 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaying Less Generalization Tax: A Cross-Domain Generalization Study of RL Training for LLM Agents
Jan 26, 2026Generalist LLM agents are often post-trained on a narrow set of environments but deployed across far broader, unseen domains. In this work, we investigate the challenge of agentic post-training when the eventual test domains are unknown. Specifically, we analyze which properties of reinforcement learning (RL) environments and modeling choices have the greatest influence on out-of-domain performance. First, we identify two environment axes that strongly correlate with cross-domain generalization: (i) state information richness, i.e., the amount of information for the agent to process from the state, and (ii) planning complexity, estimated via goal reachability and trajectory length under a base policy. Notably, domain realism and text-level similarity are not the primary factors; for instance, the simple grid-world domain Sokoban leads to even stronger generalization in SciWorld than the more realistic ALFWorld. Motivated by these findings, we further show that increasing state information richness alone can already effectively improve cross-domain robustness. We propose a randomization technique, which is low-overhead and broadly applicable: add small amounts of distractive goal-irrelevant features to the state to make it richer without altering the task. Beyond environment-side properties, we also examine several modeling choices: (a) SFT warmup or mid-training helps prevent catastrophic forgetting during RL but undermines generalization to domains that are not included in the mid-training datamix; and (b) turning on step-by-step thinking during RL, while not always improving in-domain performance, plays a crucial role in preserving generalization.
Local Linear Attention: An Optimal Interpolation of Linear and Softmax Attention For Test-Time Regression
Oct 01, 2025Transformer architectures have achieved remarkable success in various domains. While efficient alternatives to Softmax Attention have been widely studied, the search for more expressive mechanisms grounded in theoretical insight-even at greater computational cost-has been relatively underexplored. In this work, we bridge this gap by proposing Local Linear Attention (LLA), a novel attention mechanism derived from nonparametric statistics through the lens of test-time regression. First, we show that LLA offers theoretical advantages over Linear and Softmax Attention for associative memory via a bias-variance trade-off analysis. Next, we address its computational challenges and propose two memory-efficient primitives to tackle the $\Theta(n^2 d)$ and $\Theta(n d^2)$ complexity. We then introduce FlashLLA, a hardware-efficient, blockwise algorithm that enables scalable and parallel computation on modern accelerators. In addition, we implement and profile a customized inference kernel that significantly reduces memory overheads. Finally, we empirically validate the advantages and limitations of LLA on test-time regression, in-context regression, associative recall and state tracking tasks. Experiment results demonstrate that LLA effectively adapts to non-stationarity, outperforming strong baselines in test-time training and in-context learning, and exhibiting promising evidence for its scalability and applicability in large-scale models. Code is available at https://github.com/Yifei-Zuo/Flash-LLA.
The Sample Complexity of Online Strategic Decision Making with Information Asymmetry and Knowledge Transportability
Jun 11, 2025Information asymmetry is a pervasive feature of multi-agent systems, especially evident in economics and social sciences. In these settings, agents tailor their actions based on private information to maximize their rewards. These strategic behaviors often introduce complexities due to confounding variables. Simultaneously, knowledge transportability poses another significant challenge, arising from the difficulties of conducting experiments in target environments. It requires transferring knowledge from environments where empirical data is more readily available. Against these backdrops, this paper explores a fundamental question in online learning: Can we employ non-i.i.d. actions to learn about confounders even when requiring knowledge transfer? We present a sample-efficient algorithm designed to accurately identify system dynamics under information asymmetry and to navigate the challenges of knowledge transfer effectively in reinforcement learning, framed within an online strategic interaction model. Our method provably achieves learning of an $\epsilon$-optimal policy with a tight sample complexity of $O(1/\epsilon^2)$.
Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning
May 26, 2025Large Language Models (LLMs) trained via Reinforcement Learning (RL) have exhibited strong reasoning capabilities and emergent reflective behaviors, such as backtracking and error correction. However, conventional Markovian RL confines exploration to the training phase to learn an optimal deterministic policy and depends on the history contexts only through the current state. Therefore, it remains unclear whether reflective reasoning will emerge during Markovian RL training, or why they are beneficial at test time. To remedy this, we recast reflective exploration within the Bayes-Adaptive RL framework, which explicitly optimizes the expected return under a posterior distribution over Markov decision processes. This Bayesian formulation inherently incentivizes both reward-maximizing exploitation and information-gathering exploration via belief updates. Our resulting algorithm, BARL, instructs the LLM to stitch and switch strategies based on the observed outcomes, offering principled guidance on when and how the model should reflectively explore. Empirical results on both synthetic and mathematical reasoning tasks demonstrate that BARL outperforms standard Markovian RL approaches at test time, achieving superior token efficiency with improved exploration effectiveness. Our code is available at https://github.com/shenao-zhang/BARL.
BRiTE: Bootstrapping Reinforced Thinking Process to Enhance Language Model Reasoning
Jan 31, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, yet generating reliable reasoning processes remains a significant challenge. We present a unified probabilistic framework that formalizes LLM reasoning through a novel graphical model incorporating latent thinking processes and evaluation signals. Within this framework, we introduce the Bootstrapping Reinforced Thinking Process (BRiTE) algorithm, which works in two steps. First, it generates high-quality rationales by approximating the optimal thinking process through reinforcement learning, using a novel reward shaping mechanism. Second, it enhances the base LLM by maximizing the joint probability of rationale generation with respect to the model's parameters. Theoretically, we demonstrate BRiTE's convergence at a rate of $1/T$ with $T$ representing the number of iterations. Empirical evaluations on math and coding benchmarks demonstrate that our approach consistently improves performance across different base models without requiring human-annotated thinking processes. In addition, BRiTE demonstrates superior performance compared to existing algorithms that bootstrap thinking processes use alternative methods such as rejection sampling, and can even match or exceed the results achieved through supervised fine-tuning with human-annotated data.
Are Transformers Able to Reason by Connecting Separated Knowledge in Training Data?
Jan 27, 2025Humans exhibit remarkable compositional reasoning by integrating knowledge from various sources. For example, if someone learns ( B = f(A) ) from one source and ( C = g(B) ) from another, they can deduce ( C=g(B)=g(f(A)) ) even without encountering ( ABC ) together, showcasing the generalization ability of human intelligence. In this paper, we introduce a synthetic learning task, "FTCT" (Fragmented at Training, Chained at Testing), to validate the potential of Transformers in replicating this skill and interpret its inner mechanism. In the training phase, data consist of separated knowledge fragments from an overall causal graph. During testing, Transformers must infer complete causal graph traces by integrating these fragments. Our findings demonstrate that few-shot Chain-of-Thought prompting enables Transformers to perform compositional reasoning on FTCT by revealing correct combinations of fragments, even if such combinations were absent in the training data. Furthermore, the emergence of compositional reasoning ability is strongly correlated with the model complexity and training-testing data similarity. We propose, both theoretically and empirically, that Transformers learn an underlying generalizable program from training, enabling effective compositional reasoning during testing.
Hindsight Planner: A Closed-Loop Few-Shot Planner for Embodied Instruction Following
Dec 27, 2024



This work focuses on building a task planner for Embodied Instruction Following (EIF) using Large Language Models (LLMs). Previous works typically train a planner to imitate expert trajectories, treating this as a supervised task. While these methods achieve competitive performance, they often lack sufficient robustness. When a suboptimal action is taken, the planner may encounter an out-of-distribution state, which can lead to task failure. In contrast, we frame the task as a Partially Observable Markov Decision Process (POMDP) and aim to develop a robust planner under a few-shot assumption. Thus, we propose a closed-loop planner with an adaptation module and a novel hindsight method, aiming to use as much information as possible to assist the planner. Our experiments on the ALFRED dataset indicate that our planner achieves competitive performance under a few-shot assumption. For the first time, our few-shot agent's performance approaches and even surpasses that of the full-shot supervised agent.
An Instrumental Value for Data Production and its Application to Data Pricing
Dec 24, 2024How much value does a dataset or a data production process have to an agent who wishes to use the data to assist decision-making? This is a fundamental question towards understanding the value of data as well as further pricing of data. This paper develops an approach for capturing the instrumental value of data production processes, which takes two key factors into account: (a) the context of the agent's decision-making problem; (b) prior data or information the agent already possesses. We ''micro-found'' our valuation concepts by showing how they connect to classic notions of information design and signals in information economics. When instantiated in the domain of Bayesian linear regression, our value naturally corresponds to information gain. Based on our designed data value, we then study a basic monopoly pricing setting with a buyer looking to purchase from a seller some labeled data of a certain feature direction in order to improve a Bayesian regression model. We show that when the seller has the ability to fully customize any data request, she can extract the first-best revenue (i.e., full surplus) from any population of buyers, i.e., achieving first-degree price discrimination. If the seller can only sell data that are derived from an existing data pool, this limits her ability to customize, and achieving first-best revenue becomes generally impossible. However, we design a mechanism that achieves seller revenue at most $\log (\kappa)$ less than the first-best revenue, where $\kappa$ is the condition number associated with the data matrix. A corollary of this result is that the seller can extract the first-best revenue in the multi-armed bandits special case.
DSTC: Direct Preference Learning with Only Self-Generated Tests and Code to Improve Code LMs
Nov 20, 2024



Direct preference learning offers a promising and computation-efficient beyond supervised fine-tuning (SFT) for improving code generation in coding large language models (LMs). However, the scarcity of reliable preference data is a bottleneck for the performance of direct preference learning to improve the coding accuracy of code LMs. In this paper, we introduce \underline{\textbf{D}}irect Preference Learning with Only \underline{\textbf{S}}elf-Generated \underline{\textbf{T}}ests and \underline{\textbf{C}}ode (DSTC), a framework that leverages only self-generated code snippets and tests to construct reliable preference pairs such that direct preference learning can improve LM coding accuracy without external annotations. DSTC combines a minimax selection process and test-code concatenation to improve preference pair quality, reducing the influence of incorrect self-generated tests and enhancing model performance without the need for costly reward models. When applied with direct preference learning methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO), DSTC yields stable improvements in coding accuracy (pass@1 score) across diverse coding benchmarks, including HumanEval, MBPP, and BigCodeBench, demonstrating both its effectiveness and scalability for models of various sizes. This approach autonomously enhances code generation accuracy across LLMs of varying sizes, reducing reliance on expensive annotated coding datasets.
Language-Model-Assisted Bi-Level Programming for Reward Learning from Internet Videos
Oct 11, 2024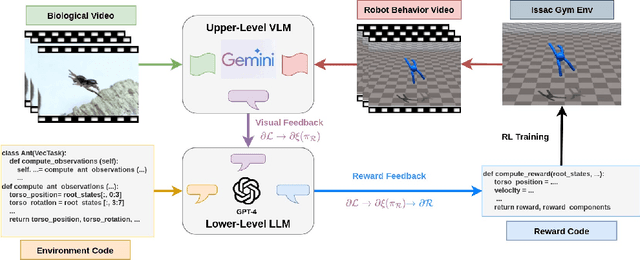



Learning from Demonstrations, particularly from biological experts like humans and animals, often encounters significant data acquisition challenges. While recent approaches leverage internet videos for learning, they require complex, task-specific pipelines to extract and retarget motion data for the agent. In this work, we introduce a language-model-assisted bi-level programming framework that enables a reinforcement learning agent to directly learn its reward from internet videos, bypassing dedicated data preparation. The framework includes two levels: an upper level where a vision-language model (VLM) provides feedback by comparing the learner's behavior with expert videos, and a lower level where a large language model (LLM) translates this feedback into reward updates. The VLM and LLM collaborate within this bi-level framework, using a "chain rule" approach to derive a valid search direction for reward learning. We validate the method for reward learning from YouTube videos, and the results have shown that the proposed method enables efficient reward design from expert videos of biological agents for complex behavior synthesis.