 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Narrative Reasoning Limits of Large Language Models with Trope in Movie Synopses
Sep 22, 2024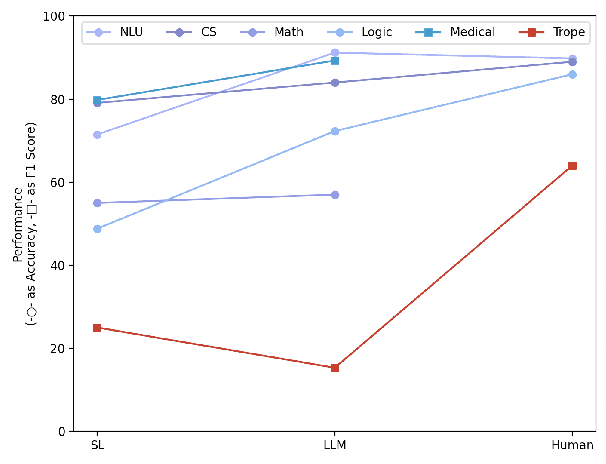

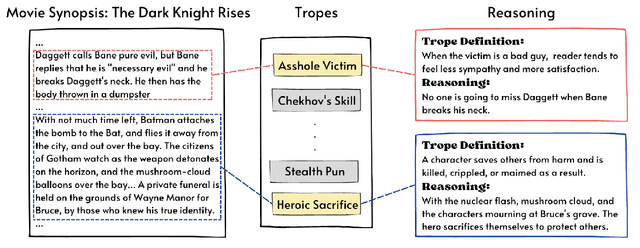

Large language models (LLMs) equipped with chain-of-thoughts (CoT) prompting have shown significant multi-step reasoning capabilities in factual content like mathematics, commonsense, and logic. However, their performance in narrative reasoning, which demands greater abstraction capabilities, remains unexplored. This study utilizes tropes in movie synopses to assess the abstract reasoning abilities of state-of-the-art LLMs and uncovers their low performance. We introduce a trope-wise querying approach to address these challenges and boost the F1 score by 11.8 points. Moreover, while prior studies suggest that CoT enhances multi-step reasoning, this study shows CoT can cause hallucinations in narrative content, reducing GPT-4's performance. We also introduce an Adversarial Injection method to embed trope-related text tokens into movie synopses without explicit tropes, revealing CoT's heightened sensitivity to such injections. Our comprehensive analysis provides insights for future research directions.
VICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation
May 26, 2024
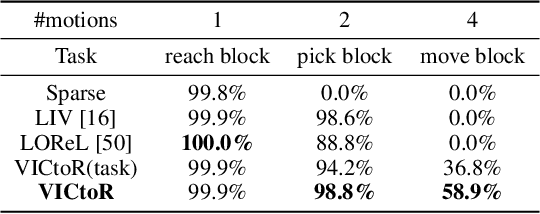
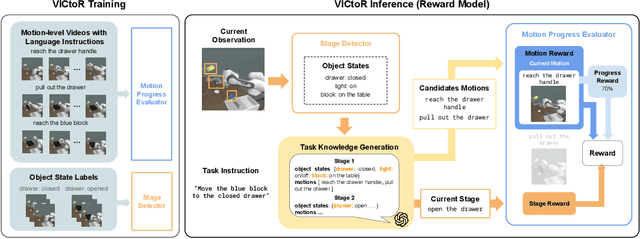
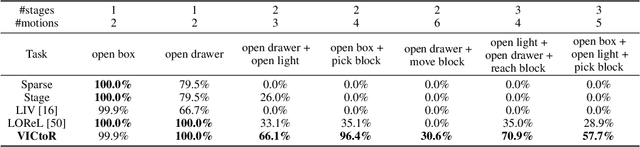
We study reward models for long-horizon manipulation tasks by learning from action-free videos and language instructions, which we term the visual-instruction correlation (VIC) problem. Recent advancements in cross-modality modeling have highlighted the potential of reward modeling through visual and language correlations. However, existing VIC methods face challenges in learning rewards for long-horizon tasks due to their lack of sub-stage awareness, difficulty in modeling task complexities, and inadequate object state estimation. To address these challenges, we introduce VICtoR, a novel hierarchical VIC reward model capable of providing effective reward signals for long-horizon manipulation tasks. VICtoR precisely assesses task progress at various levels through a novel stage detector and motion progress evaluator, offering insightful guidance for agents learning the task effectively. To validate the effectiveness of VICtoR, we conducted extensive experiments in both simulated and real-world environments. The results suggest that VICtoR outperformed the best existing VIC methods, achieving a 43% improvement in success rates for long-horizon tasks.