 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Layer Decomposition
Feb 22, 2026Precise, object-aware control over visual content is essential for advanced image editing and compositional generation. Yet, most existing approaches operate on entire images holistically, limiting the ability to isolate and manipulate individual scene elements. In contrast, layered representations, where scenes are explicitly separated into objects, environmental context, and visual effects, provide a more intuitive and structured framework for interpreting and editing visual content. To bridge this gap and enable both compositional understanding and controllable editing, we introduce the Referring Layer Decomposition (RLD) task, which predicts complete RGBA layers from a single RGB image, conditioned on flexible user prompts, such as spatial inputs (e.g., points, boxes, masks), natural language descriptions, or combinations thereof. At the core is the RefLade, a large-scale dataset comprising 1.11M image-layer-prompt triplets produced by our scalable data engine, along with 100K manually curated, high-fidelity layers. Coupled with a perceptually grounded, human-preference-aligned automatic evaluation protocol, RefLade establishes RLD as a well-defined and benchmarkable research task. Building on this foundation, we present RefLayer, a simple baseline designed for prompt-conditioned layer decomposition, achieving high visual fidelity and semantic alignment. Extensive experiments show our approach enables effective training, reliable evaluation, and high-quality image decomposition, while exhibiting strong zero-shot generalization capabilities.
EchoFoley: Event-Centric Hierarchical Control for Video Grounded Creative Sound Generation
Dec 31, 2025Sound effects build an essential layer of multimodal storytelling, shaping the emotional atmosphere and the narrative semantics of videos. Despite recent advancement in video-text-to-audio (VT2A), the current formulation faces three key limitations: First, an imbalance between visual and textual conditioning that leads to visual dominance; Second, the absence of a concrete definition for fine-grained controllable generation; Third, weak instruction understanding and following, as existing datasets rely on brief categorical tags. To address these limitations, we introduce EchoFoley, a new task designed for video-grounded sound generation with both event level local control and hierarchical semantic control. Our symbolic representation for sounding events specifies when, what, and how each sound is produced within a video or instruction, enabling fine-grained controls like sound generation, insertion, and editing. To support this task, we construct EchoFoley-6k, a large-scale, expert-curated benchmark containing over 6,000 video-instruction-annotation triplets. Building upon this foundation, we propose EchoVidia a sounding-event-centric agentic generation framework with slow-fast thinking strategy. Experiments show that EchoVidia surpasses recent VT2A models by 40.7% in controllability and 12.5% in perceptual quality.
Where do Large Vision-Language Models Look at when Answering Questions?
Mar 18, 2025Large Vision-Language Models (LVLMs) have shown promising performance in vision-language understanding and reasoning tasks. However, their visual understanding behaviors remain underexplored. A fundamental question arises: to what extent do LVLMs rely on visual input, and which image regions contribute to their responses? It is non-trivial to interpret the free-form generation of LVLMs due to their complicated visual architecture (e.g., multiple encoders and multi-resolution) and variable-length outputs. In this paper, we extend existing heatmap visualization methods (e.g., iGOS++) to support LVLMs for open-ended visual question answering. We propose a method to select visually relevant tokens that reflect the relevance between generated answers and input image. Furthermore, we conduct a comprehensive analysis of state-of-the-art LVLMs on benchmarks designed to require visual information to answer. Our findings offer several insights into LVLM behavior, including the relationship between focus region and answer correctness, differences in visual attention across architectures, and the impact of LLM scale on visual understanding. The code and data are available at https://github.com/bytedance/LVLM_Interpretation.
DiffLM: Controllable Synthetic Data Generation via Diffusion Language Models
Nov 05, 2024



Recent advancements in large language models (LLMs) have significantly enhanced their knowledge and generative capabilities, leading to a surge of interest in leveraging LLMs for high-quality data synthesis. However, synthetic data generation via prompting LLMs remains challenging due to LLMs' limited understanding of target data distributions and the complexity of prompt engineering, especially for structured formatted data. To address these issues, we introduce DiffLM, a controllable data synthesis framework based on variational autoencoder (VAE), which further (1) leverages diffusion models to reserve more information of original distribution and format structure in the learned latent distribution and (2) decouples the learning of target distribution knowledge from the LLM's generative objectives via a plug-and-play latent feature injection module. As we observed significant discrepancies between the VAE's latent representations and the real data distribution, the latent diffusion module is introduced into our framework to learn a fully expressive latent distribution. Evaluations on seven real-world datasets with structured formatted data (i.e., Tabular, Code and Tool data) demonstrate that DiffLM generates high-quality data, with performance on downstream tasks surpassing that of real data by 2-7 percent in certain cases. The data and code will be publicly available upon completion of internal review.
Unveiling Narrative Reasoning Limits of Large Language Models with Trope in Movie Synopses
Sep 22, 2024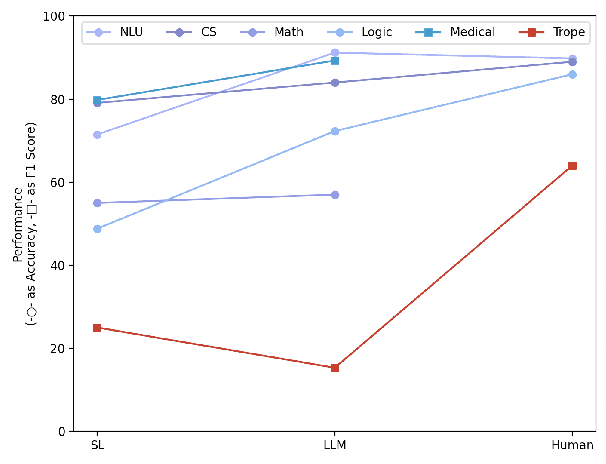

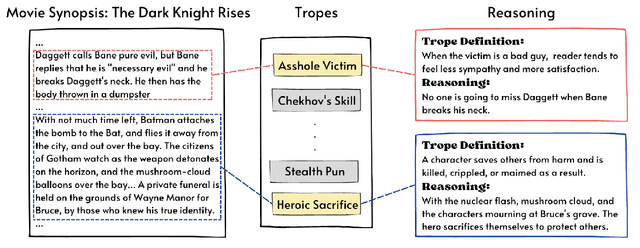

Large language models (LLMs) equipped with chain-of-thoughts (CoT) prompting have shown significant multi-step reasoning capabilities in factual content like mathematics, commonsense, and logic. However, their performance in narrative reasoning, which demands greater abstraction capabilities, remains unexplored. This study utilizes tropes in movie synopses to assess the abstract reasoning abilities of state-of-the-art LLMs and uncovers their low performance. We introduce a trope-wise querying approach to address these challenges and boost the F1 score by 11.8 points. Moreover, while prior studies suggest that CoT enhances multi-step reasoning, this study shows CoT can cause hallucinations in narrative content, reducing GPT-4's performance. We also introduce an Adversarial Injection method to embed trope-related text tokens into movie synopses without explicit tropes, revealing CoT's heightened sensitivity to such injections. Our comprehensive analysis provides insights for future research directions.
AIPO: Improving Training Objective for Iterative Preference Optimization
Sep 13, 2024



Preference Optimization (PO), is gaining popularity as an alternative choice of Proximal Policy Optimization (PPO) for aligning Large Language Models (LLMs). Recent research on aligning LLMs iteratively with synthetic or partially synthetic data shows promising results in scaling up PO training for both academic settings and proprietary trained models such as Llama3. Despite its success, our study shows that the length exploitation issue present in PO is even more severe in Iterative Preference Optimization (IPO) due to the iterative nature of the process. In this work, we study iterative preference optimization with synthetic data. We share the findings and analysis along the way of building the iterative preference optimization pipeline. More specifically, we discuss the length exploitation issue during iterative preference optimization and propose our training objective for iterative preference optimization, namely Agreement-aware Iterative Preference Optimization (AIPO). To demonstrate the effectiveness of our method, we conduct comprehensive experiments and achieve state-of-the-art performance on MT-Bench, AlpacaEval 2.0, and Arena-Hard. Our implementation and model checkpoints will be made available at https://github.com/bytedance/AIPO.
Investigating Video Reasoning Capability of Large Language Models with Tropes in Movies
Jun 16, 2024



Large Language Models (LLMs) have demonstrated effectiveness not only in language tasks but also in video reasoning. This paper introduces a novel dataset, Tropes in Movies (TiM), designed as a testbed for exploring two critical yet previously overlooked video reasoning skills: (1) Abstract Perception: understanding and tokenizing abstract concepts in videos, and (2) Long-range Compositional Reasoning: planning and integrating intermediate reasoning steps for understanding long-range videos with numerous frames. Utilizing tropes from movie storytelling, TiM evaluates the reasoning capabilities of state-of-the-art LLM-based approaches. Our experiments show that current methods, including Captioner-Reasoner, Large Multimodal Model Instruction Fine-tuning, and Visual Programming, only marginally outperform a random baseline when tackling the challenges of Abstract Perception and Long-range Compositional Reasoning. To address these deficiencies, we propose Face-Enhanced Viper of Role Interactions (FEVoRI) and Context Query Reduction (ConQueR), which enhance Visual Programming by fostering role interaction awareness and progressively refining movie contexts and trope queries during reasoning processes, significantly improving performance by 15 F1 points. However, this performance still lags behind human levels (40 vs. 65 F1). Additionally, we introduce a new protocol to evaluate the necessity of Abstract Perception and Long-range Compositional Reasoning for task resolution. This is done by analyzing the code generated through Visual Programming using an Abstract Syntax Tree (AST), thereby confirming the increased complexity of TiM. The dataset and code are available at: https://ander1119.github.io/TiM
WIDIn: Wording Image for Domain-Invariant Representation in Single-Source Domain Generalization
May 28, 2024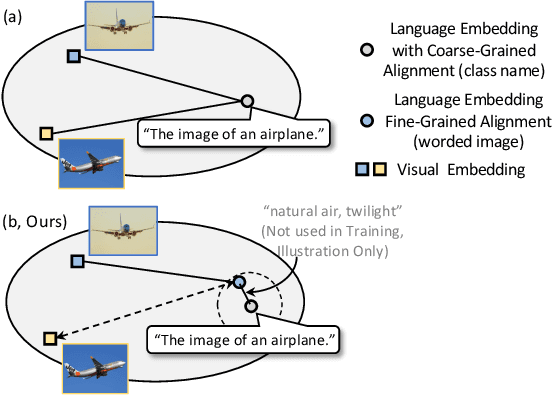
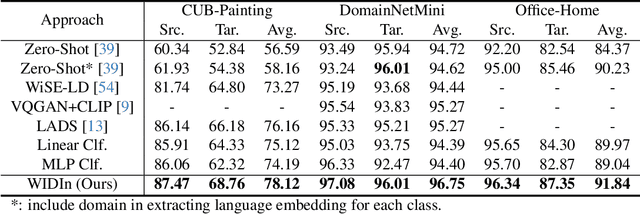
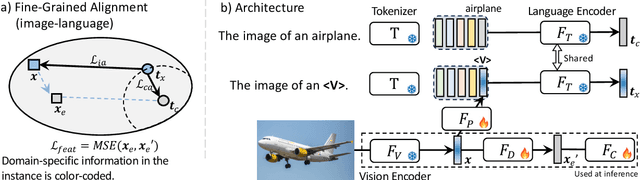
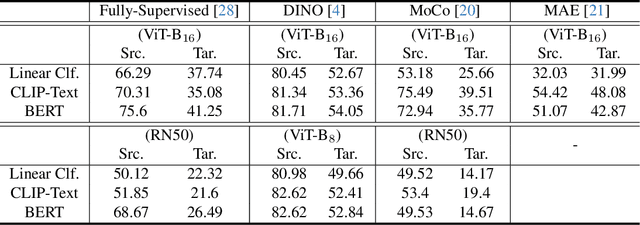
Language has been useful in extending the vision encoder to data from diverse distributions without empirical discovery in training domains. However, as the image description is mostly at coarse-grained level and ignores visual details, the resulted embeddings are still ineffective in overcoming complexity of domains at inference time. We present a self-supervision framework WIDIn, Wording Images for Domain-Invariant representation, to disentangle discriminative visual representation, by only leveraging data in a single domain and without any test prior. Specifically, for each image, we first estimate the language embedding with fine-grained alignment, which can be consequently used to adaptively identify and then remove domain-specific counterpart from the raw visual embedding. WIDIn can be applied to both pretrained vision-language models like CLIP, and separately trained uni-modal models like MoCo and BERT. Experimental studies on three domain generalization datasets demonstrate the effectiveness of our approach.
RAP: Retrieval-Augmented Planner for Adaptive Procedure Planning in Instructional Videos
Mar 27, 2024



Procedure Planning in instructional videos entails generating a sequence of action steps based on visual observations of the initial and target states. Despite the rapid progress in this task, there remain several critical challenges to be solved: (1) Adaptive procedures: Prior works hold an unrealistic assumption that the number of action steps is known and fixed, leading to non-generalizable models in real-world scenarios where the sequence length varies. (2) Temporal relation: Understanding the step temporal relation knowledge is essential in producing reasonable and executable plans. (3) Annotation cost: Annotating instructional videos with step-level labels (i.e., timestamp) or sequence-level labels (i.e., action category) is demanding and labor-intensive, limiting its generalizability to large-scale datasets.In this work, we propose a new and practical setting, called adaptive procedure planning in instructional videos, where the procedure length is not fixed or pre-determined. To address these challenges we introduce Retrieval-Augmented Planner (RAP) model. Specifically, for adaptive procedures, RAP adaptively determines the conclusion of actions using an auto-regressive model architecture. For temporal relation, RAP establishes an external memory module to explicitly retrieve the most relevant state-action pairs from the training videos and revises the generated procedures. To tackle high annotation cost, RAP utilizes a weakly-supervised learning manner to expand the training dataset to other task-relevant, unannotated videos by generating pseudo labels for action steps. Experiments on CrossTask and COIN benchmarks show the superiority of RAP over traditional fixed-length models, establishing it as a strong baseline solution for adaptive procedure planning.
SCHEMA: State CHangEs MAtter for Procedure Planning in Instructional Videos
Mar 03, 2024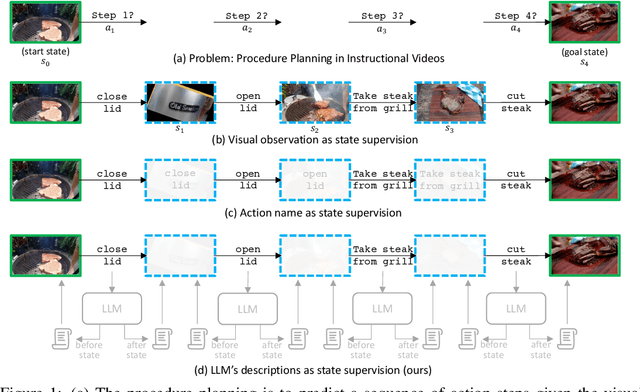
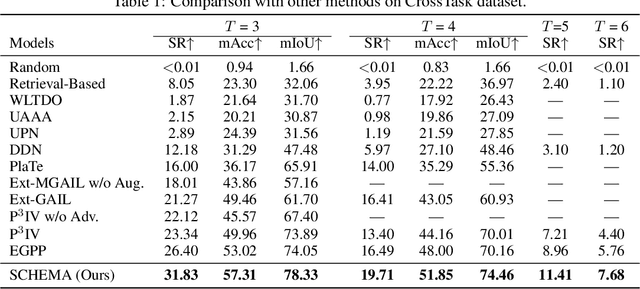

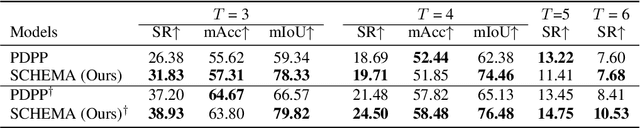
We study the problem of procedure planning in instructional videos, which aims to make a goal-oriented sequence of action steps given partial visual state observations. The motivation of this problem is to learn a structured and plannable state and action space. Recent works succeeded in sequence modeling of steps with only sequence-level annotations accessible during training, which overlooked the roles of states in the procedures. In this work, we point out that State CHangEs MAtter (SCHEMA) for procedure planning in instructional videos. We aim to establish a more structured state space by investigating the causal relations between steps and states in procedures. Specifically, we explicitly represent each step as state changes and track the state changes in procedures. For step representation, we leveraged the commonsense knowledge in large language models (LLMs) to describe the state changes of steps via our designed chain-of-thought prompting. For state change tracking, we align visual state observations with language state descriptions via cross-modal contrastive learning, and explicitly model the intermediate states of the procedure using LLM-generated state descriptions. Experiments on CrossTask, COIN, and NIV benchmark datasets demonstrate that our proposed SCHEMA model achieves state-of-the-art performance and obtains explainable visualizations.