 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Model-Assisted Bi-Level Programming for Reward Learning from Internet Videos
Paper and Code
Oct 11, 2024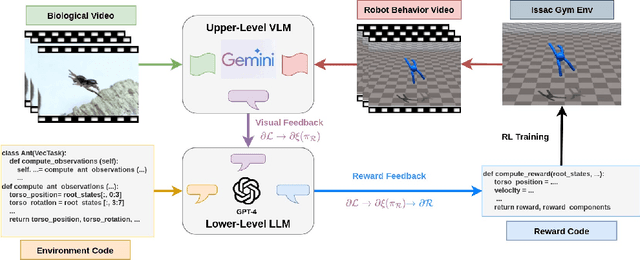



Learning from Demonstrations, particularly from biological experts like humans and animals, often encounters significant data acquisition challenges. While recent approaches leverage internet videos for learning, they require complex, task-specific pipelines to extract and retarget motion data for the agent. In this work, we introduce a language-model-assisted bi-level programming framework that enables a reinforcement learning agent to directly learn its reward from internet videos, bypassing dedicated data preparation. The framework includes two levels: an upper level where a vision-language model (VLM) provides feedback by comparing the learner's behavior with expert videos, and a lower level where a large language model (LLM) translates this feedback into reward updates. The VLM and LLM collaborate within this bi-level framework, using a "chain rule" approach to derive a valid search direction for reward learning. We validate the method for reward learning from YouTube videos, and the results have shown that the proposed method enables efficient reward design from expert videos of biological agents for complex behavior synthesis.