 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Summarization: Towards Entity-Aware Captions
Dec 01, 2023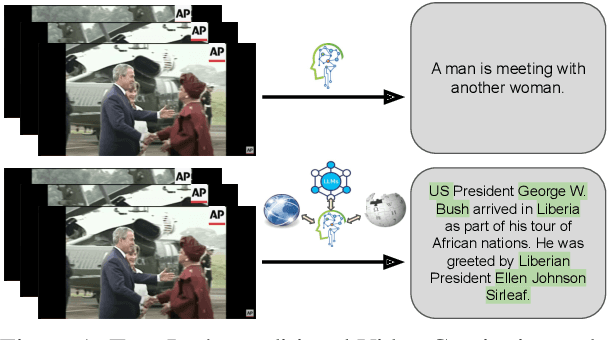
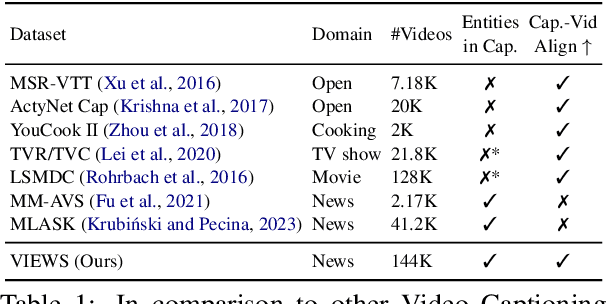
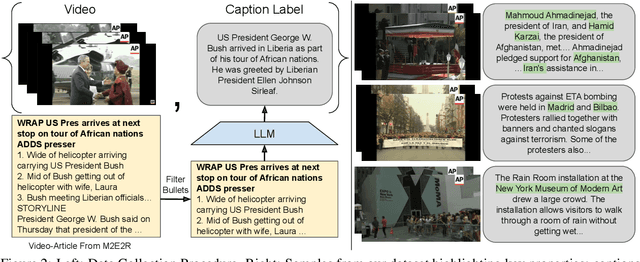
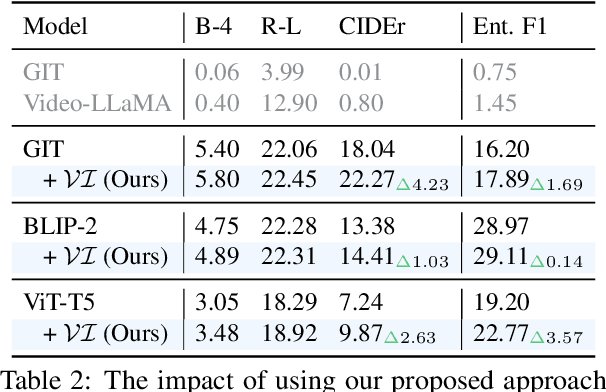
Existing popular video captioning benchmarks and models deal with generic captions devoid of specific person, place or organization named entities. In contrast, news videos present a challenging setting where the caption requires such named entities for meaningful summarization. As such, we propose the task of summarizing news video directly to entity-aware captions. We also release a large-scale dataset, VIEWS (VIdeo NEWS), to support research on this task. Further, we propose a method that augments visual information from videos with context retrieved from external world knowledge to generate entity-aware captions. We demonstrate the effectiveness of our approach on three video captioning models. We also show that our approach generalizes to existing news image captions dataset. With all the extensive experiments and insights, we believe we establish a solid basis for future research on this challenging task.
Learning from Children: Improving Image-Caption Pretraining via Curriculum
May 30, 2023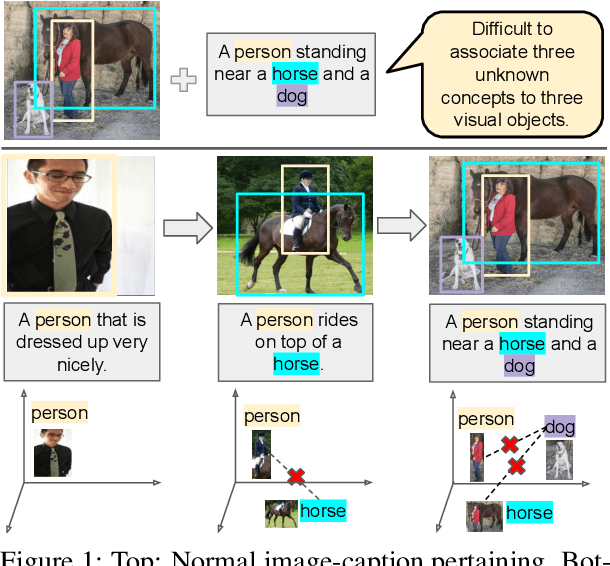
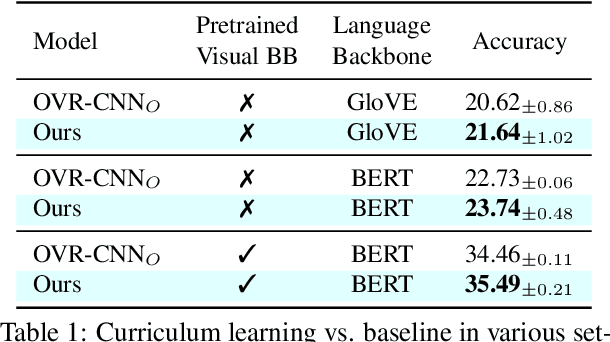
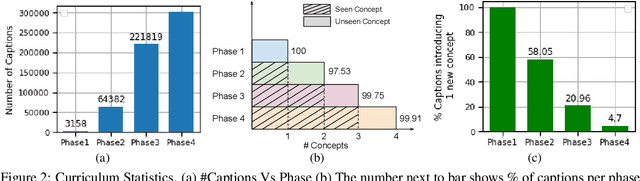

Image-caption pretraining has been quite successfully used for downstream vision tasks like zero-shot image classification and object detection. However, image-caption pretraining is still a hard problem -- it requires multiple concepts (nouns) from captions to be aligned to several objects in images. To tackle this problem, we go to the roots -- the best learner, children. We take inspiration from cognitive science studies dealing with children's language learning to propose a curriculum learning framework. The learning begins with easy-to-align image caption pairs containing one concept per caption. The difficulty is progressively increased with each new phase by adding one more concept per caption. Correspondingly, the knowledge acquired in each learning phase is utilized in subsequent phases to effectively constrain the learning problem to aligning one new concept-object pair in each phase. We show that this learning strategy improves over vanilla image-caption training in various settings -- pretraining from scratch, using a pretrained image or/and pretrained text encoder, low data regime etc.
IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models
May 24, 2023



The field of vision-and-language (VL) understanding has made unprecedented progress with end-to-end large pre-trained VL models (VLMs). However, they still fall short in zero-shot reasoning tasks that require multi-step inferencing. To achieve this goal, previous works resort to a divide-and-conquer pipeline. In this paper, we argue that previous efforts have several inherent shortcomings: 1) They rely on domain-specific sub-question decomposing models. 2) They force models to predict the final answer even if the sub-questions or sub-answers provide insufficient information. We address these limitations via IdealGPT, a framework that iteratively decomposes VL reasoning using large language models (LLMs). Specifically, IdealGPT utilizes an LLM to generate sub-questions, a VLM to provide corresponding sub-answers, and another LLM to reason to achieve the final answer. These three modules perform the divide-and-conquer procedure iteratively until the model is confident about the final answer to the main question. We evaluate IdealGPT on multiple challenging VL reasoning tasks under a zero-shot setting. In particular, our IdealGPT outperforms the best existing GPT-4-like models by an absolute 10% on VCR and 15% on SNLI-VE. Code is available at https://github.com/Hxyou/IdealGPT
Multimodal Event Graphs: Towards Event Centric Understanding of Multimodal World
Jun 14, 2022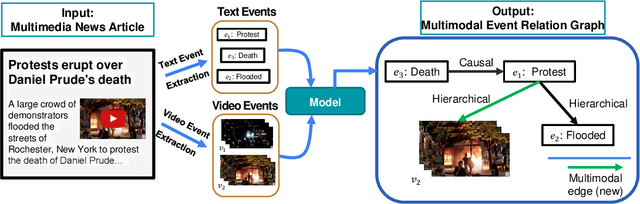
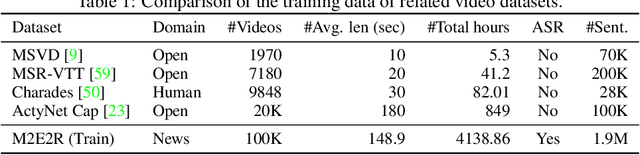
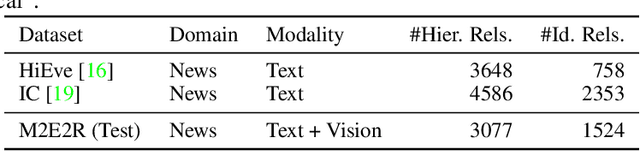

Understanding how events described or shown in multimedia content relate to one another is a critical component to developing robust artificially intelligent systems which can reason about real-world media. While much research has been devoted to event understanding in the text, image, and video domains, none have explored the complex relations that events experience across domains. For example, a news article may describe a `protest' event while a video shows an `arrest' event. Recognizing that the visual `arrest' event is a subevent of the broader `protest' event is a challenging, yet important problem that prior work has not explored. In this paper, we propose the novel task of MultiModal Event Event Relations to recognize such cross-modal event relations. We contribute a large-scale dataset consisting of 100k video-news article pairs, as well as a benchmark of densely annotated data. We also propose a weakly supervised multimodal method which integrates commonsense knowledge from an external knowledge base (KB) to predict rich multimodal event hierarchies. Experiments show that our model outperforms a number of competitive baselines on our proposed benchmark. We also perform a detailed analysis of our model's performance and suggest directions for future research.
Generating Rationales in Visual Question Answering
Apr 04, 2020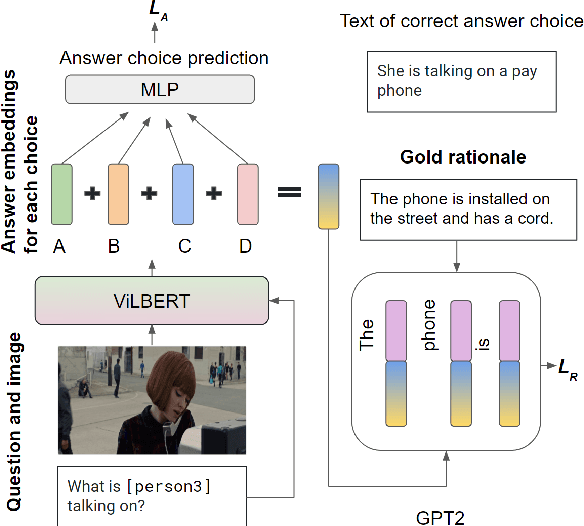
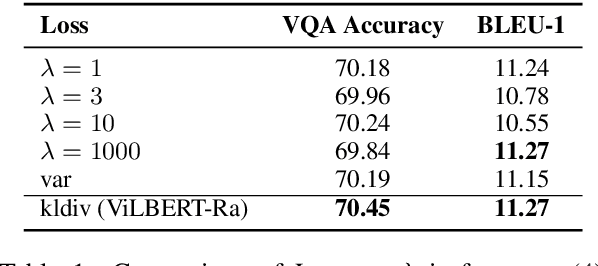


Despite recent advances in Visual QuestionAnswering (VQA), it remains a challenge todetermine how much success can be attributedto sound reasoning and comprehension ability.We seek to investigate this question by propos-ing a new task ofrationale generation. Es-sentially, we task a VQA model with generat-ing rationales for the answers it predicts. Weuse data from the Visual Commonsense Rea-soning (VCR) task, as it contains ground-truthrationales along with visual questions and an-swers. We first investigate commonsense un-derstanding in one of the leading VCR mod-els, ViLBERT, by generating rationales frompretrained weights using a state-of-the-art lan-guage model, GPT-2. Next, we seek to jointlytrain ViLBERT with GPT-2 in an end-to-endfashion with the dual task of predicting the an-swer in VQA and generating rationales. Weshow that this kind of training injects com-monsense understanding in the VQA modelthrough quantitative and qualitative evaluationmetrics
Progressive Growing of Neural ODEs
Mar 08, 2020
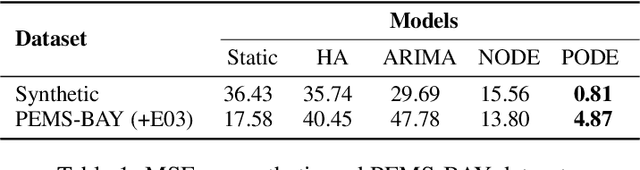

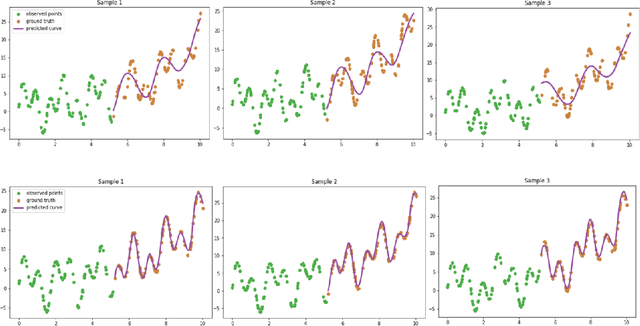
Neural Ordinary Differential Equations (NODEs) have proven to be a powerful modeling tool for approximating (interpolation) and forecasting (extrapolation) irregularly sampled time series data. However, their performance degrades substantially when applied to real-world data, especially long-term data with complex behaviors (e.g., long-term trend across years, mid-term seasonality across months, and short-term local variation across days). To address the modeling of such complex data with different behaviors at different frequencies (time spans), we propose a novel progressive learning paradigm of NODEs for long-term time series forecasting. Specifically, following the principle of curriculum learning, we gradually increase the complexity of data and network capacity as training progresses. Our experiments with both synthetic data and real traffic data (PeMS Bay Area traffic data) show that our training methodology consistently improves the performance of vanilla NODEs by over 64%.
GANspection
Oct 21, 2019Generative Adversarial Networks (GANs) have been used extensively and quite successfully for unsupervised learning. As GANs don't approximate an explicit probability distribution, it's an interesting study to inspect the latent space representations learned by GANs. The current work seeks to push the boundaries of such inspection methods to further understand in more detail the manifold being learned by GANs. Various interpolation and extrapolation techniques along with vector arithmetic is used to understand the learned manifold. We show through experiments that GANs indeed learn a data probability distribution rather than memorize images/data. Further, we prove that GANs encode semantically relevant information in the learned probability distribution. The experiments have been performed on two publicly available datasets - Large Scale Scene Understanding (LSUN) and CelebA.
Enforcing Reasoning in Visual Commonsense Reasoning
Oct 21, 2019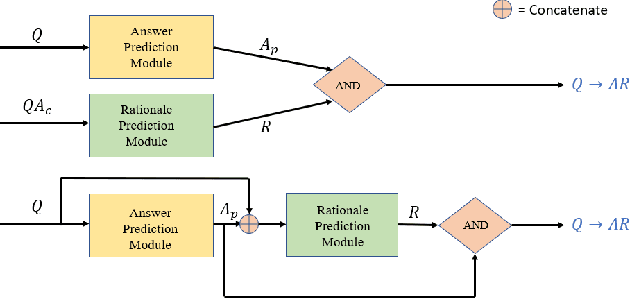
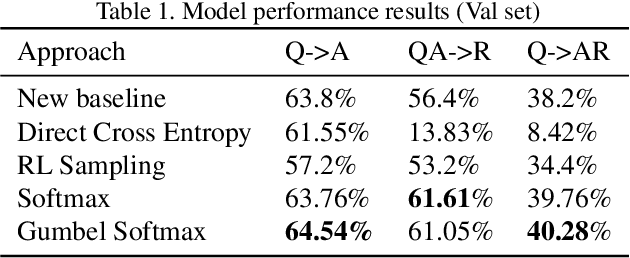


The task of Visual Commonsense Reasoning is extremely challenging in the sense that the model has to not only be able to answer a question given an image, but also be able to learn to reason. The baselines introduced in this task are quite limiting because two networks are trained for predicting answers and rationales separately. Question and image is used as input to train answer prediction network while question, image and correct answer are used as input in the rationale prediction network. As rationale is conditioned on the correct answer, it is based on the assumption that we can solve Visual Question Answering task without any error - which is over ambitious. Moreover, such an approach makes both answer and rationale prediction two completely independent VQA tasks rendering cognition task meaningless. In this paper, we seek to address these issues by proposing an end-to-end trainable model which considers both answers and their reasons jointly. Specifically, we first predict the answer for the question and then use the chosen answer to predict the rationale. However, a trivial design of such a model becomes non-differentiable which makes it difficult to train. We solve this issue by proposing four approaches - softmax, gumbel-softmax, reinforcement learning based sampling and direct cross entropy against all pairs of answers and rationales. We demonstrate through experiments that our model performs competitively against current state-of-the-art. We conclude with an analysis of presented approaches and discuss avenues for further work.