 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Anti-Causal Learning for Reconstructing Urban Events from Residents' Reports
Mar 12, 2026Many real-world machine learning tasks are anti-causal: they require inferring latent causes from observed effects. In practice, we often face multiple related tasks where part of the forward causal mechanism is invariant across tasks, while other components are task-specific. We propose Multi-Task Anti-Causal learning (MTAC), a framework for estimating causes from outcomes and confounders by explicitly exploiting such cross-task invariances. MTAC first performs causal discovery to learn a shared causal graph and then instantiates a structured multi-task structural equation model (SEM) that factorizes the outcome-generation process into (i) a task-invariant mechanism and (ii) task-specific mechanisms via a shared backbone with task-specific heads. Building on the learned forward model, MTAC performs maximum A posteriori (MAP)based inference to reconstruct causes by jointly optimizing latent mechanism variables and cause magnitudes under the learned causal structure. We evaluate MTAC on the application of urban event reconstruction from resident reports, spanning three tasks:parking violations, abandoned properties, and unsanitary conditions. On real-world data collected from Manhattan and the city of Newark, MTAC consistently improves reconstruction accuracy over strong baselines, achieving up to 34.61\% MAE reduction and demonstrating the benefit of learning transferable causal mechanisms across tasks.
KidMesh: Computational Mesh Reconstruction for Pediatric Congenital Hydronephrosis Using Deep Neural Networks
Feb 09, 2026Pediatric congenital hydronephrosis (CH) is a common urinary tract disorder, primarily caused by obstruction at the renal pelvis-ureter junction. Magnetic resonance urography (MRU) can visualize hydronephrosis, including renal pelvis and calyces, by utilizing the natural contrast provided by water. Existing voxel-based segmentation approaches can extract CH regions from MRU, facilitating disease diagnosis and prognosis. However, these segmentation methods predominantly focus on morphological features, such as size, shape, and structure. To enable functional assessments, such as urodynamic simulations, external complex post-processing steps are required to convert these results into mesh-level representations. To address this limitation, we propose an end-to-end method based on deep neural networks, namely KidMesh, which could automatically reconstruct CH meshes directly from MRU. Generally, KidMesh extracts feature maps from MRU images and converts them into feature vertices through grid sampling. It then deforms a template mesh according to these feature vertices to generate the specific CH meshes of MRU images. Meanwhile, we develop a novel schema to train KidMesh without relying on accurate mesh-level annotations, which are difficult to obtain due to the sparsely sampled MRU slices. Experimental results show that KidMesh could reconstruct CH meshes in an average of 0.4 seconds, and achieve comparable performance to conventional methods without requiring post-processing. The reconstructed meshes exhibited no self-intersections, with only 3.7% and 0.2% of the vertices having error distances exceeding 3.2mm and 6.4mm, respectively. After rasterization, these meshes achieved a Dice score of 0.86 against manually delineated CH masks. Furthermore, these meshes could be used in renal urine flow simulations, providing valuable urodynamic information for clinical practice.
PalpAid: Multimodal Pneumatic Tactile Sensor for Tissue Palpation
Dec 22, 2025The tactile properties of tissue, such as elasticity and stiffness, often play an important role in surgical oncology when identifying tumors and pathological tissue boundaries. Though extremely valuable, robot-assisted surgery comes at the cost of reduced sensory information to the surgeon; typically, only vision is available. Sensors proposed to overcome this sensory desert are often bulky, complex, and incompatible with the surgical workflow. We present PalpAid, a multimodal pneumatic tactile sensor equipped with a microphone and pressure sensor, converting contact force into an internal pressure differential. The pressure sensor acts as an event detector, while the auditory signature captured by the microphone assists in tissue delineation. We show the design, fabrication, and assembly of sensory units with characterization tests to show robustness to use, inflation-deflation cycles, and integration with a robotic system. Finally, we show the sensor's ability to classify 3D-printed hard objects with varying infills and soft ex vivo tissues. Overall, PalpAid aims to fill the sensory gap intelligently and allow improved clinical decision-making.
TwinTrack: Bridging Vision and Contact Physics for Real-Time Tracking of Unknown Dynamic Objects
May 28, 2025
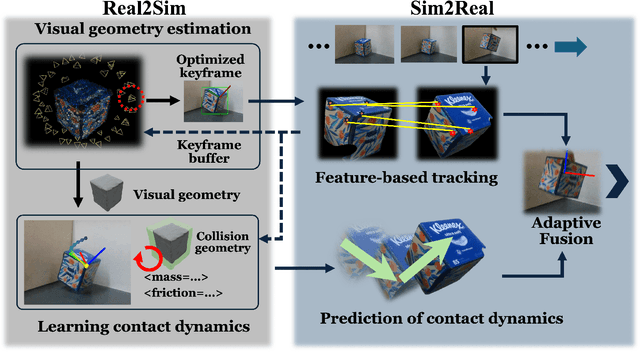
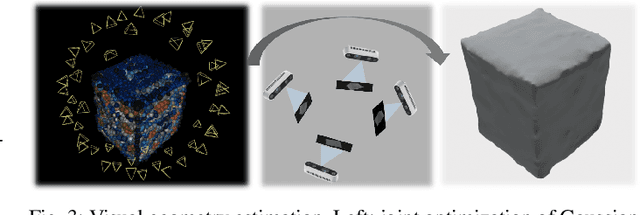
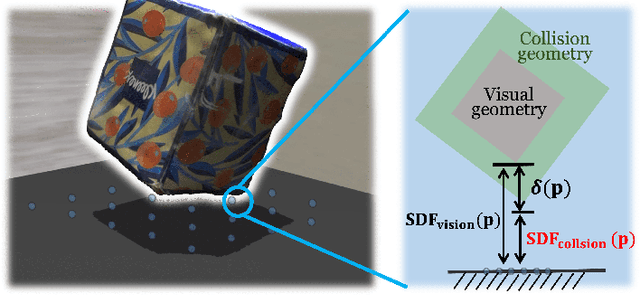
Real-time tracking of previously unseen, highly dynamic objects in contact-rich environments -- such as during dexterous in-hand manipulation -- remains a significant challenge. Purely vision-based tracking often suffers from heavy occlusions due to the frequent contact interactions and motion blur caused by abrupt motion during contact impacts. We propose TwinTrack, a physics-aware visual tracking framework that enables robust and real-time 6-DoF pose tracking of unknown dynamic objects in a contact-rich scene by leveraging the contact physics of the observed scene. At the core of TwinTrack is an integration of Real2Sim and Sim2Real. In Real2Sim, we combine the complementary strengths of vision and contact physics to estimate object's collision geometry and physical properties: object's geometry is first reconstructed from vision, then updated along with other physical parameters from contact dynamics for physical accuracy. In Sim2Real, robust pose estimation of the object is achieved by adaptive fusion between visual tracking and prediction of the learned contact physics. TwinTrack is built on a GPU-accelerated, deeply customized physics engine to ensure real-time performance. We evaluate our method on two contact-rich scenarios: object falling with rich contact impacts against the environment, and contact-rich in-hand manipulation. Experimental results demonstrate that, compared to baseline methods, TwinTrack achieves significantly more robust, accurate, and real-time 6-DoF tracking in these challenging scenarios, with tracking speed exceeding 20 Hz. Project page: https://irislab.tech/TwinTrack-webpage/
Benchmarking performance, explainability, and evaluation strategies of vision-language models for surgery: Challenges and opportunities
May 16, 2025

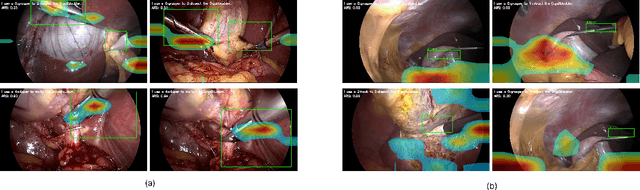

Minimally invasive surgery (MIS) presents significant visual and technical challenges, including surgical instrument classification and understanding surgical action involving instruments, verbs, and anatomical targets. While many machine learning-based methods have been developed for surgical understanding, they typically rely on procedure- and task-specific models trained on small, manually annotated datasets. In contrast, the recent success of vision-language models (VLMs) trained on large volumes of raw image-text pairs has demonstrated strong adaptability to diverse visual data and a range of downstream tasks. This opens meaningful research questions: how well do these general-purpose VLMs perform in the surgical domain? In this work, we explore those questions by benchmarking several VLMs across diverse surgical datasets, including general laparoscopic procedures and endoscopic submucosal dissection, to assess their current capabilities and limitations. Our benchmark reveals key gaps in the models' ability to consistently link language to the correct regions in surgical scenes.
SHADE-AD: An LLM-Based Framework for Synthesizing Activity Data of Alzheimer's Patients
Mar 03, 2025



Alzheimer's Disease (AD) has become an increasingly critical global health concern, which necessitates effective monitoring solutions in smart health applications. However, the development of such solutions is significantly hindered by the scarcity of AD-specific activity datasets. To address this challenge, we propose SHADE-AD, a Large Language Model (LLM) framework for Synthesizing Human Activity Datasets Embedded with AD features. Leveraging both public datasets and our own collected data from 99 AD patients, SHADE-AD synthesizes human activity videos that specifically represent AD-related behaviors. By employing a three-stage training mechanism, it broadens the range of activities beyond those collected from limited deployment settings. We conducted comprehensive evaluations of the generated dataset, demonstrating significant improvements in downstream tasks such as Human Activity Recognition (HAR) detection, with enhancements of up to 79.69%. Detailed motion metrics between real and synthetic data show strong alignment, validating the realism and utility of the synthesized dataset. These results underscore SHADE-AD's potential to advance smart health applications by providing a cost-effective, privacy-preserving solution for AD monitoring.
Patrol Security Game: Defending Against Adversary with Freedom in Attack Timing, Location, and Duration
Oct 21, 2024



We explored the Patrol Security Game (PSG), a robotic patrolling problem modeled as an extensive-form Stackelberg game, where the attacker determines the timing, location, and duration of their attack. Our objective is to devise a patrolling schedule with an infinite time horizon that minimizes the attacker's payoff. We demonstrated that PSG can be transformed into a combinatorial minimax problem with a closed-form objective function. By constraining the defender's strategy to a time-homogeneous first-order Markov chain (i.e., the patroller's next move depends solely on their current location), we proved that the optimal solution in cases of zero penalty involves either minimizing the expected hitting time or return time, depending on the attacker model, and that these solutions can be computed efficiently. Additionally, we observed that increasing the randomness in the patrol schedule reduces the attacker's expected payoff in high-penalty cases. However, the minimax problem becomes non-convex in other scenarios. To address this, we formulated a bi-criteria optimization problem incorporating two objectives: expected maximum reward and entropy. We proposed three graph-based algorithms and one deep reinforcement learning model, designed to efficiently balance the trade-off between these two objectives. Notably, the third algorithm can identify the optimal deterministic patrol schedule, though its runtime grows exponentially with the number of patrol spots. Experimental results validate the effectiveness and scalability of our solutions, demonstrating that our approaches outperform state-of-the-art baselines on both synthetic and real-world crime datasets.
A Unified Deep Semantic Expansion Framework for Domain-Generalized Person Re-identification
Oct 11, 2024



Supervised Person Re-identification (Person ReID) methods have achieved excellent performance when training and testing within one camera network. However, they usually suffer from considerable performance degradation when applied to different camera systems. In recent years, many Domain Adaptation Person ReID methods have been proposed, achieving impressive performance without requiring labeled data from the target domain. However, these approaches still need the unlabeled data of the target domain during the training process, making them impractical in many real-world scenarios. Our work focuses on the more practical Domain Generalized Person Re-identification (DG-ReID) problem. Given one or more source domains, it aims to learn a generalized model that can be applied to unseen target domains. One promising research direction in DG-ReID is the use of implicit deep semantic feature expansion, and our previous method, Domain Embedding Expansion (DEX), is one such example that achieves powerful results in DG-ReID. However, in this work we show that DEX and other similar implicit deep semantic feature expansion methods, due to limitations in their proposed loss function, fail to reach their full potential on large evaluation benchmarks as they have a tendency to saturate too early. Leveraging on this analysis, we propose Unified Deep Semantic Expansion, our novel framework that unifies implicit and explicit semantic feature expansion techniques in a single framework to mitigate this early over-fitting and achieve a new state-of-the-art (SOTA) in all DG-ReID benchmarks. Further, we apply our method on more general image retrieval tasks, also surpassing the current SOTA in all of these benchmarks by wide margins.
Diverse Deep Feature Ensemble Learning for Omni-Domain Generalized Person Re-identification
Oct 11, 2024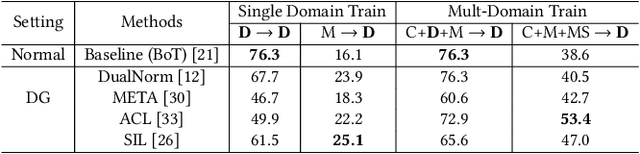

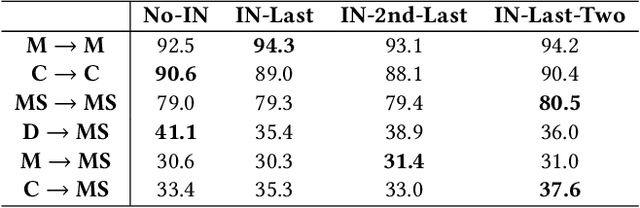

Person Re-identification (Person ReID) has progressed to a level where single-domain supervised Person ReID performance has saturated. However, such methods experience a significant drop in performance when trained and tested across different datasets, motivating the development of domain generalization techniques. However, our research reveals that domain generalization methods significantly underperform single-domain supervised methods on single dataset benchmarks. An ideal Person ReID method should be effective regardless of the number of domains involved, and when test domain data is available for training it should perform as well as state-of-the-art (SOTA) fully supervised methods. This is a paradigm that we call Omni-Domain Generalization Person ReID (ODG-ReID). We propose a way to achieve ODG-ReID by creating deep feature diversity with self-ensembles. Our method, Diverse Deep Feature Ensemble Learning (D2FEL), deploys unique instance normalization patterns that generate multiple diverse views and recombines these views into a compact encoding. To the best of our knowledge, our work is one of few to consider omni-domain generalization in Person ReID, and we advance the study of applying feature ensembles in Person ReID. D2FEL significantly improves and matches the SOTA performance for major domain generalization and single-domain supervised benchmarks.
Aligned Divergent Pathways for Omni-Domain Generalized Person Re-Identification
Oct 11, 2024Person Re-identification (Person ReID) has advanced significantly in fully supervised and domain generalized Person R e ID. However, methods developed for one task domain transfer poorly to the other. An ideal Person ReID method should be effective regardless of the number of domains involved in training or testing. Furthermore, given training data from the target domain, it should perform at least as well as state-of-the-art (SOTA) fully supervised Person ReID methods. We call this paradigm Omni-Domain Generalization Person ReID, referred to as ODG-ReID, and propose a way to achieve this by expanding compatible backbone architectures into multiple diverse pathways. Our method, Aligned Divergent Pathways (ADP), first converts a base architecture into a multi-branch structure by copying the tail of the original backbone. We design our module Dynamic Max-Deviance Adaptive Instance Normalization (DyMAIN) that encourages learning of generalized features that are robust to omni-domain directions and apply DyMAIN to the branches of ADP. Our proposed Phased Mixture-of-Cosines (PMoC) coordinates a mix of stable and turbulent learning rate schedules among branches for further diversified learning. Finally, we realign the feature space between branches with our proposed Dimensional Consistency Metric Loss (DCML). ADP outperforms the state-of-the-art (SOTA) results for multi-source domain generalization and supervised ReID within the same domain. Furthermore, our method demonstrates improvement on a wide range of single-source domain generalization benchmarks, achieving Omni-Domain Generalization over Person ReID tasks.