 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Training-Free AI-Generated Image Detections with Vision Foundation Models
Paper and Code
Nov 28, 2024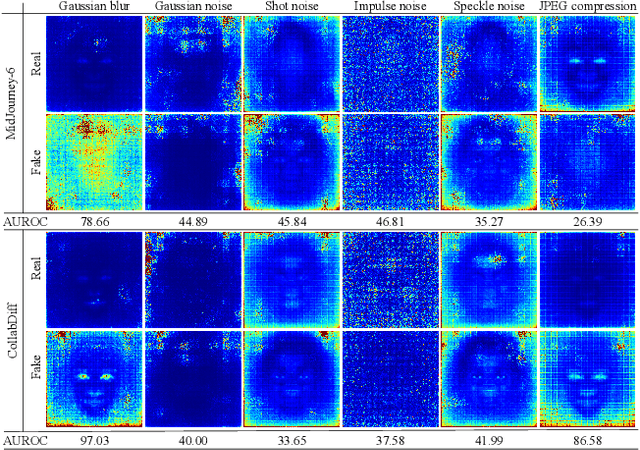
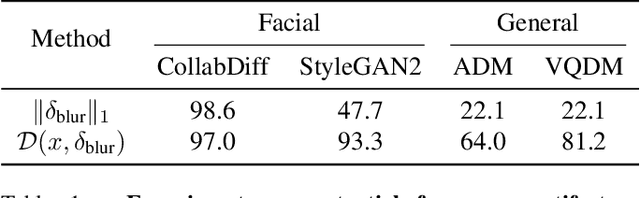
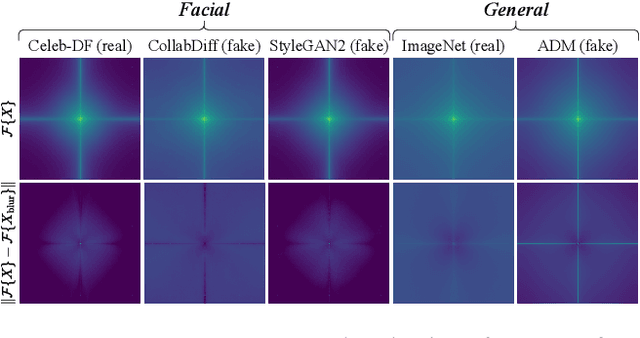
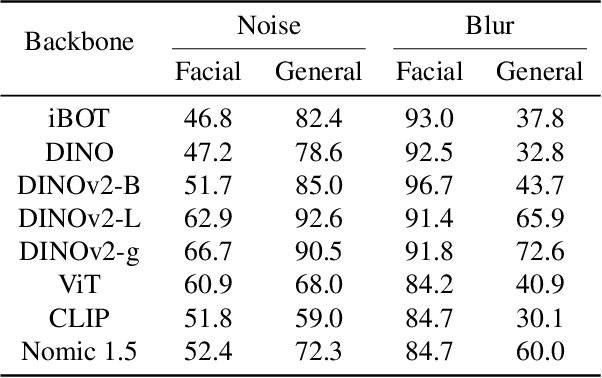
The rapid advancement of generative models has introduced serious risks, including deepfake techniques for facial synthesis and editing. Traditional approaches rely on training classifiers and enhancing generalizability through various feature extraction techniques. Meanwhile, training-free detection methods address issues like limited data and overfitting by directly leveraging statistical properties from vision foundation models to distinguish between real and fake images. The current leading training-free approach, RIGID, utilizes DINOv2 sensitivity to perturbations in image space for detecting fake images, with fake image embeddings exhibiting greater sensitivity than those of real images. This observation prompts us to investigate how detection performance varies across model backbones, perturbation types, and datasets. Our experiments reveal that detection performance is closely linked to model robustness, with self-supervised (SSL) models providing more reliable representations. While Gaussian noise effectively detects general objects, it performs worse on facial images, whereas Gaussian blur is more effective due to potential frequency artifacts. To further improve detection, we introduce Contrastive Blur, which enhances performance on facial images, and MINDER (MINimum distance DetEctoR), which addresses noise type bias, balancing performance across domains. Beyond performance gains, our work offers valuable insights for both the generative and detection communities, contributing to a deeper understanding of model robustness property utilized for deepfake detection.