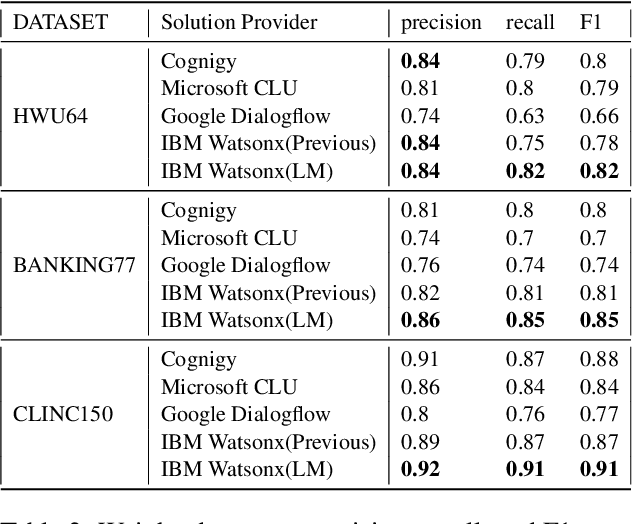
In an enterprise Virtual Assistant (VA) system, intent classification is the crucial component that determines how a user input is handled based on what the user wants. The VA system is expected to be a cost-efficient SaaS service with low training and inference time while achieving high accuracy even with a small number of training samples. We pretrain a transformer-based sentence embedding model with a contrastive learning objective and leverage the embedding of the model as features when training intent classification models. Our approach achieves the state-of-the-art results for few-shot scenarios and performs better than other commercial solutions on popular intent classification benchmarks. However, generating features via a transformer-based model increases the inference time, especially for longer user inputs, due to the quadratic runtime of the transformer's attention mechanism. On top of model distillation, we introduce a practical multi-task adaptation approach that configures dynamic token pruning without the need for task-specific training for intent classification. We demonstrate that this approach improves the inference speed of popular sentence transformer models without affecting model performance.
Check-COVID: Fact-Checking COVID-19 News Claims with Scientific Evidence
May 29, 2023



We present a new fact-checking benchmark, Check-COVID, that requires systems to verify claims about COVID-19 from news using evidence from scientific articles. This approach to fact-checking is particularly challenging as it requires checking internet text written in everyday language against evidence from journal articles written in formal academic language. Check-COVID contains 1, 504 expert-annotated news claims about the coronavirus paired with sentence-level evidence from scientific journal articles and veracity labels. It includes both extracted (journalist-written) and composed (annotator-written) claims. Experiments using both a fact-checking specific system and GPT-3.5, which respectively achieve F1 scores of 76.99 and 69.90 on this task, reveal the difficulty of automatically fact-checking both claim types and the importance of in-domain data for good performance. Our data and models are released publicly at https://github.com/posuer/Check-COVID.
IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models
May 24, 2023



The field of vision-and-language (VL) understanding has made unprecedented progress with end-to-end large pre-trained VL models (VLMs). However, they still fall short in zero-shot reasoning tasks that require multi-step inferencing. To achieve this goal, previous works resort to a divide-and-conquer pipeline. In this paper, we argue that previous efforts have several inherent shortcomings: 1) They rely on domain-specific sub-question decomposing models. 2) They force models to predict the final answer even if the sub-questions or sub-answers provide insufficient information. We address these limitations via IdealGPT, a framework that iteratively decomposes VL reasoning using large language models (LLMs). Specifically, IdealGPT utilizes an LLM to generate sub-questions, a VLM to provide corresponding sub-answers, and another LLM to reason to achieve the final answer. These three modules perform the divide-and-conquer procedure iteratively until the model is confident about the final answer to the main question. We evaluate IdealGPT on multiple challenging VL reasoning tasks under a zero-shot setting. In particular, our IdealGPT outperforms the best existing GPT-4-like models by an absolute 10% on VCR and 15% on SNLI-VE. Code is available at https://github.com/Hxyou/IdealGPT
Distinguish Sense from Nonsense: Out-of-Scope Detection for Virtual Assistants
Jan 16, 2023Out of Scope (OOS) detection in Conversational AI solutions enables a chatbot to handle a conversation gracefully when it is unable to make sense of the end-user query. Accurately tagging a query as out-of-domain is particularly hard in scenarios when the chatbot is not equipped to handle a topic which has semantic overlap with an existing topic it is trained on. We propose a simple yet effective OOS detection method that outperforms standard OOS detection methods in a real-world deployment of virtual assistants. We discuss the various design and deployment considerations for a cloud platform solution to train virtual assistants and deploy them at scale. Additionally, we propose a collection of datasets that replicates real-world scenarios and show comprehensive results in various settings using both offline and online evaluation metrics.
Semantic Categorization of Social Knowledge for Commonsense Question Answering
Sep 11, 2021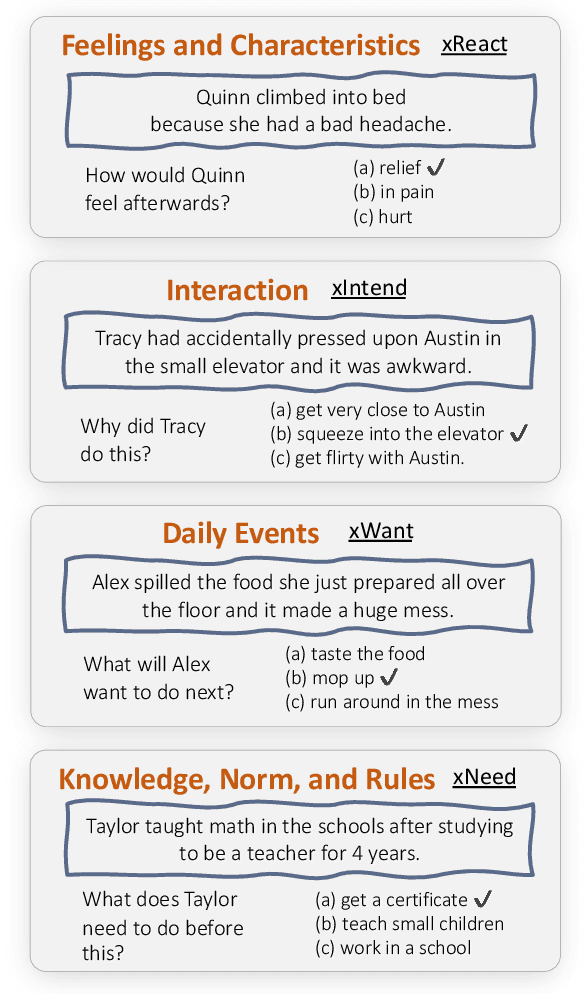
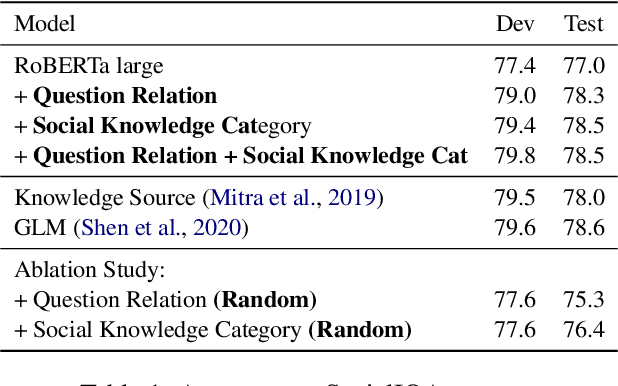

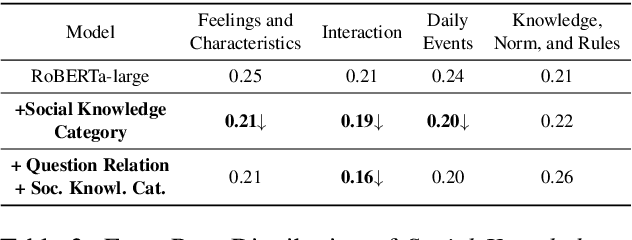
Large pre-trained language models (PLMs) have led to great success on various commonsense question answering (QA) tasks in an end-to-end fashion. However, little attention has been paid to what commonsense knowledge is needed to deeply characterize these QA tasks. In this work, we proposed to categorize the semantics needed for these tasks using the SocialIQA as an example. Building upon our labeled social knowledge categories dataset on top of SocialIQA, we further train neural QA models to incorporate such social knowledge categories and relation information from a knowledge base. Unlike previous work, we observe our models with semantic categorizations of social knowledge can achieve comparable performance with a relatively simple model and smaller size compared to other complex approaches.