 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Static Templates to Dynamic Runtime Graphs: A Survey of Workflow Optimization for LLM Agents
Mar 23, 2026Large language model (LLM)-based systems are becoming increasingly popular for solving tasks by constructing executable workflows that interleave LLM calls, information retrieval, tool use, code execution, memory updates, and verification. This survey reviews recent methods for designing and optimizing such workflows, which we treat as agentic computation graphs (ACGs). We organize the literature based on when workflow structure is determined, where structure refers to which components or agents are present, how they depend on each other, and how information flows between them. This lens distinguishes static methods, which fix a reusable workflow scaffold before deployment, from dynamic methods, which select, generate, or revise the workflow for a particular run before or during execution. We further organize prior work along three dimensions: when structure is determined, what part of the workflow is optimized, and which evaluation signals guide optimization (e.g., task metrics, verifier signals, preferences, or trace-derived feedback). We also distinguish reusable workflow templates, run-specific realized graphs, and execution traces, separating reusable design choices from the structures actually deployed in a given run and from realized runtime behavior. Finally, we outline a structure-aware evaluation perspective that complements downstream task metrics with graph-level properties, execution cost, robustness, and structural variation across inputs. Our goal is to provide a clear vocabulary, a unified framework for positioning new methods, a more comparable view of existing body of literature, and a more reproducible evaluation standard for future work in workflow optimizations for LLM agents.
Learning Rate Matters: Vanilla LoRA May Suffice for LLM Fine-tuning
Feb 04, 2026Low-Rank Adaptation (LoRA) is the prevailing approach for efficient large language model (LLM) fine-tuning. Building on this paradigm, recent studies have proposed alternative initialization strategies and architectural modifications, reporting substantial improvements over vanilla LoRA. However, these gains are often demonstrated under fixed or narrowly tuned hyperparameter settings, despite the known sensitivity of neural networks to training configurations. In this work, we systematically re-evaluate four representative LoRA variants alongside vanilla LoRA through extensive hyperparameter searches. Across mathematical and code generation tasks on diverse model scales, we find that different LoRA methods favor distinct learning rate ranges. Crucially, once learning rates are properly tuned, all methods achieve similar peak performance (within 1-2%), with only subtle rank-dependent behaviors. These results suggest that vanilla LoRA remains a competitive baseline and that improvements reported under single training configuration may not reflect consistent methodological advantages. Finally, a second-order analysis attributes the differing optimal learning rate ranges to variations in the largest Hessian eigenvalue, aligning with classical learning theories.
Steering Externalities: Benign Activation Steering Unintentionally Increases Jailbreak Risk for Large Language Models
Feb 03, 2026Activation steering is a practical post-training model alignment technique to enhance the utility of Large Language Models (LLMs). Prior to deploying a model as a service, developers can steer a pre-trained model toward specific behavioral objectives, such as compliance or instruction adherence, without the need for retraining. This process is as simple as adding a steering vector to the model's internal representations. However, this capability unintentionally introduces critical and under-explored safety risks. We identify a phenomenon termed Steering Externalities, where steering vectors derived from entirely benign datasets-such as those enforcing strict compliance or specific output formats like JSON-inadvertently erode safety guardrails. Experiments reveal that these interventions act as a force multiplier, creating new vulnerabilities to jailbreaks and increasing attack success rates to over 80% on standard benchmarks by bypassing the initial safety alignment. Ultimately, our results expose a critical blind spot in deployment: benign activation steering systematically erodes the "safety margin," rendering models more vulnerable to black-box attacks and proving that inference-time utility improvements must be rigorously audited for unintended safety externalities.
EARL: Entropy-Aware RL Alignment of LLMs for Reliable RTL Code Generation
Nov 15, 2025Recent advances in large language models (LLMs) have demonstrated significant potential in hardware design automation, particularly in using natural language to synthesize Register-Transfer Level (RTL) code. Despite this progress, a gap remains between model capability and the demands of real-world RTL design, including syntax errors, functional hallucinations, and weak alignment to designer intent. Reinforcement Learning with Verifiable Rewards (RLVR) offers a promising approach to bridge this gap, as hardware provides executable and formally checkable signals that can be used to further align model outputs with design intent. However, in long, structured RTL code sequences, not all tokens contribute equally to functional correctness, and naïvely spreading gradients across all tokens dilutes learning signals. A key insight from our entropy analysis in RTL generation is that only a small fraction of tokens (e.g., always, if, assign, posedge) exhibit high uncertainty and largely influence control flow and module structure. To address these challenges, we present EARL, an Entropy-Aware Reinforcement Learning framework for Verilog generation. EARL performs policy optimization using verifiable reward signals and introduces entropy-guided selective updates that gate policy gradients to high-entropy tokens. This approach preserves training stability and concentrates gradient updates on functionally important regions of code. Our experiments on VerilogEval and RTLLM show that EARL improves functional pass rates over prior LLM baselines by up to 14.7%, while reducing unnecessary updates and improving training stability. These results indicate that focusing RL on critical, high-uncertainty tokens enables more reliable and targeted policy improvement for structured RTL code generation.
Patching LLM Like Software: A Lightweight Method for Improving Safety Policy in Large Language Models
Nov 11, 2025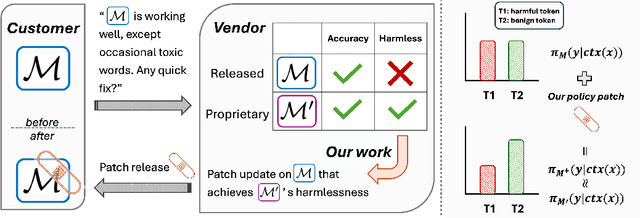
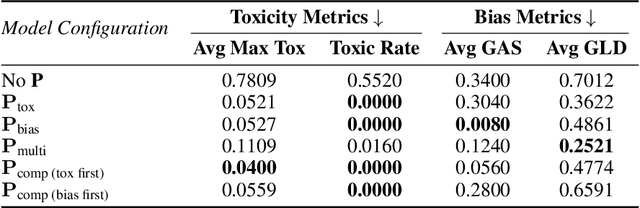
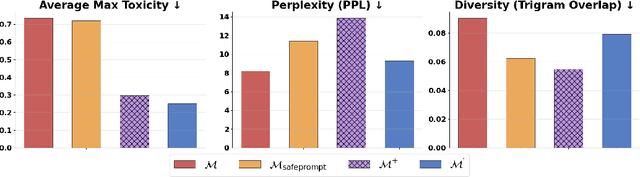
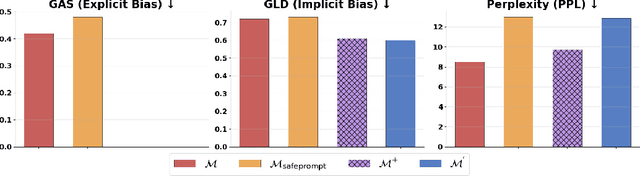
We propose patching for large language models (LLMs) like software versions, a lightweight and modular approach for addressing safety vulnerabilities. While vendors release improved LLM versions, major releases are costly, infrequent, and difficult to tailor to customer needs, leaving released models with known safety gaps. Unlike full-model fine-tuning or major version updates, our method enables rapid remediation by prepending a compact, learnable prefix to an existing model. This "patch" introduces only 0.003% additional parameters, yet reliably steers model behavior toward that of a safer reference model. Across three critical domains (toxicity mitigation, bias reduction, and harmfulness refusal) policy patches achieve safety improvements comparable to next-generation safety-aligned models while preserving fluency. Our results demonstrate that LLMs can be "patched" much like software, offering vendors and practitioners a practical mechanism for distributing scalable, efficient, and composable safety updates between major model releases.
Can Memory-Augmented Language Models Generalize on Reasoning-in-a-Haystack Tasks?
Mar 10, 2025Large language models often expose their brittleness in reasoning tasks, especially while executing long chains of reasoning over context. We propose MemReasoner, a new and simple memory-augmented LLM architecture, in which the memory learns the relative order of facts in context, and enables hopping over them, while the decoder selectively attends to the memory. MemReasoner is trained end-to-end, with optional supporting fact supervision of varying degrees. We train MemReasoner, along with existing memory-augmented transformer models and a state-space model, on two distinct synthetic multi-hop reasoning tasks. Experiments performed under a variety of challenging scenarios, including the presence of long distractor text or target answer changes in test set, show strong generalization of MemReasoner on both single- and two-hop tasks. This generalization of MemReasoner is achieved using none-to-weak supporting fact supervision (using none and 1\% of supporting facts for one- and two-hop tasks, respectively). In contrast, baseline models overall struggle to generalize and benefit far less from using full supporting fact supervision. The results highlight the importance of explicit memory mechanisms, combined with additional weak supervision, for improving large language model's context processing ability toward reasoning tasks.
Understanding and Improving Training-Free AI-Generated Image Detections with Vision Foundation Models
Nov 28, 2024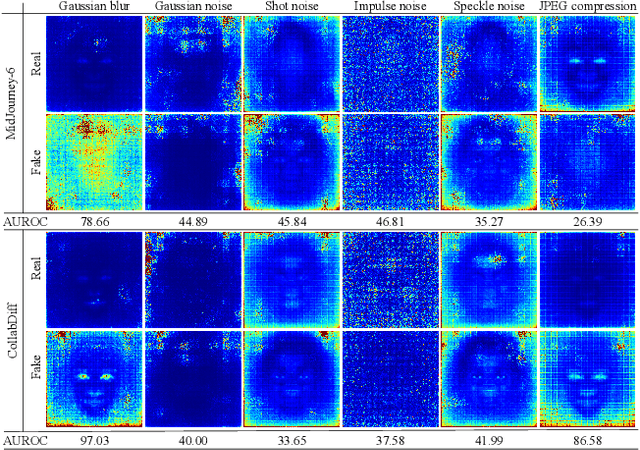
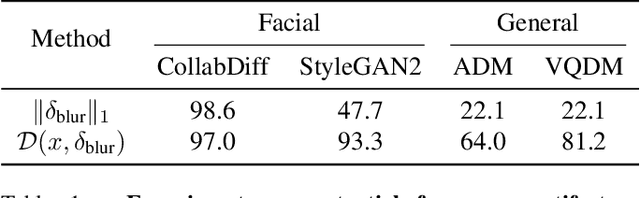
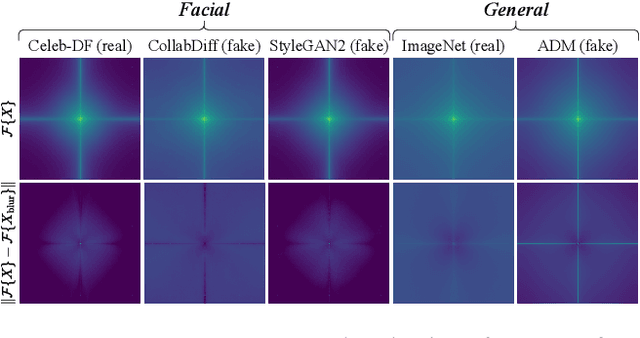
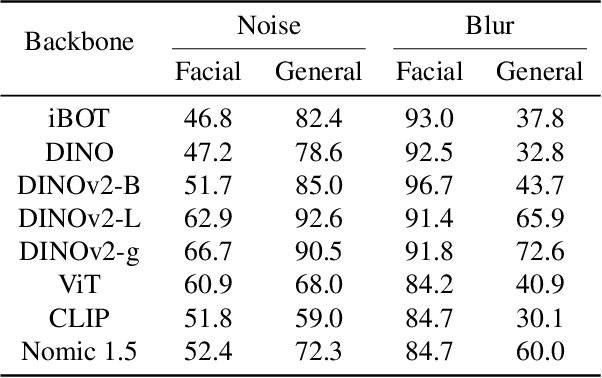
The rapid advancement of generative models has introduced serious risks, including deepfake techniques for facial synthesis and editing. Traditional approaches rely on training classifiers and enhancing generalizability through various feature extraction techniques. Meanwhile, training-free detection methods address issues like limited data and overfitting by directly leveraging statistical properties from vision foundation models to distinguish between real and fake images. The current leading training-free approach, RIGID, utilizes DINOv2 sensitivity to perturbations in image space for detecting fake images, with fake image embeddings exhibiting greater sensitivity than those of real images. This observation prompts us to investigate how detection performance varies across model backbones, perturbation types, and datasets. Our experiments reveal that detection performance is closely linked to model robustness, with self-supervised (SSL) models providing more reliable representations. While Gaussian noise effectively detects general objects, it performs worse on facial images, whereas Gaussian blur is more effective due to potential frequency artifacts. To further improve detection, we introduce Contrastive Blur, which enhances performance on facial images, and MINDER (MINimum distance DetEctoR), which addresses noise type bias, balancing performance across domains. Beyond performance gains, our work offers valuable insights for both the generative and detection communities, contributing to a deeper understanding of model robustness property utilized for deepfake detection.
Attention Tracker: Detecting Prompt Injection Attacks in LLMs
Nov 01, 2024



Large Language Models (LLMs) have revolutionized various domains but remain vulnerable to prompt injection attacks, where malicious inputs manipulate the model into ignoring original instructions and executing designated action. In this paper, we investigate the underlying mechanisms of these attacks by analyzing the attention patterns within LLMs. We introduce the concept of the distraction effect, where specific attention heads, termed important heads, shift focus from the original instruction to the injected instruction. Building on this discovery, we propose Attention Tracker, a training-free detection method that tracks attention patterns on instruction to detect prompt injection attacks without the need for additional LLM inference. Our method generalizes effectively across diverse models, datasets, and attack types, showing an AUROC improvement of up to 10.0% over existing methods, and performs well even on small LLMs. We demonstrate the robustness of our approach through extensive evaluations and provide insights into safeguarding LLM-integrated systems from prompt injection vulnerabilities.
Large Language Models can be Strong Self-Detoxifiers
Oct 04, 2024Reducing the likelihood of generating harmful and toxic output is an essential task when aligning large language models (LLMs). Existing methods mainly rely on training an external reward model (i.e., another language model) or fine-tuning the LLM using self-generated data to influence the outcome. In this paper, we show that LLMs have the capability of self-detoxification without the use of an additional reward model or re-training. We propose \textit{Self-disciplined Autoregressive Sampling (SASA)}, a lightweight controlled decoding algorithm for toxicity reduction of LLMs. SASA leverages the contextual representations from an LLM to learn linear subspaces characterizing toxic v.s. non-toxic output in analytical forms. When auto-completing a response token-by-token, SASA dynamically tracks the margin of the current output to steer the generation away from the toxic subspace, by adjusting the autoregressive sampling strategy. Evaluated on LLMs of different scale and nature, namely Llama-3.1-Instruct (8B), Llama-2 (7B), and GPT2-L models with the RealToxicityPrompts, BOLD, and AttaQ benchmarks, SASA markedly enhances the quality of the generated sentences relative to the original models and attains comparable performance to state-of-the-art detoxification techniques, significantly reducing the toxicity level by only using the LLM's internal representations.
Sample-Specific Debiasing for Better Image-Text Models
Apr 25, 2023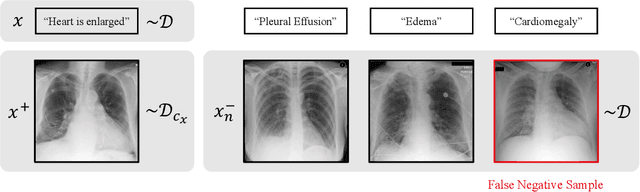
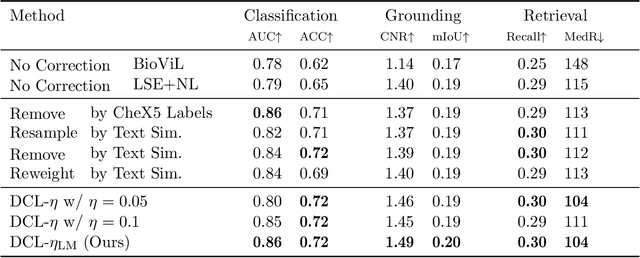
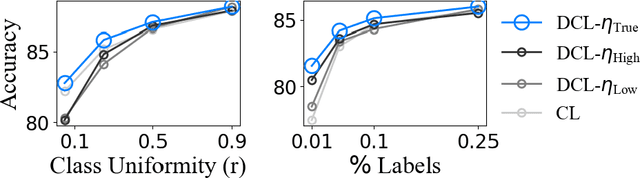

Self-supervised representation learning on image-text data facilitates crucial medical applications, such as image classification, visual grounding, and cross-modal retrieval. One common approach involves contrasting semantically similar (positive) and dissimilar (negative) pairs of data points. Drawing negative samples uniformly from the training data set introduces false negatives, i.e., samples that are treated as dissimilar but belong to the same class. In healthcare data, the underlying class distribution is nonuniform, implying that false negatives occur at a highly variable rate. To improve the quality of learned representations, we develop a novel approach that corrects for false negatives. Our method can be viewed as a variant of debiased constrastive learning that uses estimated sample-specific class probabilities. We provide theoretical analysis of the objective function and demonstrate the proposed approach on both image and paired image-text data sets. Our experiments demonstrate empirical advantages of sample-specific debiasing.