 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoDiF: Robust Direct Fine-Tuning of Diffusion Policies with Corrupted Human Feedback
Jan 31, 2026Diffusion policies are a powerful paradigm for robotic control, but fine-tuning them with human preferences is fundamentally challenged by the multi-step structure of the denoising process. To overcome this, we introduce a Unified Markov Decision Process (MDP) formulation that coherently integrates the diffusion denoising chain with environmental dynamics, enabling reward-free Direct Preference Optimization (DPO) for diffusion policies. Building on this formulation, we propose RoDiF (Robust Direct Fine-Tuning), a method that explicitly addresses corrupted human preferences. RoDiF reinterprets the DPO objective through a geometric hypothesis-cutting perspective and employs a conservative cutting strategy to achieve robustness without assuming any specific noise distribution. Extensive experiments on long-horizon manipulation tasks show that RoDiF consistently outperforms state-of-the-art baselines, effectively steering pretrained diffusion policies of diverse architectures to human-preferred modes, while maintaining strong performance even under 30% corrupted preference labels.
Where to Touch, How to Contact: Hierarchical RL-MPC Framework for Geometry-Aware Long-Horizon Dexterous Manipulation
Jan 16, 2026A key challenge in contact-rich dexterous manipulation is the need to jointly reason over geometry, kinematic constraints, and intricate, nonsmooth contact dynamics. End-to-end visuomotor policies bypass this structure, but often require large amounts of data, transfer poorly from simulation to reality, and generalize weakly across tasks/embodiments. We address those limitations by leveraging a simple insight: dexterous manipulation is inherently hierarchical - at a high level, a robot decides where to touch (geometry) and move the object (kinematics); at a low level it determines how to realize that plan through contact dynamics. Building on this insight, we propose a hierarchical RL--MPC framework in which a high-level reinforcement learning (RL) policy predicts a contact intention, a novel object-centric interface that specifies (i) an object-surface contact location and (ii) a post-contact object-level subgoal pose. Conditioned on this contact intention, a low-level contact-implicit model predictive control (MPC) optimizes local contact modes and replans with contact dynamics to generate robot actions that robustly drive the object toward each subgoal. We evaluate the framework on non-prehensile tasks, including geometry-generalized pushing and object 3D reorientation. It achieves near-100% success with substantially reduced data (10x less than end-to-end baselines), highly robust performance, and zero-shot sim-to-real transfer.
ZORMS-LfD: Learning from Demonstrations with Zeroth-Order Random Matrix Search
Jul 23, 2025We propose Zeroth-Order Random Matrix Search for Learning from Demonstrations (ZORMS-LfD). ZORMS-LfD enables the costs, constraints, and dynamics of constrained optimal control problems, in both continuous and discrete time, to be learned from expert demonstrations without requiring smoothness of the learning-loss landscape. In contrast, existing state-of-the-art first-order methods require the existence and computation of gradients of the costs, constraints, dynamics, and learning loss with respect to states, controls and/or parameters. Most existing methods are also tailored to discrete time, with constrained problems in continuous time receiving only cursory attention. We demonstrate that ZORMS-LfD matches or surpasses the performance of state-of-the-art methods in terms of both learning loss and compute time across a variety of benchmark problems. On unconstrained continuous-time benchmark problems, ZORMS-LfD achieves similar loss performance to state-of-the-art first-order methods with an over $80$\% reduction in compute time. On constrained continuous-time benchmark problems where there is no specialized state-of-the-art method, ZORMS-LfD is shown to outperform the commonly used gradient-free Nelder-Mead optimization method.
TwinTrack: Bridging Vision and Contact Physics for Real-Time Tracking of Unknown Dynamic Objects
May 28, 2025
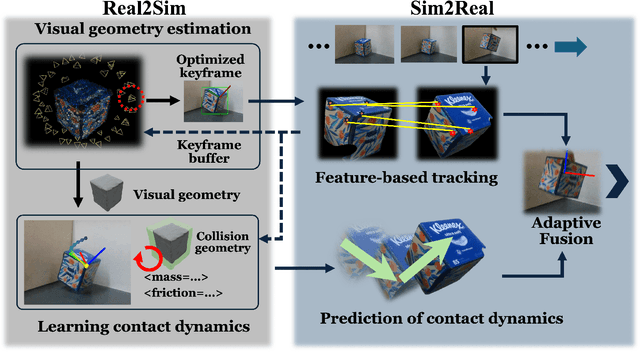
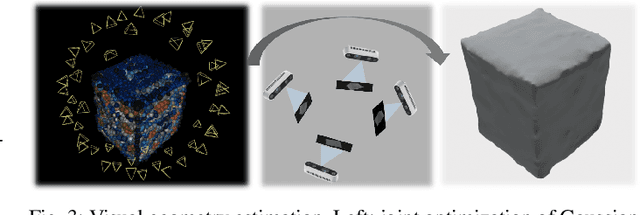
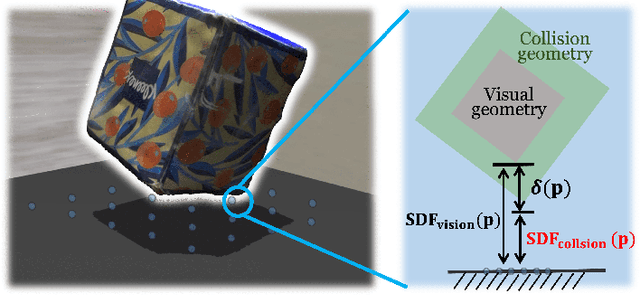
Real-time tracking of previously unseen, highly dynamic objects in contact-rich environments -- such as during dexterous in-hand manipulation -- remains a significant challenge. Purely vision-based tracking often suffers from heavy occlusions due to the frequent contact interactions and motion blur caused by abrupt motion during contact impacts. We propose TwinTrack, a physics-aware visual tracking framework that enables robust and real-time 6-DoF pose tracking of unknown dynamic objects in a contact-rich scene by leveraging the contact physics of the observed scene. At the core of TwinTrack is an integration of Real2Sim and Sim2Real. In Real2Sim, we combine the complementary strengths of vision and contact physics to estimate object's collision geometry and physical properties: object's geometry is first reconstructed from vision, then updated along with other physical parameters from contact dynamics for physical accuracy. In Sim2Real, robust pose estimation of the object is achieved by adaptive fusion between visual tracking and prediction of the learned contact physics. TwinTrack is built on a GPU-accelerated, deeply customized physics engine to ensure real-time performance. We evaluate our method on two contact-rich scenarios: object falling with rich contact impacts against the environment, and contact-rich in-hand manipulation. Experimental results demonstrate that, compared to baseline methods, TwinTrack achieves significantly more robust, accurate, and real-time 6-DoF tracking in these challenging scenarios, with tracking speed exceeding 20 Hz. Project page: https://irislab.tech/TwinTrack-webpage/
Robust Reward Alignment via Hypothesis Space Batch Cutting
Feb 06, 2025



Reward design for reinforcement learning and optimal control agents is challenging. Preference-based alignment addresses this by enabling agents to learn rewards from ranked trajectory pairs provided by humans. However, existing methods often struggle from poor robustness to unknown false human preferences. In this work, we propose a robust and efficient reward alignment method based on a novel and geometrically interpretable perspective: hypothesis space batched cutting. Our method iteratively refines the reward hypothesis space through "cuts" based on batches of human preferences. Within each batch, human preferences, queried based on disagreement, are grouped using a voting function to determine the appropriate cut, ensuring a bounded human query complexity. To handle unknown erroneous preferences, we introduce a conservative cutting method within each batch, preventing erroneous human preferences from making overly aggressive cuts to the hypothesis space. This guarantees provable robustness against false preferences. We evaluate our method in a model predictive control setting across diverse tasks, including DM-Control, dexterous in-hand manipulation, and locomotion. The results demonstrate that our framework achieves comparable or superior performance to state-of-the-art methods in error-free settings while significantly outperforming existing method when handling high percentage of erroneous human preferences.
Whole-Body Impedance Coordinative Control of Wheel-Legged Robot on Uncertain Terrain
Nov 15, 2024



This article propose a whole-body impedance coordinative control framework for a wheel-legged humanoid robot to achieve adaptability on complex terrains while maintaining robot upper body stability. The framework contains a bi-level control strategy. The outer level is a variable damping impedance controller, which optimizes the damping parameters to ensure the stability of the upper body while holding an object. The inner level employs Whole-Body Control (WBC) optimization that integrates real-time terrain estimation based on wheel-foot position and force data. It generates motor torques while accounting for dynamic constraints, joint limits,friction cones, real-time terrain updates, and a model-free friction compensation strategy. The proposed whole-body coordinative control method has been tested on a recently developed quadruped humanoid robot. The results demonstrate that the proposed algorithm effectively controls the robot, maintaining upper body stability to successfully complete a water-carrying task while adapting to varying terrains.
Language-Model-Assisted Bi-Level Programming for Reward Learning from Internet Videos
Oct 11, 2024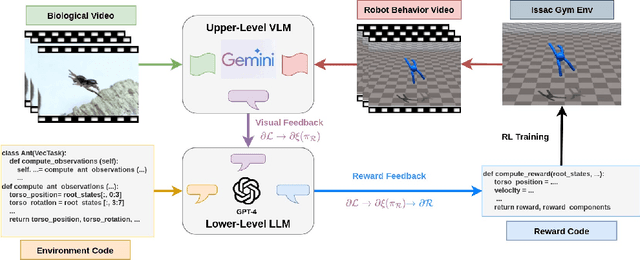



Learning from Demonstrations, particularly from biological experts like humans and animals, often encounters significant data acquisition challenges. While recent approaches leverage internet videos for learning, they require complex, task-specific pipelines to extract and retarget motion data for the agent. In this work, we introduce a language-model-assisted bi-level programming framework that enables a reinforcement learning agent to directly learn its reward from internet videos, bypassing dedicated data preparation. The framework includes two levels: an upper level where a vision-language model (VLM) provides feedback by comparing the learner's behavior with expert videos, and a lower level where a large language model (LLM) translates this feedback into reward updates. The VLM and LLM collaborate within this bi-level framework, using a "chain rule" approach to derive a valid search direction for reward learning. We validate the method for reward learning from YouTube videos, and the results have shown that the proposed method enables efficient reward design from expert videos of biological agents for complex behavior synthesis.
ContactSDF: Signed Distance Functions as Multi-Contact Models for Dexterous Manipulation
Aug 18, 2024In this paper, we propose ContactSDF, a method that uses signed distance functions (SDFs) to approximate multi-contact models, including both collision detection and time-stepping routines. ContactSDF first establishes an SDF using the supporting plane representation of an object for collision detection, and then use the generated contact dual cones to build a second SDF for time stepping prediction of the next state. Those two SDFs create a differentiable and closed-form multi-contact dynamic model for state prediction, enabling efficient model learning and optimization for contact-rich manipulation. We perform extensive simulation experiments to show the effectiveness of ContactSDF for model learning and real-time control of dexterous manipulation. We further evaluate the ContactSDF on a hardware Allegro hand for on-palm reorientation tasks. Results show with around 2 minutes of learning on hardware, the ContactSDF achieves high-quality dexterous manipulation at a frequency of 30-60Hz.
Complementarity-Free Multi-Contact Modeling and Optimization for Dexterous Manipulation
Aug 14, 2024
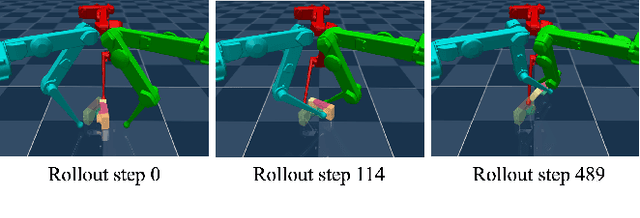
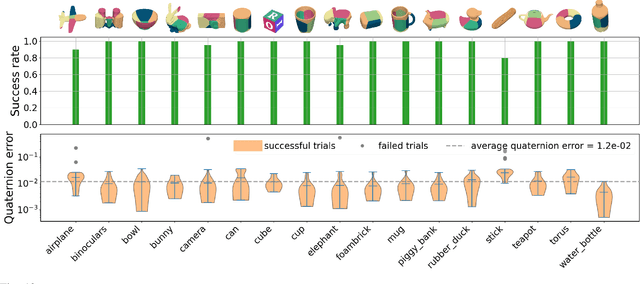

A significant barrier preventing model-based methods from matching the high performance of reinforcement learning in dexterous manipulation is the inherent complexity of multi-contact dynamics. Traditionally formulated using complementarity models, multi-contact dynamics introduces combinatorial complexity and non-smoothness, complicating contact-rich planning and control. In this paper, we circumvent these challenges by introducing a novel, simplified multi-contact model. Our new model, derived from the duality of optimization-based contact models, dispenses with the complementarity constructs entirely, providing computational advantages such as explicit time stepping, differentiability, automatic satisfaction of Coulomb friction law, and minimal hyperparameter tuning. We demonstrate the effectiveness and efficiency of the model for planning and control in a range of challenging dexterous manipulation tasks, including fingertip 3D in-air manipulation, TriFinger in-hand manipulation, and Allegro hand on-palm reorientation, all with diverse objects. Our method consistently achieves state-of-the-art results: (I) a 96.5% average success rate across tasks, (II) high manipulation accuracy with an average reorientation error of 11{\deg} and position error of 7.8 mm, and (III) model predictive control running at 50-100 Hz for all tested dexterous manipulation tasks. These results are achieved with minimal hyperparameter tuning.
A Differential Dynamic Programming Framework for Inverse Reinforcement Learning
Jul 29, 2024A differential dynamic programming (DDP)-based framework for inverse reinforcement learning (IRL) is introduced to recover the parameters in the cost function, system dynamics, and constraints from demonstrations. Different from existing work, where DDP was used for the inner forward problem with inequality constraints, our proposed framework uses it for efficient computation of the gradient required in the outer inverse problem with equality and inequality constraints. The equivalence between the proposed method and existing methods based on Pontryagin's Maximum Principle (PMP) is established. More importantly, using this DDP-based IRL with an open-loop loss function, a closed-loop IRL framework is presented. In this framework, a loss function is proposed to capture the closed-loop nature of demonstrations. It is shown to be better than the commonly used open-loop loss function. We show that the closed-loop IRL framework reduces to a constrained inverse optimal control problem under certain assumptions. Under these assumptions and a rank condition, it is proven that the learning parameters can be recovered from the demonstration data. The proposed framework is extensively evaluated through four numerical robot examples and one real-world quadrotor system. The experiments validate the theoretical results and illustrate the practical relevance of the approach.