 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Efficient LLM Training with Lifetime-Aware Tensor Offloading via GPUDirect Storage
Jun 06, 2025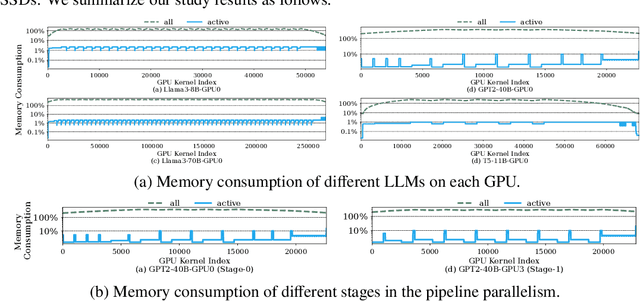

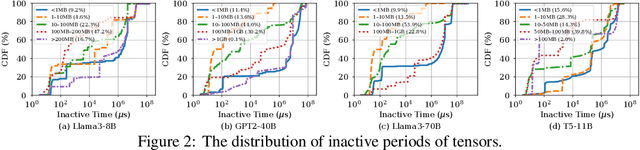

We present the design and implementation of a new lifetime-aware tensor offloading framework for GPU memory expansion using low-cost PCIe-based solid-state drives (SSDs). Our framework, TERAIO, is developed explicitly for large language model (LLM) training with multiple GPUs and multiple SSDs. Its design is driven by our observation that the active tensors take only a small fraction (1.7% on average) of allocated GPU memory in each LLM training iteration, the inactive tensors are usually large and will not be used for a long period of time, creating ample opportunities for offloading/prefetching tensors to/from slow SSDs without stalling the GPU training process. TERAIO accurately estimates the lifetime (active period of time in GPU memory) of each tensor with the profiling of the first few iterations in the training process. With the tensor lifetime analysis, TERAIO will generate an optimized tensor offloading/prefetching plan and integrate it into the compiled LLM program via PyTorch. TERAIO has a runtime tensor migration engine to execute the offloading/prefetching plan via GPUDirect storage, which allows direct tensor migration between GPUs and SSDs for alleviating the CPU bottleneck and maximizing the SSD bandwidth utilization. In comparison with state-of-the-art studies such as ZeRO-Offload and ZeRO-Infinity, we show that TERAIO improves the training performance of various LLMs by 1.47x on average, and achieves 80.7% of the ideal performance assuming unlimited GPU memory.
Understanding and Improving Training-Free AI-Generated Image Detections with Vision Foundation Models
Nov 28, 2024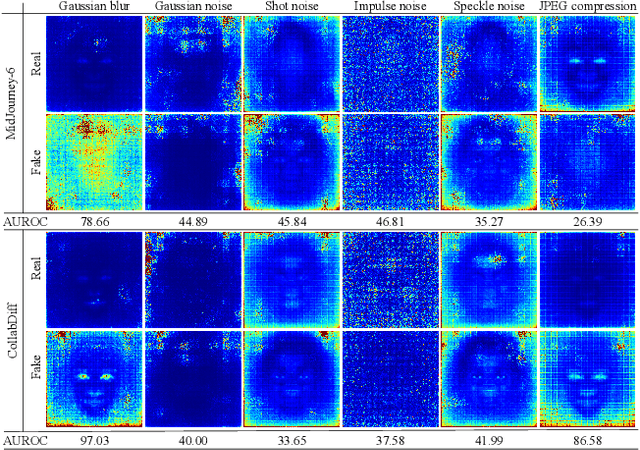
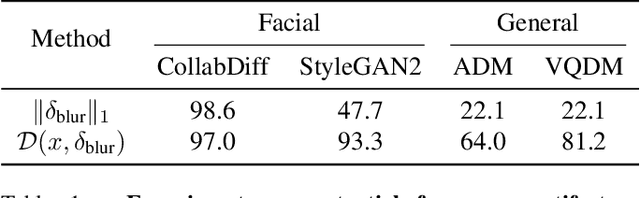
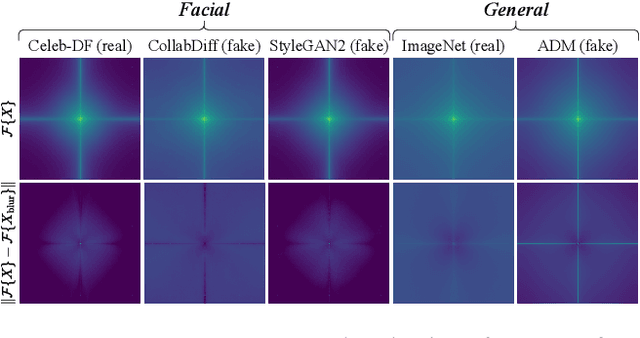
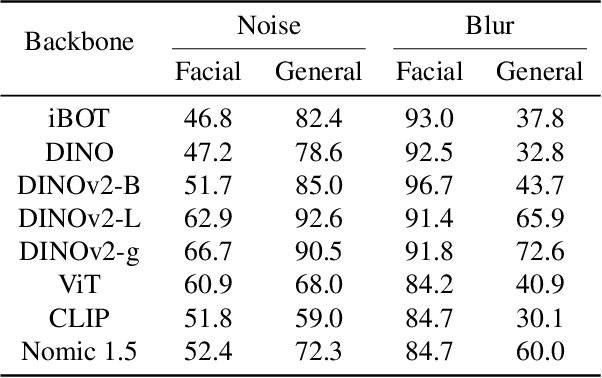
The rapid advancement of generative models has introduced serious risks, including deepfake techniques for facial synthesis and editing. Traditional approaches rely on training classifiers and enhancing generalizability through various feature extraction techniques. Meanwhile, training-free detection methods address issues like limited data and overfitting by directly leveraging statistical properties from vision foundation models to distinguish between real and fake images. The current leading training-free approach, RIGID, utilizes DINOv2 sensitivity to perturbations in image space for detecting fake images, with fake image embeddings exhibiting greater sensitivity than those of real images. This observation prompts us to investigate how detection performance varies across model backbones, perturbation types, and datasets. Our experiments reveal that detection performance is closely linked to model robustness, with self-supervised (SSL) models providing more reliable representations. While Gaussian noise effectively detects general objects, it performs worse on facial images, whereas Gaussian blur is more effective due to potential frequency artifacts. To further improve detection, we introduce Contrastive Blur, which enhances performance on facial images, and MINDER (MINimum distance DetEctoR), which addresses noise type bias, balancing performance across domains. Beyond performance gains, our work offers valuable insights for both the generative and detection communities, contributing to a deeper understanding of model robustness property utilized for deepfake detection.
Attention Tracker: Detecting Prompt Injection Attacks in LLMs
Nov 01, 2024



Large Language Models (LLMs) have revolutionized various domains but remain vulnerable to prompt injection attacks, where malicious inputs manipulate the model into ignoring original instructions and executing designated action. In this paper, we investigate the underlying mechanisms of these attacks by analyzing the attention patterns within LLMs. We introduce the concept of the distraction effect, where specific attention heads, termed important heads, shift focus from the original instruction to the injected instruction. Building on this discovery, we propose Attention Tracker, a training-free detection method that tracks attention patterns on instruction to detect prompt injection attacks without the need for additional LLM inference. Our method generalizes effectively across diverse models, datasets, and attack types, showing an AUROC improvement of up to 10.0% over existing methods, and performs well even on small LLMs. We demonstrate the robustness of our approach through extensive evaluations and provide insights into safeguarding LLM-integrated systems from prompt injection vulnerabilities.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024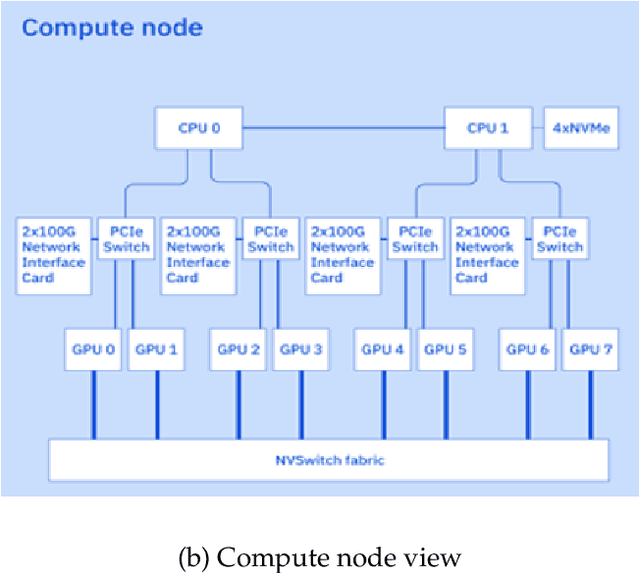
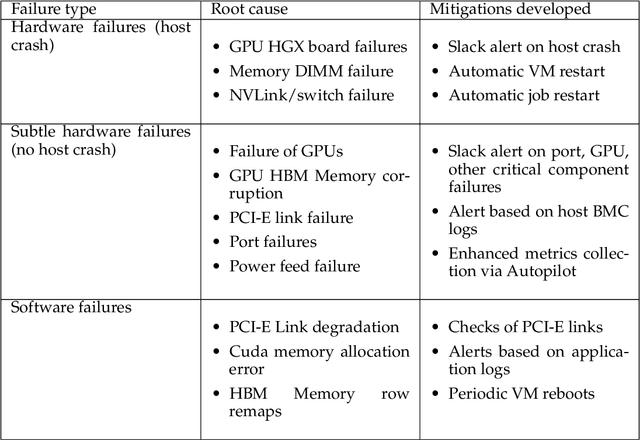
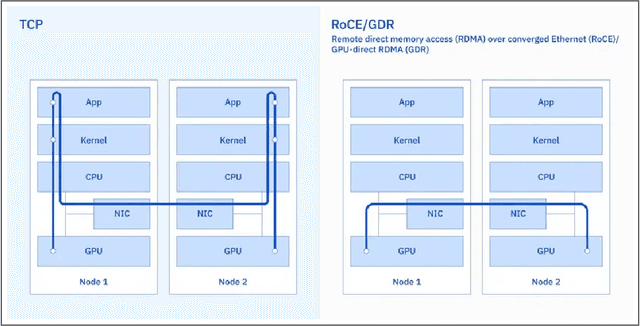
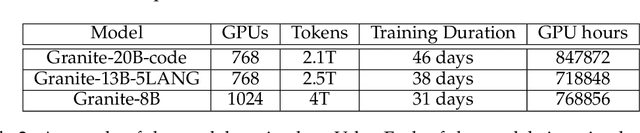
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
Data-Driven Lipschitz Continuity: A Cost-Effective Approach to Improve Adversarial Robustness
Jun 28, 2024



The security and robustness of deep neural networks (DNNs) have become increasingly concerning. This paper aims to provide both a theoretical foundation and a practical solution to ensure the reliability of DNNs. We explore the concept of Lipschitz continuity to certify the robustness of DNNs against adversarial attacks, which aim to mislead the network with adding imperceptible perturbations into inputs. We propose a novel algorithm that remaps the input domain into a constrained range, reducing the Lipschitz constant and potentially enhancing robustness. Unlike existing adversarially trained models, where robustness is enhanced by introducing additional examples from other datasets or generative models, our method is almost cost-free as it can be integrated with existing models without requiring re-training. Experimental results demonstrate the generalizability of our method, as it can be combined with various models and achieve enhancements in robustness. Furthermore, our method achieves the best robust accuracy for CIFAR10, CIFAR100, and ImageNet datasets on the RobustBench leaderboard.
Steal Now and Attack Later: Evaluating Robustness of Object Detection against Black-box Adversarial Attacks
Apr 24, 2024Latency attacks against object detection represent a variant of adversarial attacks that aim to inflate the inference time by generating additional ghost objects in a target image. However, generating ghost objects in the black-box scenario remains a challenge since information about these unqualified objects remains opaque. In this study, we demonstrate the feasibility of generating ghost objects in adversarial examples by extending the concept of "steal now, decrypt later" attacks. These adversarial examples, once produced, can be employed to exploit potential vulnerabilities in the AI service, giving rise to significant security concerns. The experimental results demonstrate that the proposed attack achieves successful attacks across various commonly used models and Google Vision API without any prior knowledge about the target model. Additionally, the average cost of each attack is less than \$ 1 dollars, posing a significant threat to AI security.
Overload: Latency Attacks on Object Detection for Edge Devices
Apr 12, 2023



Nowadays, the deployment of deep learning based applications on edge devices is an essential task owing to the increasing demands on intelligent services. However, the limited computing resources on edge nodes make the models vulnerable to attacks, such that the predictions made by models are unreliable. In this paper, we investigate latency attacks on deep learning applications. Unlike common adversarial attacks for misclassification, the goal of latency attacks is to increase the inference time, which may stop applications from responding to the requests within a reasonable time. This kind of attack is ubiquitous for various applications, and we use object detection to demonstrate how such kind of attacks work. We also design a framework named Overload to generate latency attacks at scale. Our method is based on a newly formulated optimization problem and a novel technique, called spatial attention, to increase the inference time of object detection. We have conducted experiments using YOLOv5 models on Nvidia NX. The experimental results show that with latency attacks, the inference time of a single image can be increased ten times longer in reference to the normal setting. Moreover, comparing to existing methods, our attacking method is simpler and more effective.