 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Sense Embeddings for Language Models and Knowledge Distillation
Apr 08, 2025Transformer-based large language models (LLMs) rely on contextual embeddings which generate different (continuous) representations for the same token depending on its surrounding context. Nonetheless, words and tokens typically have a limited number of senses (or meanings). We propose multi-sense embeddings as a drop-in replacement for each token in order to capture the range of their uses in a language. To construct a sense embedding dictionary, we apply a clustering algorithm to embeddings generated by an LLM and consider the cluster centers as representative sense embeddings. In addition, we propose a novel knowledge distillation method that leverages the sense dictionary to learn a smaller student model that mimics the senses from the much larger base LLM model, offering significant space and inference time savings, while maintaining competitive performance. Via thorough experiments on various benchmarks, we showcase the effectiveness of our sense embeddings and knowledge distillation approach. We share our code at https://github.com/Qitong-Wang/SenseDict
Can Memory-Augmented Language Models Generalize on Reasoning-in-a-Haystack Tasks?
Mar 10, 2025Large language models often expose their brittleness in reasoning tasks, especially while executing long chains of reasoning over context. We propose MemReasoner, a new and simple memory-augmented LLM architecture, in which the memory learns the relative order of facts in context, and enables hopping over them, while the decoder selectively attends to the memory. MemReasoner is trained end-to-end, with optional supporting fact supervision of varying degrees. We train MemReasoner, along with existing memory-augmented transformer models and a state-space model, on two distinct synthetic multi-hop reasoning tasks. Experiments performed under a variety of challenging scenarios, including the presence of long distractor text or target answer changes in test set, show strong generalization of MemReasoner on both single- and two-hop tasks. This generalization of MemReasoner is achieved using none-to-weak supporting fact supervision (using none and 1\% of supporting facts for one- and two-hop tasks, respectively). In contrast, baseline models overall struggle to generalize and benefit far less from using full supporting fact supervision. The results highlight the importance of explicit memory mechanisms, combined with additional weak supervision, for improving large language model's context processing ability toward reasoning tasks.
EpMAN: Episodic Memory AttentioN for Generalizing to Longer Contexts
Feb 20, 2025



Recent advances in Large Language Models (LLMs) have yielded impressive successes on many language tasks. However, efficient processing of long contexts using LLMs remains a significant challenge. We introduce \textbf{EpMAN} -- a method for processing long contexts in an \textit{episodic memory} module while \textit{holistically attending to} semantically relevant context chunks. The output of \textit{episodic attention} is then used to reweigh the decoder's self-attention to the stored KV cache of the context during training and generation. When an LLM decoder is trained using \textbf{EpMAN}, its performance on multiple challenging single-hop long-context recall and question-answering benchmarks is found to be stronger and more robust across the range from 16k to 256k tokens than baseline decoders trained with self-attention, and popular retrieval-augmented generation frameworks.
Large Language Models can be Strong Self-Detoxifiers
Oct 04, 2024Reducing the likelihood of generating harmful and toxic output is an essential task when aligning large language models (LLMs). Existing methods mainly rely on training an external reward model (i.e., another language model) or fine-tuning the LLM using self-generated data to influence the outcome. In this paper, we show that LLMs have the capability of self-detoxification without the use of an additional reward model or re-training. We propose \textit{Self-disciplined Autoregressive Sampling (SASA)}, a lightweight controlled decoding algorithm for toxicity reduction of LLMs. SASA leverages the contextual representations from an LLM to learn linear subspaces characterizing toxic v.s. non-toxic output in analytical forms. When auto-completing a response token-by-token, SASA dynamically tracks the margin of the current output to steer the generation away from the toxic subspace, by adjusting the autoregressive sampling strategy. Evaluated on LLMs of different scale and nature, namely Llama-3.1-Instruct (8B), Llama-2 (7B), and GPT2-L models with the RealToxicityPrompts, BOLD, and AttaQ benchmarks, SASA markedly enhances the quality of the generated sentences relative to the original models and attains comparable performance to state-of-the-art detoxification techniques, significantly reducing the toxicity level by only using the LLM's internal representations.
Generation Constraint Scaling Can Mitigate Hallucination
Jul 23, 2024Addressing the issue of hallucinations in large language models (LLMs) is a critical challenge. As the cognitive mechanisms of hallucination have been related to memory, here we explore hallucination for LLM that is enabled with explicit memory mechanisms. We empirically demonstrate that by simply scaling the readout vector that constrains generation in a memory-augmented LLM decoder, hallucination mitigation can be achieved in a training-free manner. Our method is geometry-inspired and outperforms a state-of-the-art LLM editing method on the task of generation of Wikipedia-like biography entries both in terms of generation quality and runtime complexity.
Needle in the Haystack for Memory Based Large Language Models
Jul 01, 2024


In this paper, we demonstrate the benefits of using memory augmented Large Language Model (LLM) architecture in improving the recall abilities of facts from a potentially long context. As a case study we test LARIMAR, a recently proposed LLM architecture which augments a LLM decoder with an external associative memory, on several long-context recall tasks, including passkey and needle-in-the-haystack tests. We demonstrate that the external memory can be adapted at test time to handle contexts much longer than those seen during training, while keeping readouts from the memory recognizable to the trained decoder and without increasing GPU memory footprint. Compared to alternative architectures for long-context recall tasks with models of a comparable parameter count, LARIMAR is able to maintain strong performance without any task-specific training.
Larimar: Large Language Models with Episodic Memory Control
Mar 18, 2024Efficient and accurate updating of knowledge stored in Large Language Models (LLMs) is one of the most pressing research challenges today. This paper presents Larimar - a novel, brain-inspired architecture for enhancing LLMs with a distributed episodic memory. Larimar's memory allows for dynamic, one-shot updates of knowledge without the need for computationally expensive re-training or fine-tuning. Experimental results on multiple fact editing benchmarks demonstrate that Larimar attains accuracy comparable to most competitive baselines, even in the challenging sequential editing setup, but also excels in speed - yielding speed-ups of 4-10x depending on the base LLM - as well as flexibility due to the proposed architecture being simple, LLM-agnostic, and hence general. We further provide mechanisms for selective fact forgetting and input context length generalization with Larimar and show their effectiveness.
Learning Granger Causality from Instance-wise Self-attentive Hawkes Processes
Feb 06, 2024We address the problem of learning Granger causality from asynchronous, interdependent, multi-type event sequences. In particular, we are interested in discovering instance-level causal structures in an unsupervised manner. Instance-level causality identifies causal relationships among individual events, providing more fine-grained information for decision-making. Existing work in the literature either requires strong assumptions, such as linearity in the intensity function, or heuristically defined model parameters that do not necessarily meet the requirements of Granger causality. We propose Instance-wise Self-Attentive Hawkes Processes (ISAHP), a novel deep learning framework that can directly infer the Granger causality at the event instance level. ISAHP is the first neural point process model that meets the requirements of Granger causality. It leverages the self-attention mechanism of the transformer to align with the principles of Granger causality. We empirically demonstrate that ISAHP is capable of discovering complex instance-level causal structures that cannot be handled by classical models. We also show that ISAHP achieves state-of-the-art performance in proxy tasks involving type-level causal discovery and instance-level event type prediction.
Cardinality-Regularized Hawkes-Granger Model
Aug 23, 2022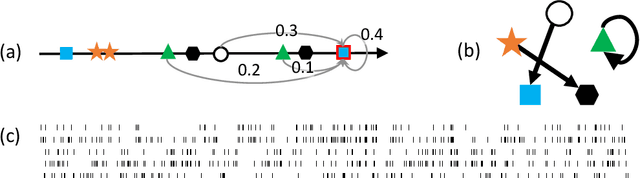
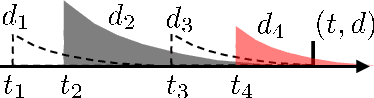

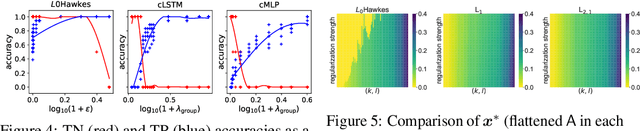
We propose a new sparse Granger-causal learning framework for temporal event data. We focus on a specific class of point processes called the Hawkes process. We begin by pointing out that most of the existing sparse causal learning algorithms for the Hawkes process suffer from a singularity in maximum likelihood estimation. As a result, their sparse solutions can appear only as numerical artifacts. In this paper, we propose a mathematically well-defined sparse causal learning framework based on a cardinality-regularized Hawkes process, which remedies the pathological issues of existing approaches. We leverage the proposed algorithm for the task of instance-wise causal event analysis, where sparsity plays a critical role. We validate the proposed framework with two real use-cases, one from the power grid and the other from the cloud data center management domain.
Directed Graph Auto-Encoders
Feb 25, 2022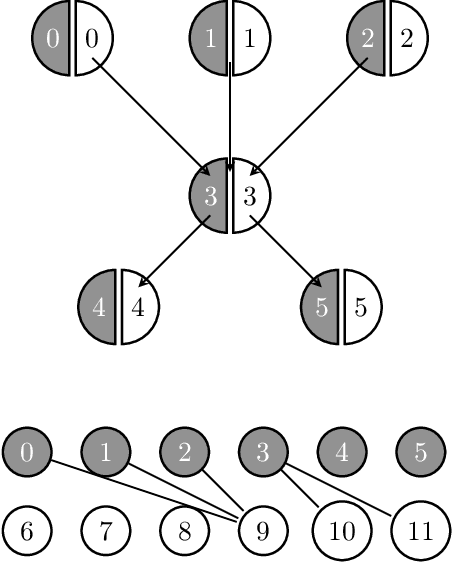

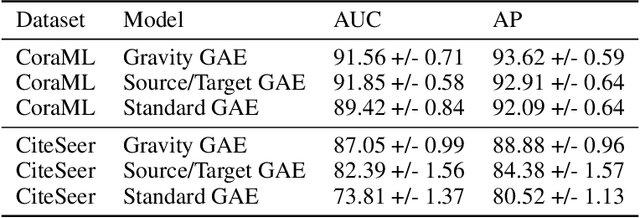

We introduce a new class of auto-encoders for directed graphs, motivated by a direct extension of the Weisfeiler-Leman algorithm to pairs of node labels. The proposed model learns pairs of interpretable latent representations for the nodes of directed graphs, and uses parameterized graph convolutional network (GCN) layers for its encoder and an asymmetric inner product decoder. Parameters in the encoder control the weighting of representations exchanged between neighboring nodes. We demonstrate the ability of the proposed model to learn meaningful latent embeddings and achieve superior performance on the directed link prediction task on several popular network datasets.