 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlzhiNet: Traversing from 2DCNN to 3DCNN, Towards Early Detection and Diagnosis of Alzheimer's Disease
Oct 03, 2024Alzheimer's disease (AD) is a progressive neurodegenerative disorder with increasing prevalence among the aging population, necessitating early and accurate diagnosis for effective disease management. In this study, we present a novel hybrid deep learning framework that integrates both 2D Convolutional Neural Networks (2D-CNN) and 3D Convolutional Neural Networks (3D-CNN), along with a custom loss function and volumetric data augmentation, to enhance feature extraction and improve classification performance in AD diagnosis. According to extensive experiments, AlzhiNet outperforms standalone 2D and 3D models, highlighting the importance of combining these complementary representations of data. The depth and quality of 3D volumes derived from the augmented 2D slices also significantly influence the model's performance. The results indicate that carefully selecting weighting factors in hybrid predictions is imperative for achieving optimal results. Our framework has been validated on the Magnetic Resonance Imaging (MRI) from Kaggle and MIRIAD datasets, obtaining accuracies of 98.9% and 99.99%, respectively, with an AUC of 100%. Furthermore, AlzhiNet was studied under a variety of perturbation scenarios on the Alzheimer's Kaggle dataset, including Gaussian noise, brightness, contrast, salt and pepper noise, color jitter, and occlusion. The results obtained show that AlzhiNet is more robust to perturbations than ResNet-18, making it an excellent choice for real-world applications. This approach represents a promising advancement in the early diagnosis and treatment planning for Alzheimer's disease.
Information Prebuilt Recurrent Reconstruction Network for Video Super-Resolution
Dec 10, 2021

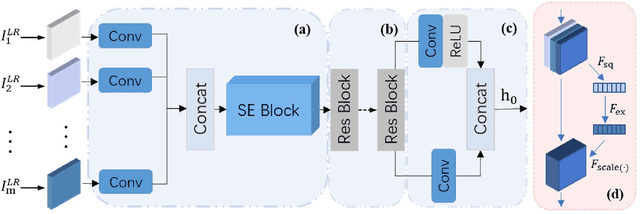
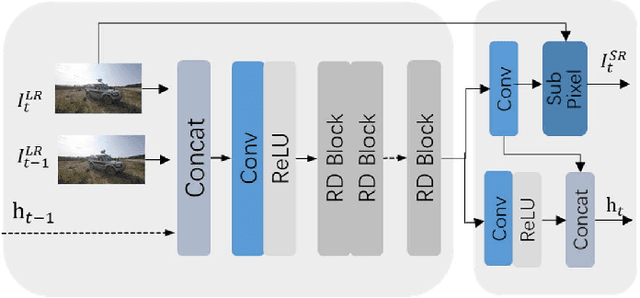
The video super-resolution (VSR) method based on the recurrent convolutional network has strong temporal modeling capability for video sequences. However, the input information received by different recurrent units in the unidirectional recurrent convolutional network is unbalanced. Early reconstruction frames receive less temporal information, resulting in fuzzy or artifact results. Although the bidirectional recurrent convolution network can alleviate this problem, it greatly increases reconstruction time and computational complexity. It is also not suitable for many application scenarios, such as online super-resolution. To solve the above problems, we propose an end-to-end information prebuilt recurrent reconstruction network (IPRRN), consisting of an information prebuilt network (IPNet) and a recurrent reconstruction network (RRNet). By integrating sufficient information from the front of the video to build the hidden state needed for the initially recurrent unit to help restore the earlier frames, the information prebuilt network balances the input information difference before and after without backward propagation. In addition, we demonstrate a compact recurrent reconstruction network, which has significant improvements in recovery quality and time efficiency. Many experiments have verified the effectiveness of our proposed network, and compared with the existing state-of-the-art methods, our method can effectively achieve higher quantitative and qualitative evaluation performance.
Convergent Policy Optimization for Safe Reinforcement Learning
Oct 26, 2019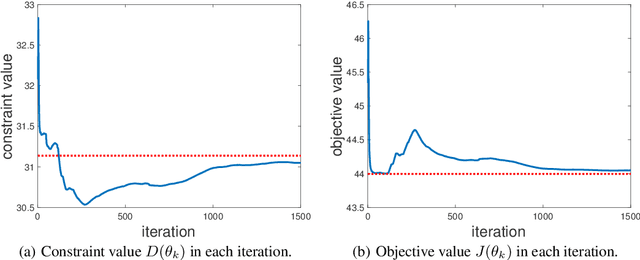

We study the safe reinforcement learning problem with nonlinear function approximation, where policy optimization is formulated as a constrained optimization problem with both the objective and the constraint being nonconvex functions. For such a problem, we construct a sequence of surrogate convex constrained optimization problems by replacing the nonconvex functions locally with convex quadratic functions obtained from policy gradient estimators. We prove that the solutions to these surrogate problems converge to a stationary point of the original nonconvex problem. Furthermore, to extend our theoretical results, we apply our algorithm to examples of optimal control and multi-agent reinforcement learning with safety constraints.
An Improved Deep Belief Network Model for Road Safety Analyses
Dec 17, 2018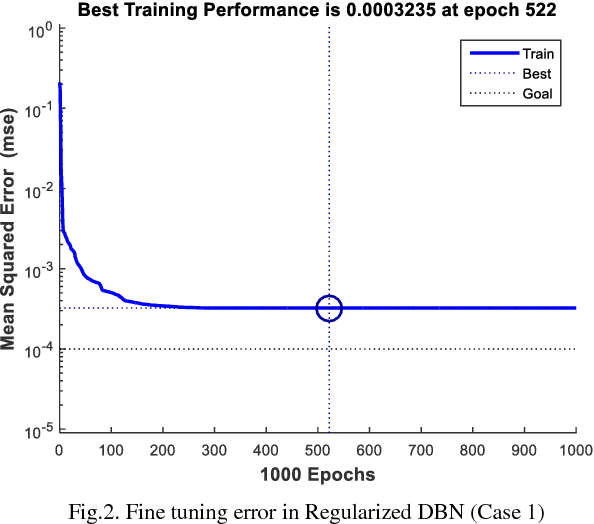


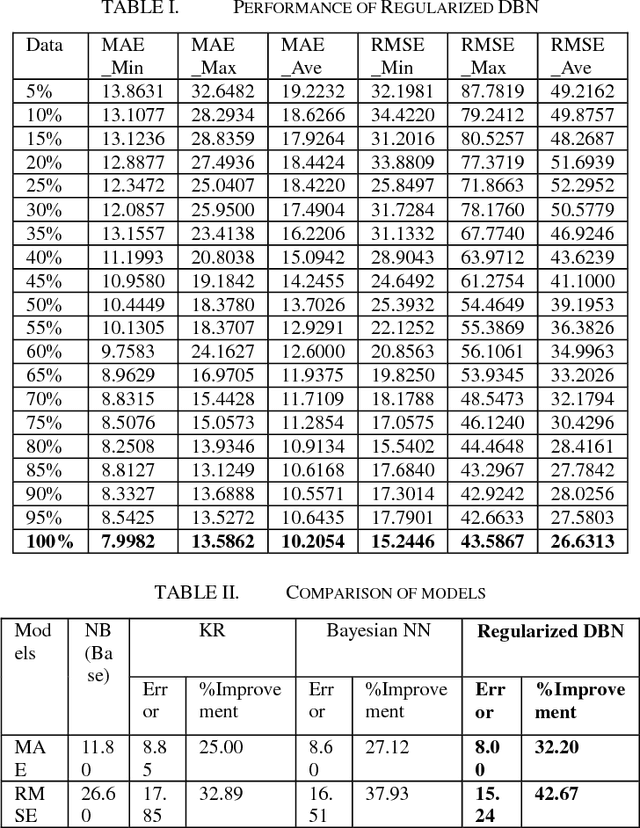
Crash prediction is a critical component of road safety analyses. A widely adopted approach to crash prediction is application of regression based techniques. The underlying calibration process is often time-consuming, requiring significant domain knowledge and expertise and cannot be easily automated. This paper introduces a new machine learning (ML) based approach as an alternative to the traditional techniques. The proposed ML model is called regularized deep belief network, which is a deep neural network with two training steps: it is first trained using an unsupervised learning algorithm and then fine-tuned by initializing a Bayesian neural network with the trained weights from the first step. The resulting model is expected to have improved prediction power and reduced need for the time-consuming human intervention. In this paper, we attempt to demonstrate the potential of this new model for crash prediction through two case studies including a collision data set from 800 km stretch of Highway 401 and other highways in Ontario, Canada. Our intention is to show the performance of this ML approach in comparison to various traditional models including negative binomial (NB) model, kernel regression (KR), and Bayesian neural network (Bayesian NN). We also attempt to address other related issues such as effect of training data size and training parameters.
Provable Gaussian Embedding with One Observation
Oct 25, 2018
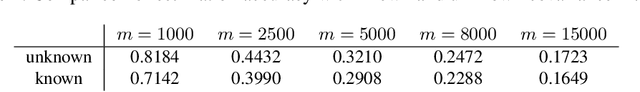
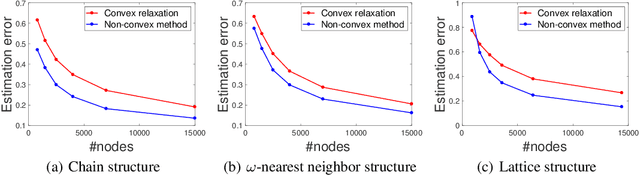
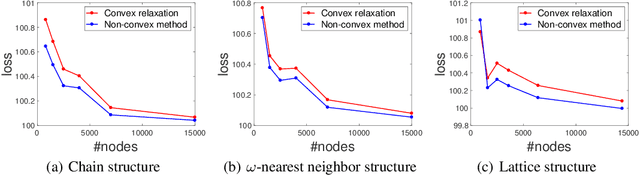
The success of machine learning methods heavily relies on having an appropriate representation for data at hand. Traditionally, machine learning approaches relied on user-defined heuristics to extract features encoding structural information about data. However, recently there has been a surge in approaches that learn how to encode the data automatically in a low dimensional space. Exponential family embedding provides a probabilistic framework for learning low-dimensional representation for various types of high-dimensional data. Though successful in practice, theoretical underpinnings for exponential family embeddings have not been established. In this paper, we study the Gaussian embedding model and develop the first theoretical results for exponential family embedding models. First, we show that, under mild condition, the embedding structure can be learned from one observation by leveraging the parameter sharing between different contexts even though the data are dependent with each other. Second, we study properties of two algorithms used for learning the embedding structure and establish convergence results for each of them. The first algorithm is based on a convex relaxation, while the other solved the non-convex formulation of the problem directly. Experiments demonstrate the effectiveness of our approach.
Learning Influence-Receptivity Network Structure with Guarantee
Jun 14, 2018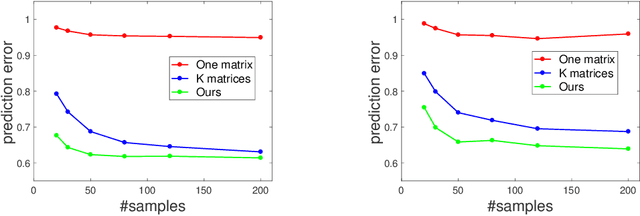


Traditional works on community detection from observations of information cascade assume that a single adjacency matrix parametrizes all the observed cascades. However, in reality the connection structure usually does not stay the same across cascades. For example, different people have different topics of interest, therefore the connection structure would depend on the information/topic content of the cascade. In this paper we consider the case where we observe a sequence of noisy adjacency matrices triggered by information/events with different topic distributions. We propose a novel latent model using the intuition that the connection is more likely to exist between two nodes if they are interested in similar topics, which are common with the information/event. Specifically, we endow each node two node-topic vectors: an influence vector that measures how much influential/authoritative they are on each topic; and a receptivity vector that measures how much receptive/susceptible they are to each topic. We show how these two node-topic structures can be estimated from observed adjacency matrices with theoretical guarantee, in cases where the topic distributions of the information/events are known, as well as when they are unknown. Extensive experiments on synthetic and real data demonstrate the effectiveness of our model.
Simultaneous Parameter Learning and Bi-Clustering for Multi-Response Models
Apr 29, 2018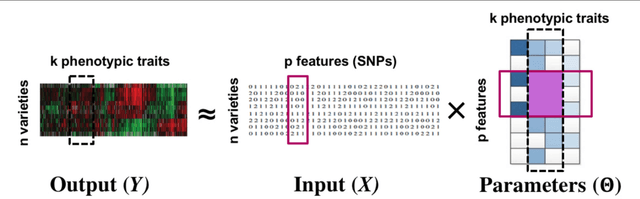
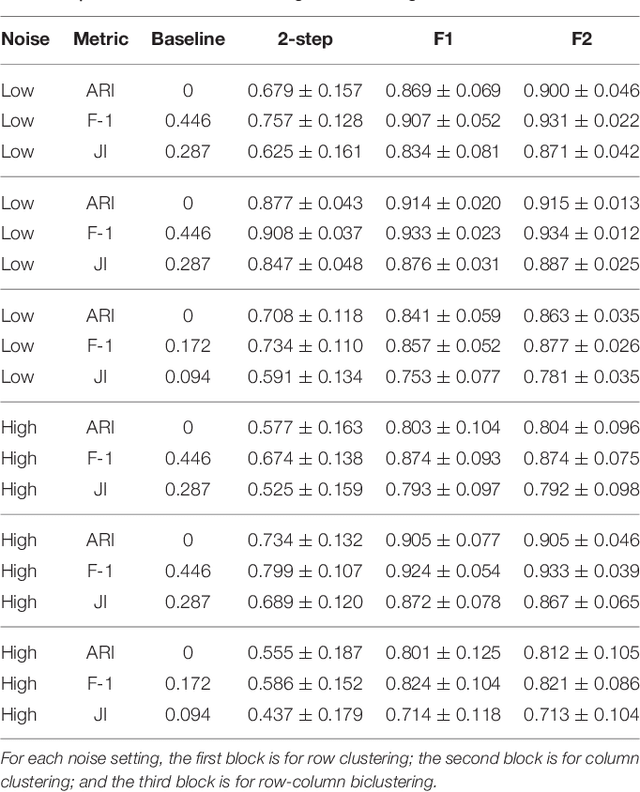

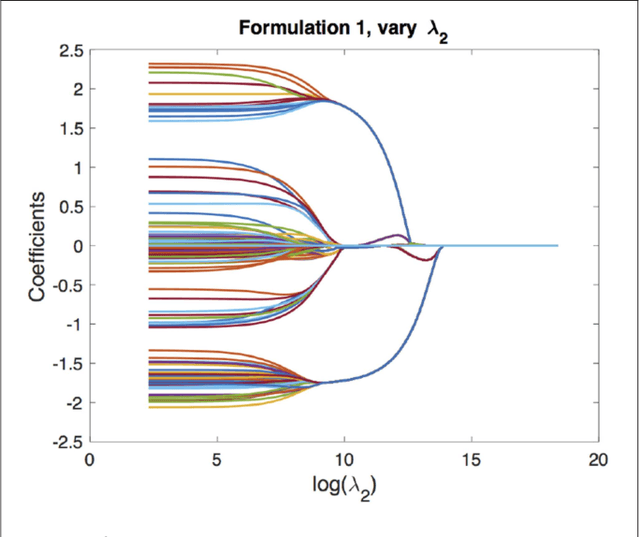
We consider multi-response and multitask regression models, where the parameter matrix to be estimated is expected to have an unknown grouping structure. The groupings can be along tasks, or features, or both, the last one indicating a bi-cluster or "checkerboard" structure. Discovering this grouping structure along with parameter inference makes sense in several applications, such as multi-response Genome-Wide Association Studies. This additional structure can not only can be leveraged for more accurate parameter estimation, but it also provides valuable information on the underlying data mechanisms (e.g. relationships among genotypes and phenotypes in GWAS). In this paper, we propose two formulations to simultaneously learn the parameter matrix and its group structures, based on convex regularization penalties. We present optimization approaches to solve the resulting problems and provide numerical convergence guarantees. Our approaches are validated on extensive simulations and real datasets concerning phenotypes and genotypes of plant varieties.
Recovery of simultaneous low rank and two-way sparse coefficient matrices, a nonconvex approach
Feb 20, 2018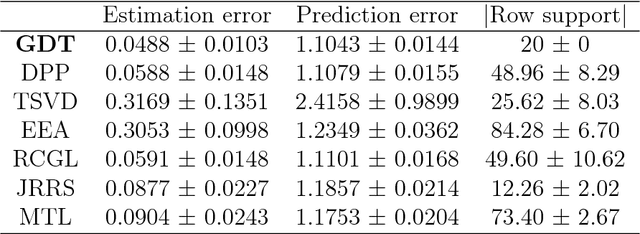
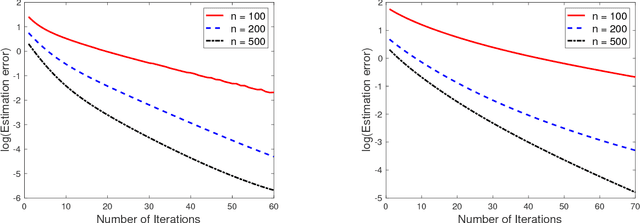
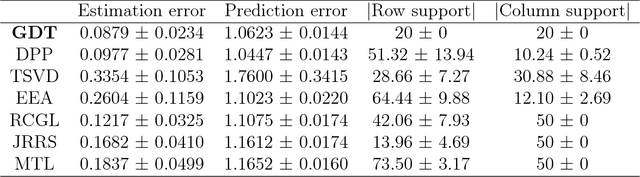
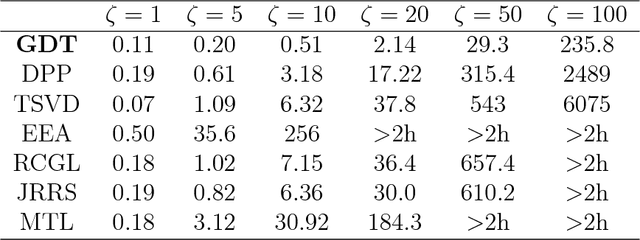
We study the problem of recovery of matrices that are simultaneously low rank and row and/or column sparse. Such matrices appear in recent applications in cognitive neuroscience, imaging, computer vision, macroeconomics, and genetics. We propose a GDT (Gradient Descent with hard Thresholding) algorithm to efficiently recover matrices with such structure, by minimizing a bi-convex function over a nonconvex set of constraints. We show linear convergence of the iterates obtained by GDT to a region within statistical error of an optimal solution. As an application of our method, we consider multi-task learning problems and show that the statistical error rate obtained by GDT is near optimal compared to minimax rate. Experiments demonstrate competitive performance and much faster running speed compared to existing methods, on both simulations and real data sets.
Multitask Learning using Task Clustering with Applications to Predictive Modeling and GWAS of Plant Varieties
Oct 04, 2017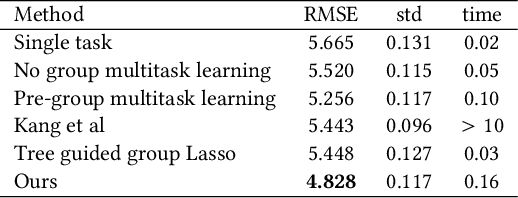
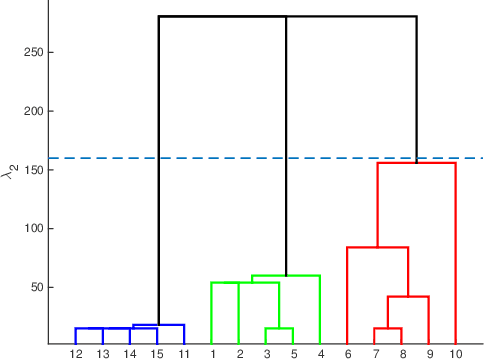
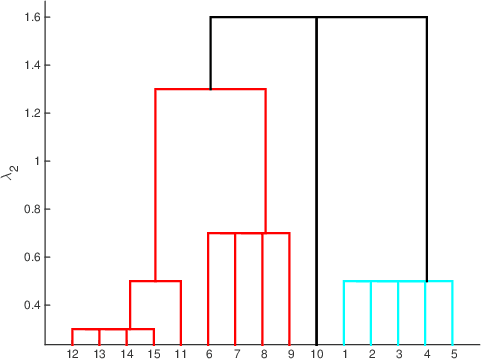
Inferring predictive maps between multiple input and multiple output variables or tasks has innumerable applications in data science. Multi-task learning attempts to learn the maps to several output tasks simultaneously with information sharing between them. We propose a novel multi-task learning framework for sparse linear regression, where a full task hierarchy is automatically inferred from the data, with the assumption that the task parameters follow a hierarchical tree structure. The leaves of the tree are the parameters for individual tasks, and the root is the global model that approximates all the tasks. We apply the proposed approach to develop and evaluate: (a) predictive models of plant traits using large-scale and automated remote sensing data, and (b) GWAS methodologies mapping such derived phenotypes in lieu of hand-measured traits. We demonstrate the superior performance of our approach compared to other methods, as well as the usefulness of discovering hierarchical groupings between tasks. Our results suggest that richer genetic mapping can indeed be obtained from the remote sensing data. In addition, our discovered groupings reveal interesting insights from a plant science perspective.
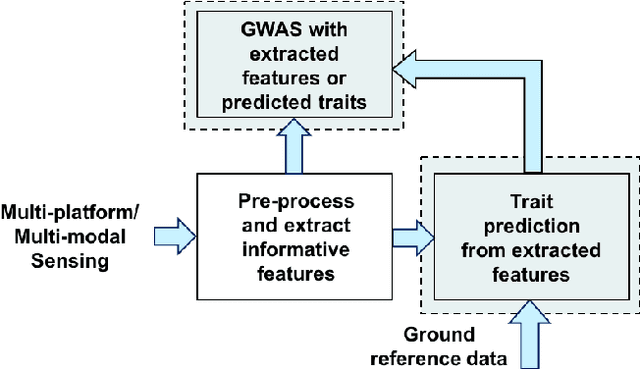
An Influence-Receptivity Model for Topic based Information Cascades
Sep 06, 2017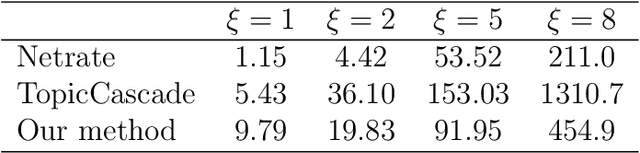
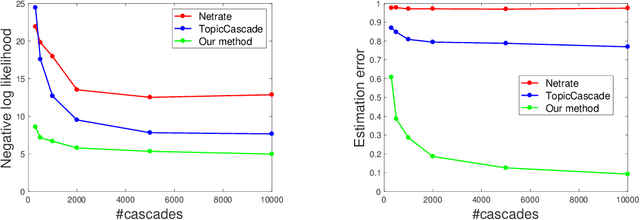

We consider the problem of estimating the latent structure of a social network based on observational data on information diffusion processes, or {\it cascades}. Here for a given cascade, we only observe the time a node/agent is infected but not the source of infection. Existing literature has focused on estimating network diffusion matrix without any underlying assumptions on the structure of the network. We propose a novel model for inferring network diffusion matrix based on the intuition that an information datum is more likely to propagate among two nodes if they are interested in similar topics, which are common with the information. In particular, our model endows each node with an influence vector (how authoritative they are on each topic) and a receptivity vector (how susceptible they are on each topic). We show how this node-topic structure can be estimated from observed cascades. The estimated model can be used to build recommendation system based on the receptivity vectors, as well as for marketing based on the influence vectors.