 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXPO-FT: Sample-Efficient Reinforcement Learning Finetuning for Vision-Language-Action Models
May 25, 2026The ability to efficiently and reliably learn new tasks has been a foundational challenge in robotics. Vision-Language-Action (VLA) models have demonstrated strong generalization across diverse manipulation tasks, yet pretrained policies consistently fall short of the reliability required for real-world deployment. Reinforcement learning (RL) fine-tuning offers a promising path to bridge this gap, but existing approaches either train from scratch without fully leveraging pretrained priors, or fine-tune VLAs without achieving the sample efficiency and success rates that practical deployment demands. We present EXPO-FT, a system for stable, sample-efficient RL finetuning of pretrained VLA policies that closes this gap. Our system solves a suite of challenging manipulation tasks, including routing string lights and inserting the plug to light it up, striking a pool ball into a pocket, and inserting a flower into a wine bottle, each requiring combinations of high precision, dynamic actions, and robustness to varied initial states. Our system achieves perfect task performance (30/30 successes) across all evaluated tasks within an average of 19.1 minutes of online robot data, outperforming both prior RL-from-scratch and VLA finetuning approaches. We release an open-source codebase with the aim of facilitating broader adoption of RL finetuning of VLA models in robotics.
TQL: Scaling Q-Functions with Transformers by Preventing Attention Collapse
Feb 01, 2026Despite scale driving substantial recent advancements in machine learning, reinforcement learning (RL) methods still primarily use small value functions. Naively scaling value functions -- including with a transformer architecture, which is known to be highly scalable -- often results in learning instability and worse performance. In this work, we ask what prevents transformers from scaling effectively for value functions? Through empirical analysis, we identify the critical failure mode in this scaling: attention scores collapse as capacity increases. Our key insight is that we can effectively prevent this collapse and stabilize training by controlling the entropy of the attention scores, thereby enabling the use of larger models. To this end, we propose Transformer Q-Learning (TQL), a method that unlocks the scaling potential of transformers in learning value functions in RL. Our approach yields up to a 43% improvement in performance when scaling from the smallest to the largest network sizes, while prior methods suffer from performance degradation.
Learning Skills from Action-Free Videos
Dec 23, 2025Learning from videos offers a promising path toward generalist robots by providing rich visual and temporal priors beyond what real robot datasets contain. While existing video generative models produce impressive visual predictions, they are difficult to translate into low-level actions. Conversely, latent-action models better align videos with actions, but they typically operate at the single-step level and lack high-level planning capabilities. We bridge this gap by introducing Skill Abstraction from Optical Flow (SOF), a framework that learns latent skills from large collections of action-free videos. Our key idea is to learn a latent skill space through an intermediate representation based on optical flow that captures motion information aligned with both video dynamics and robot actions. By learning skills in this flow-based latent space, SOF enables high-level planning over video-derived skills and allows for easier translation of these skills into actions. Experiments show that our approach consistently improves performance in both multitask and long-horizon settings, demonstrating the ability to acquire and compose skills directly from raw visual data.
Attention Tracker: Detecting Prompt Injection Attacks in LLMs
Nov 01, 2024



Large Language Models (LLMs) have revolutionized various domains but remain vulnerable to prompt injection attacks, where malicious inputs manipulate the model into ignoring original instructions and executing designated action. In this paper, we investigate the underlying mechanisms of these attacks by analyzing the attention patterns within LLMs. We introduce the concept of the distraction effect, where specific attention heads, termed important heads, shift focus from the original instruction to the injected instruction. Building on this discovery, we propose Attention Tracker, a training-free detection method that tracks attention patterns on instruction to detect prompt injection attacks without the need for additional LLM inference. Our method generalizes effectively across diverse models, datasets, and attack types, showing an AUROC improvement of up to 10.0% over existing methods, and performs well even on small LLMs. We demonstrate the robustness of our approach through extensive evaluations and provide insights into safeguarding LLM-integrated systems from prompt injection vulnerabilities.
VICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation
May 26, 2024
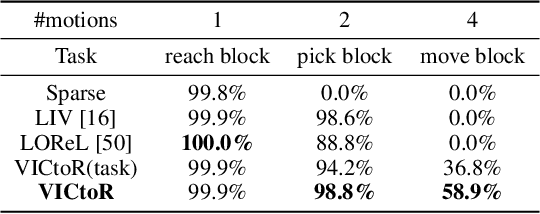
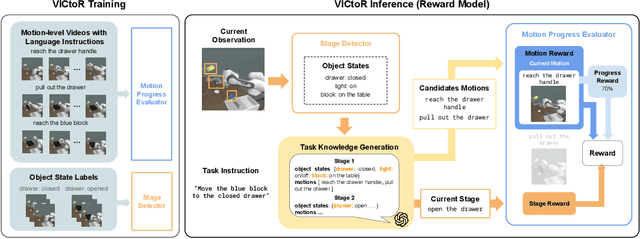
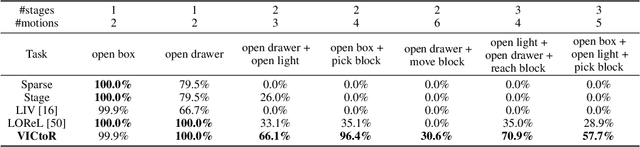
We study reward models for long-horizon manipulation tasks by learning from action-free videos and language instructions, which we term the visual-instruction correlation (VIC) problem. Recent advancements in cross-modality modeling have highlighted the potential of reward modeling through visual and language correlations. However, existing VIC methods face challenges in learning rewards for long-horizon tasks due to their lack of sub-stage awareness, difficulty in modeling task complexities, and inadequate object state estimation. To address these challenges, we introduce VICtoR, a novel hierarchical VIC reward model capable of providing effective reward signals for long-horizon manipulation tasks. VICtoR precisely assesses task progress at various levels through a novel stage detector and motion progress evaluator, offering insightful guidance for agents learning the task effectively. To validate the effectiveness of VICtoR, we conducted extensive experiments in both simulated and real-world environments. The results suggest that VICtoR outperformed the best existing VIC methods, achieving a 43% improvement in success rates for long-horizon tasks.
AED: Adaptable Error Detection for Few-shot Imitation Policy
Feb 06, 2024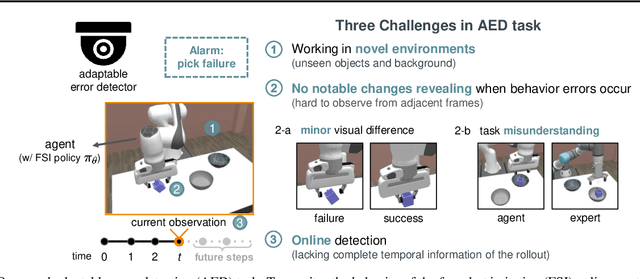

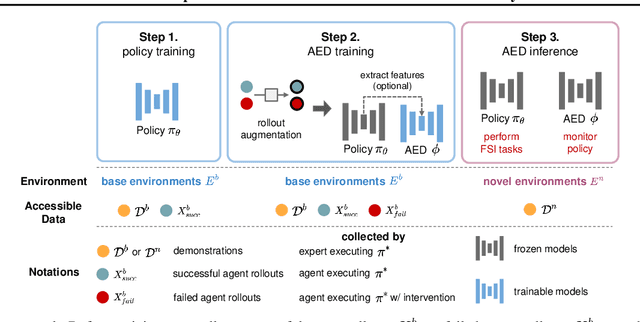
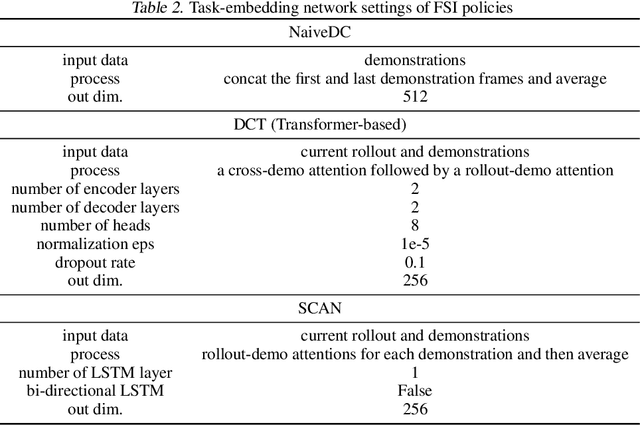
We study how to report few-shot imitation (FSI) policies' behavior errors in novel environments, a novel task named adaptable error detection (AED). The potential to cause serious damage to surrounding areas limits the application of FSI policies in real-world scenarios. Thus, a robust system is necessary to notify operators when FSI policies are inconsistent with the intent of demonstrations. We develop a cross-domain benchmark for the challenging AED task, consisting of 329 base and 158 novel environments. This task introduces three challenges, including (1) detecting behavior errors in novel environments, (2) behavior errors occurring without revealing notable changes, and (3) lacking complete temporal information of the rollout due to the necessity of online detection. To address these challenges, we propose Pattern Observer (PrObe) to parse discernible patterns in the policy feature representations of normal or error states, whose effectiveness is verified in the proposed benchmark. Through our comprehensive evaluation, PrObe consistently surpasses strong baselines and demonstrates a robust capability to identify errors arising from a wide range of FSI policies. Moreover, we conduct comprehensive ablations and experiments (error correction, demonstration quality, etc.) to validate the practicality of our proposed task and methodology.
Open-Domain Conversational Question Answering with Historical Answers
Nov 17, 2022Open-domain conversational question answering can be viewed as two tasks: passage retrieval and conversational question answering, where the former relies on selecting candidate passages from a large corpus and the latter requires better understanding of a question with contexts to predict the answers. This paper proposes ConvADR-QA that leverages historical answers to boost retrieval performance and further achieves better answering performance. In our proposed framework, the retrievers use a teacher-student framework to reduce noises from previous turns. Our experiments on the benchmark dataset, OR-QuAC, demonstrate that our model outperforms existing baselines in both extractive and generative reader settings, well justifying the effectiveness of historical answers for open-domain conversational question answering.