 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRASLF: Representation-Aware State Space Model for Light Field Super-Resolution
Mar 17, 2026Current SSM-based light field super-resolution (LFSR) methods often fail to fully leverage the complementarity among various LF representations, leading to the loss of fine textures and geometric misalignments across views. To address these issues, we propose RASLF, a representation-aware state-space framework that explicitly models structural correlations across multiple LF representations. Specifically, a Progressive Geometric Refinement (PGR) block is created that uses a panoramic epipolar representation to explicitly encode multi-view parallax differences, thereby enabling integration across different LF representations. Furthermore, we introduce a Representation Aware Asymmetric Scanning (RAAS) mechanism that dynamically adjusts scanning paths based on the physical properties of different representation spaces, optimizing the balance between performance and efficiency through path pruning. Additionally, a Dual-Anchor Aggregation (DAA) module improves hierarchical feature flow, reducing redundant deeplayer features and prioritizing important reconstruction information. Experiments on various public benchmarks show that RASLF achieves the highest reconstruction accuracy while remaining highly computationally efficient.
EyeWorld: A Generative World Model of Ocular State and Dynamics
Mar 14, 2026Ophthalmic decision-making depends on subtle lesion-scale cues interpreted across multimodal imaging and over time, yet most medical foundation models remain static and degrade under modality and acquisition shifts. Here we introduce EyeWorld, a generative world model that conceptualizes the eye as a partially observed dynamical system grounded in clinical imaging. EyeWorld learns an observation-stable latent ocular state shared across modalities, unifying fine-grained parsing, structure-preserving cross-modality translation and quality-robust enhancement within a single framework. Longitudinal supervision further enables time-conditioned state transitions, supporting forecasting of clinically meaningful progression while preserving stable anatomy. By moving from static representation learning to explicit dynamical modeling, EyeWorld provides a unified approach to robust multimodal interpretation and prognosis-oriented simulation in medicine.
$L^2$FMamba: Lightweight Light Field Image Super-Resolution with State Space Model
Mar 25, 2025Transformers bring significantly improved performance to the light field image super-resolution task due to their long-range dependency modeling capability. However, the inherently high computational complexity of their core self-attention mechanism has increasingly hindered their advancement in this task. To address this issue, we first introduce the LF-VSSM block, a novel module inspired by progressive feature extraction, to efficiently capture critical long-range spatial-angular dependencies in light field images. LF-VSSM successively extracts spatial features within sub-aperture images, spatial-angular features between sub-aperture images, and spatial-angular features between light field image pixels. On this basis, we propose a lightweight network, $L^2$FMamba (Lightweight Light Field Mamba), which integrates the LF-VSSM block to leverage light field features for super-resolution tasks while overcoming the computational challenges of Transformer-based approaches. Extensive experiments on multiple light field datasets demonstrate that our method reduces the number of parameters and complexity while achieving superior super-resolution performance with faster inference speed.
DeepSeek-R1 Outperforms Gemini 2.0 Pro, OpenAI o1, and o3-mini in Bilingual Complex Ophthalmology Reasoning
Feb 25, 2025Purpose: To evaluate the accuracy and reasoning ability of DeepSeek-R1 and three other recently released large language models (LLMs) in bilingual complex ophthalmology cases. Methods: A total of 130 multiple-choice questions (MCQs) related to diagnosis (n = 39) and management (n = 91) were collected from the Chinese ophthalmology senior professional title examination and categorized into six topics. These MCQs were translated into English using DeepSeek-R1. The responses of DeepSeek-R1, Gemini 2.0 Pro, OpenAI o1 and o3-mini were generated under default configurations between February 15 and February 20, 2025. Accuracy was calculated as the proportion of correctly answered questions, with omissions and extra answers considered incorrect. Reasoning ability was evaluated through analyzing reasoning logic and the causes of reasoning error. Results: DeepSeek-R1 demonstrated the highest overall accuracy, achieving 0.862 in Chinese MCQs and 0.808 in English MCQs. Gemini 2.0 Pro, OpenAI o1, and OpenAI o3-mini attained accuracies of 0.715, 0.685, and 0.692 in Chinese MCQs (all P<0.001 compared with DeepSeek-R1), and 0.746 (P=0.115), 0.723 (P=0.027), and 0.577 (P<0.001) in English MCQs, respectively. DeepSeek-R1 achieved the highest accuracy across five topics in both Chinese and English MCQs. It also excelled in management questions conducted in Chinese (all P<0.05). Reasoning ability analysis showed that the four LLMs shared similar reasoning logic. Ignoring key positive history, ignoring key positive signs, misinterpretation medical data, and too aggressive were the most common causes of reasoning errors. Conclusion: DeepSeek-R1 demonstrated superior performance in bilingual complex ophthalmology reasoning tasks than three other state-of-the-art LLMs. While its clinical applicability remains challenging, it shows promise for supporting diagnosis and clinical decision-making.
EyeCLIP: A visual-language foundation model for multi-modal ophthalmic image analysis
Sep 10, 2024Early detection of eye diseases like glaucoma, macular degeneration, and diabetic retinopathy is crucial for preventing vision loss. While artificial intelligence (AI) foundation models hold significant promise for addressing these challenges, existing ophthalmic foundation models primarily focus on a single modality, whereas diagnosing eye diseases requires multiple modalities. A critical yet often overlooked aspect is harnessing the multi-view information across various modalities for the same patient. Additionally, due to the long-tail nature of ophthalmic diseases, standard fully supervised or unsupervised learning approaches often struggle. Therefore, it is essential to integrate clinical text to capture a broader spectrum of diseases. We propose EyeCLIP, a visual-language foundation model developed using over 2.77 million multi-modal ophthalmology images with partial text data. To fully leverage the large multi-modal unlabeled and labeled data, we introduced a pretraining strategy that combines self-supervised reconstructions, multi-modal image contrastive learning, and image-text contrastive learning to learn a shared representation of multiple modalities. Through evaluation using 14 benchmark datasets, EyeCLIP can be transferred to a wide range of downstream tasks involving ocular and systemic diseases, achieving state-of-the-art performance in disease classification, visual question answering, and cross-modal retrieval. EyeCLIP represents a significant advancement over previous methods, especially showcasing few-shot, even zero-shot capabilities in real-world long-tail scenarios.
Low-Complexity SVM Signal Recovery in Bandwidth-Limited 100Gb/s PAM4 PON Upstream
Jul 04, 2024


We proposed a low-complexity SVM-based signal recovery algorithm and evaluated it in 100G-PON with 25G-class devices. For the first time, it experimentally achieved 24 dB power budget @ FEC threshold 1E-3 over 40 km SMF, improving receiver sensitivity over 2 dB compared to FFE&DFE.
LUT-boosted CDR and Equalization for Burst-mode 50/100 Gbit/s Bandwidth-limited Flexible PON
Jun 28, 2024We proposed and experimentally demonstrated a look-up table boosted fast CDR and equalization scheme for the burst-mode 50/100 Gbps bandwidth-limited flexible PON, requiring no preamble for convergence and achieved the same bit error rate performance as in the case of long preambles.
Masked Contrastive Reconstruction for Cross-modal Medical Image-Report Retrieval
Dec 27, 2023Cross-modal medical image-report retrieval task plays a significant role in clinical diagnosis and various medical generative tasks. Eliminating heterogeneity between different modalities to enhance semantic consistency is the key challenge of this task. The current Vision-Language Pretraining (VLP) models, with cross-modal contrastive learning and masked reconstruction as joint training tasks, can effectively enhance the performance of cross-modal retrieval. This framework typically employs dual-stream inputs, using unmasked data for cross-modal contrastive learning and masked data for reconstruction. However, due to task competition and information interference caused by significant differences between the inputs of the two proxy tasks, the effectiveness of representation learning for intra-modal and cross-modal features is limited. In this paper, we propose an efficient VLP framework named Masked Contrastive and Reconstruction (MCR), which takes masked data as the sole input for both tasks. This enhances task connections, reducing information interference and competition between them, while also substantially decreasing the required GPU memory and training time. Moreover, we introduce a new modality alignment strategy named Mapping before Aggregation (MbA). Unlike previous methods, MbA maps different modalities to a common feature space before conducting local feature aggregation, thereby reducing the loss of fine-grained semantic information necessary for improved modality alignment. Qualitative and quantitative experiments conducted on the MIMIC-CXR dataset validate the effectiveness of our approach, demonstrating state-of-the-art performance in medical cross-modal retrieval tasks.
Learning from Noisy Labels Generated by Extremely Point Annotations for OCT Fluid Segmentation
Jun 05, 2023



Automatic segmentation of fluid in OCT (Optical Coherence Tomography) images is beneficial for ophthalmologists to make an accurate diagnosis. Currently, data-driven convolutional neural networks (CNNs) have achieved great success in OCT fluid segmentation. However, obtaining pixel-level masks of OCT images is time-consuming and requires expertise. The popular weakly-supervised strategy is to generate noisy pseudo-labels from weak annotations, but the noise information introduced may mislead the model training. To address this issue, (i) we propose a superpixel-guided method for generating noisy labels from weak point annotations, called Point to Noisy by Superpixel (PNS), which limits the network from over-fitting noise by assigning low confidence to suspiciously noisy label pixels, and (ii) we propose a Two-Stage Mean-Teacher-assisted Confident Learning (2SMTCL) method based on MTCL for multi-category OCT fluid segmentation, which alleviates the uncertainty and computing power consumption introduced by the real-time characterization noise of MTCL. For evaluation, we have constructed a 2D OCT fluid segmentation dataset. Compared with other state-of-art label-denoising methods, comprehensive experimental results demonstrate that the proposed method can achieve excellent performance in OCT fluid segmentation as well as label denoising. Our study provides an efficient, accurate, and practical solution for fluid segmentation of OCT images, which is expected to have a positive impact on the diagnosis and treatment of patients in the field of ophthalmology.
Dispensed Transformer Network for Unsupervised Domain Adaptation
Oct 28, 2021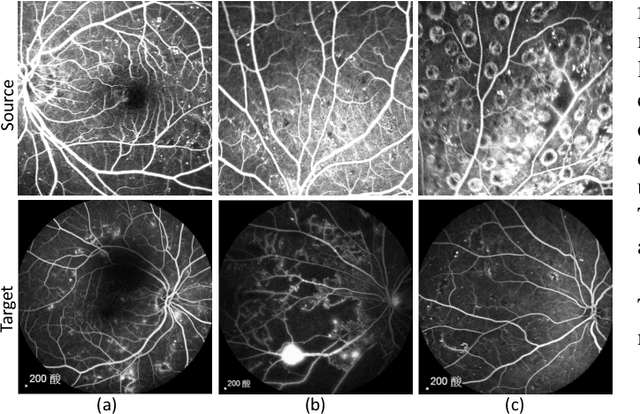
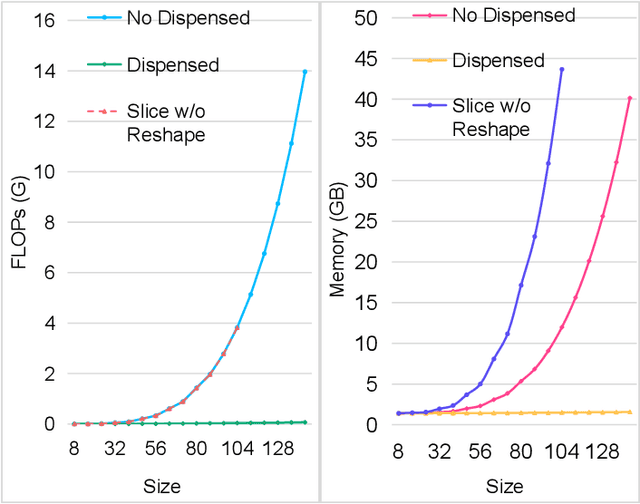
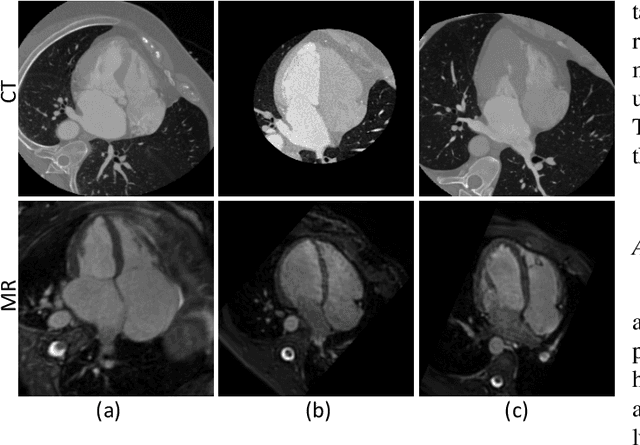
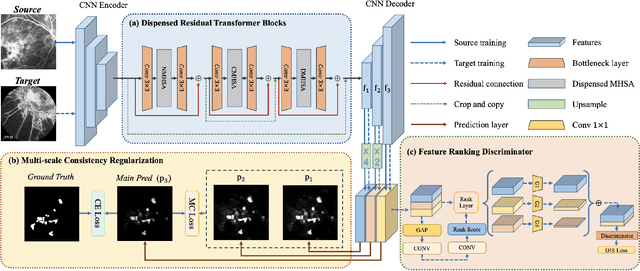
Accurate segmentation is a crucial step in medical image analysis and applying supervised machine learning to segment the organs or lesions has been substantiated effective. However, it is costly to perform data annotation that provides ground truth labels for training the supervised algorithms, and the high variance of data that comes from different domains tends to severely degrade system performance over cross-site or cross-modality datasets. To mitigate this problem, a novel unsupervised domain adaptation (UDA) method named dispensed Transformer network (DTNet) is introduced in this paper. Our novel DTNet contains three modules. First, a dispensed residual transformer block is designed, which realizes global attention by dispensed interleaving operation and deals with the excessive computational cost and GPU memory usage of the Transformer. Second, a multi-scale consistency regularization is proposed to alleviate the loss of details in the low-resolution output for better feature alignment. Finally, a feature ranking discriminator is introduced to automatically assign different weights to domain-gap features to lessen the feature distribution distance, reducing the performance shift of two domains. The proposed method is evaluated on large fluorescein angiography (FA) retinal nonperfusion (RNP) cross-site dataset with 676 images and a wide used cross-modality dataset from the MM-WHS challenge. Extensive results demonstrate that our proposed network achieves the best performance in comparison with several state-of-the-art techniques.