 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Protein Conformation Ensemble Generation with Physical Feedback
May 30, 2025Protein dynamics play a crucial role in protein biological functions and properties, and their traditional study typically relies on time-consuming molecular dynamics (MD) simulations conducted in silico. Recent advances in generative modeling, particularly denoising diffusion models, have enabled efficient accurate protein structure prediction and conformation sampling by learning distributions over crystallographic structures. However, effectively integrating physical supervision into these data-driven approaches remains challenging, as standard energy-based objectives often lead to intractable optimization. In this paper, we introduce Energy-based Alignment (EBA), a method that aligns generative models with feedback from physical models, efficiently calibrating them to appropriately balance conformational states based on their energy differences. Experimental results on the MD ensemble benchmark demonstrate that EBA achieves state-of-the-art performance in generating high-quality protein ensembles. By improving the physical plausibility of generated structures, our approach enhances model predictions and holds promise for applications in structural biology and drug discovery.
Larimar: Large Language Models with Episodic Memory Control
Mar 18, 2024Efficient and accurate updating of knowledge stored in Large Language Models (LLMs) is one of the most pressing research challenges today. This paper presents Larimar - a novel, brain-inspired architecture for enhancing LLMs with a distributed episodic memory. Larimar's memory allows for dynamic, one-shot updates of knowledge without the need for computationally expensive re-training or fine-tuning. Experimental results on multiple fact editing benchmarks demonstrate that Larimar attains accuracy comparable to most competitive baselines, even in the challenging sequential editing setup, but also excels in speed - yielding speed-ups of 4-10x depending on the base LLM - as well as flexibility due to the proposed architecture being simple, LLM-agnostic, and hence general. We further provide mechanisms for selective fact forgetting and input context length generalization with Larimar and show their effectiveness.
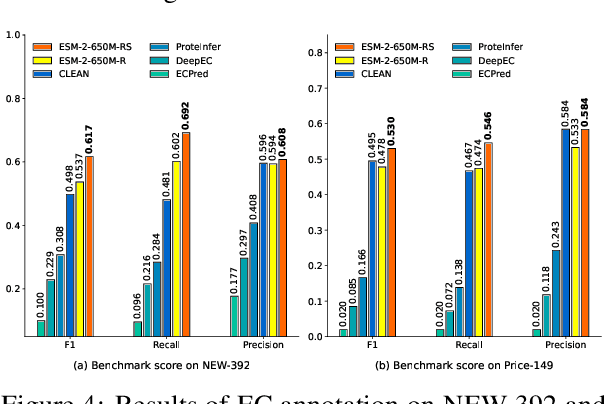
ProtIR: Iterative Refinement between Retrievers and Predictors for Protein Function Annotation
Feb 10, 2024
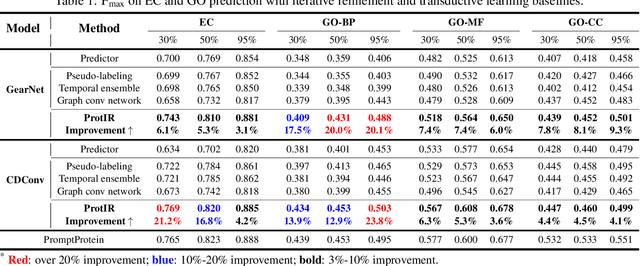
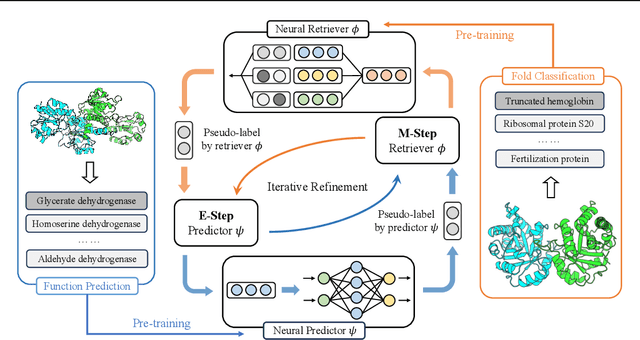

Protein function annotation is an important yet challenging task in biology. Recent deep learning advancements show significant potential for accurate function prediction by learning from protein sequences and structures. Nevertheless, these predictor-based methods often overlook the modeling of protein similarity, an idea commonly employed in traditional approaches using sequence or structure retrieval tools. To fill this gap, we first study the effect of inter-protein similarity modeling by benchmarking retriever-based methods against predictors on protein function annotation tasks. Our results show that retrievers can match or outperform predictors without large-scale pre-training. Building on these insights, we introduce a novel variational pseudo-likelihood framework, ProtIR, designed to improve function predictors by incorporating inter-protein similarity modeling. This framework iteratively refines knowledge between a function predictor and retriever, thereby combining the strengths of both predictors and retrievers. ProtIR showcases around 10% improvement over vanilla predictor-based methods. Besides, it achieves performance on par with protein language model-based methods, yet without the need for massive pre-training, highlighting the efficacy of our framework. Code will be released upon acceptance.
Structure-Informed Protein Language Model
Feb 07, 2024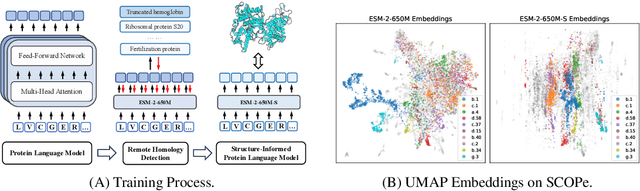
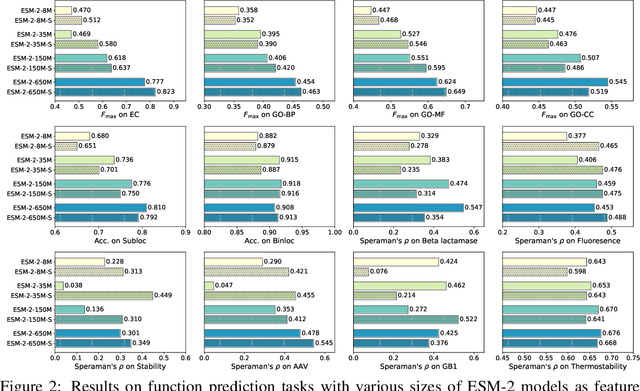
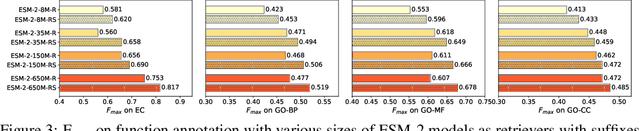
Protein language models are a powerful tool for learning protein representations through pre-training on vast protein sequence datasets. However, traditional protein language models lack explicit structural supervision, despite its relevance to protein function. To address this issue, we introduce the integration of remote homology detection to distill structural information into protein language models without requiring explicit protein structures as input. We evaluate the impact of this structure-informed training on downstream protein function prediction tasks. Experimental results reveal consistent improvements in function annotation accuracy for EC number and GO term prediction. Performance on mutant datasets, however, varies based on the relationship between targeted properties and protein structures. This underscores the importance of considering this relationship when applying structure-aware training to protein function prediction tasks. Code and model weights are available at https://github.com/DeepGraphLearning/esm-s.
Learning Granger Causality from Instance-wise Self-attentive Hawkes Processes
Feb 06, 2024We address the problem of learning Granger causality from asynchronous, interdependent, multi-type event sequences. In particular, we are interested in discovering instance-level causal structures in an unsupervised manner. Instance-level causality identifies causal relationships among individual events, providing more fine-grained information for decision-making. Existing work in the literature either requires strong assumptions, such as linearity in the intensity function, or heuristically defined model parameters that do not necessarily meet the requirements of Granger causality. We propose Instance-wise Self-Attentive Hawkes Processes (ISAHP), a novel deep learning framework that can directly infer the Granger causality at the event instance level. ISAHP is the first neural point process model that meets the requirements of Granger causality. It leverages the self-attention mechanism of the transformer to align with the principles of Granger causality. We empirically demonstrate that ISAHP is capable of discovering complex instance-level causal structures that cannot be handled by classical models. We also show that ISAHP achieves state-of-the-art performance in proxy tasks involving type-level causal discovery and instance-level event type prediction.
Enhancing Protein Language Models with Structure-based Encoder and Pre-training
Mar 11, 2023Protein language models (PLMs) pre-trained on large-scale protein sequence corpora have achieved impressive performance on various downstream protein understanding tasks. Despite the ability to implicitly capture inter-residue contact information, transformer-based PLMs cannot encode protein structures explicitly for better structure-aware protein representations. Besides, the power of pre-training on available protein structures has not been explored for improving these PLMs, though structures are important to determine functions. To tackle these limitations, in this work, we enhance the PLMs with structure-based encoder and pre-training. We first explore feasible model architectures to combine the advantages of a state-of-the-art PLM (i.e., ESM-1b1) and a state-of-the-art protein structure encoder (i.e., GearNet). We empirically verify the ESM-GearNet that connects two encoders in a series way as the most effective combination model. To further improve the effectiveness of ESM-GearNet, we pre-train it on massive unlabeled protein structures with contrastive learning, which aligns representations of co-occurring subsequences so as to capture their biological correlation. Extensive experiments on EC and GO protein function prediction benchmarks demonstrate the superiority of ESM-GearNet over previous PLMs and structure encoders, and clear performance gains are further achieved by structure-based pre-training upon ESM-GearNet. Our implementation is available at https://github.com/DeepGraphLearning/GearNet.
Physics-Inspired Protein Encoder Pre-Training via Siamese Sequence-Structure Diffusion Trajectory Prediction
Jan 28, 2023Pre-training methods on proteins are recently gaining interest, leveraging either protein sequences or structures, while modeling their joint energy landscape is largely unexplored. In this work, inspired by the success of denoising diffusion models, we propose the DiffPreT approach to pre-train a protein encoder by sequence-structure multimodal diffusion modeling. DiffPreT guides the encoder to recover the native protein sequences and structures from the perturbed ones along the multimodal diffusion trajectory, which acquires the joint distribution of sequences and structures. Considering the essential protein conformational variations, we enhance DiffPreT by a physics-inspired method called Siamese Diffusion Trajectory Prediction (SiamDiff) to capture the correlation between different conformers of a protein. SiamDiff attains this goal by maximizing the mutual information between representations of diffusion trajectories of structurally-correlated conformers. We study the effectiveness of DiffPreT and SiamDiff on both atom- and residue-level structure-based protein understanding tasks. Experimental results show that the performance of DiffPreT is consistently competitive on all tasks, and SiamDiff achieves new state-of-the-art performance, considering the mean ranks on all tasks. The source code will be released upon acceptance.
Directed Graph Auto-Encoders
Feb 25, 2022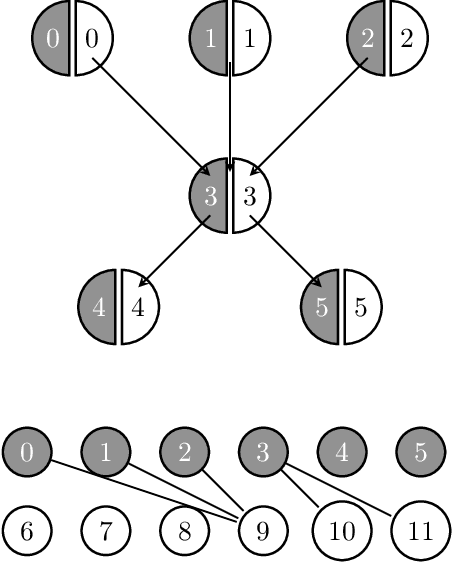

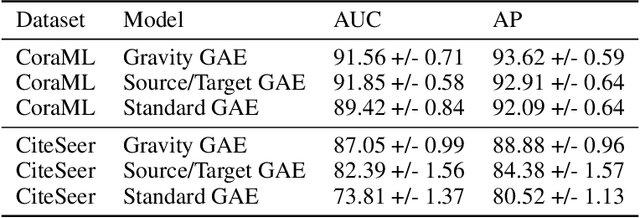

We introduce a new class of auto-encoders for directed graphs, motivated by a direct extension of the Weisfeiler-Leman algorithm to pairs of node labels. The proposed model learns pairs of interpretable latent representations for the nodes of directed graphs, and uses parameterized graph convolutional network (GCN) layers for its encoder and an asymmetric inner product decoder. Parameters in the encoder control the weighting of representations exchanged between neighboring nodes. We demonstrate the ability of the proposed model to learn meaningful latent embeddings and achieve superior performance on the directed link prediction task on several popular network datasets.
Simultaneous Parameter Learning and Bi-Clustering for Multi-Response Models
Apr 29, 2018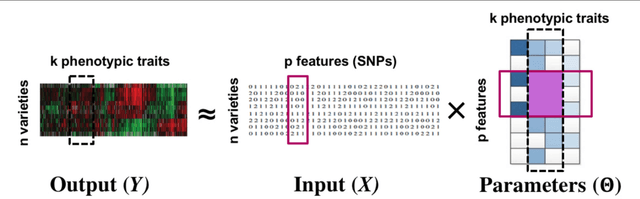
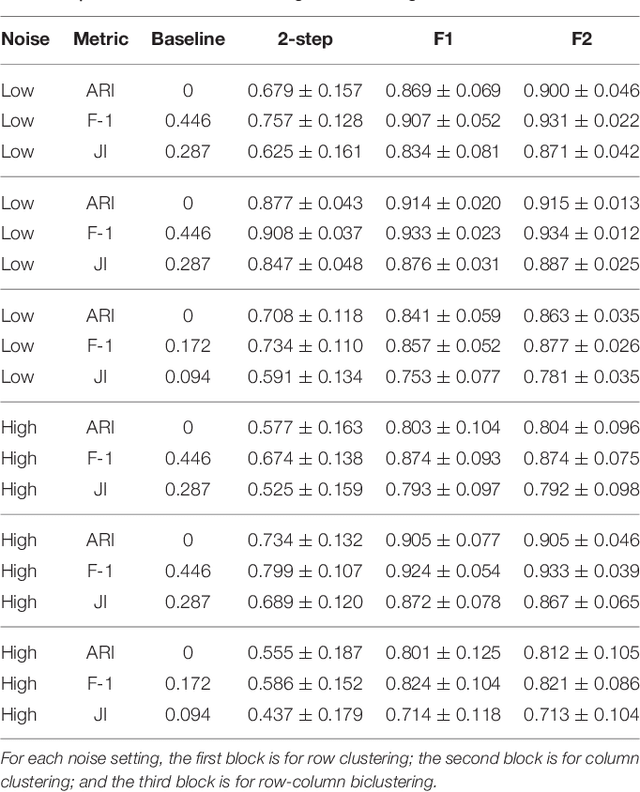

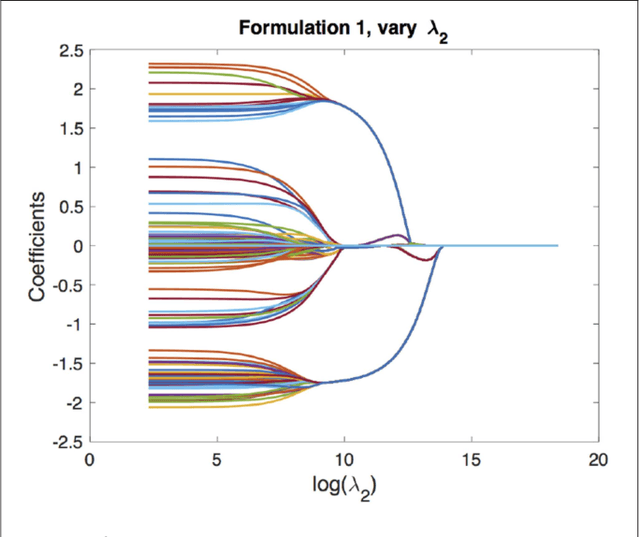
We consider multi-response and multitask regression models, where the parameter matrix to be estimated is expected to have an unknown grouping structure. The groupings can be along tasks, or features, or both, the last one indicating a bi-cluster or "checkerboard" structure. Discovering this grouping structure along with parameter inference makes sense in several applications, such as multi-response Genome-Wide Association Studies. This additional structure can not only can be leveraged for more accurate parameter estimation, but it also provides valuable information on the underlying data mechanisms (e.g. relationships among genotypes and phenotypes in GWAS). In this paper, we propose two formulations to simultaneously learn the parameter matrix and its group structures, based on convex regularization penalties. We present optimization approaches to solve the resulting problems and provide numerical convergence guarantees. Our approaches are validated on extensive simulations and real datasets concerning phenotypes and genotypes of plant varieties.
Understanding Innovation to Drive Sustainable Development
Jun 15, 2016


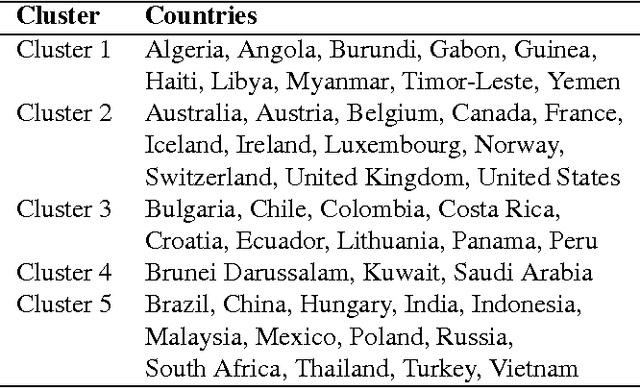
Innovation is among the key factors driving a country's economic and social growth. But what are the factors that make a country innovative? How do they differ across different parts of the world and different stages of development? In this work done in collaboration with the World Economic Forum (WEF), we analyze the scores obtained through executive opinion surveys that constitute the WEF's Global Competitiveness Index in conjunction with other country-level metrics and indicators to identify actionable levers of innovation. The findings can help country leaders and organizations shape the policies to drive developmental activities and increase the capacity of innovation.