 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoTail-BSFGM: Class-Balance-Aware Fine-Tuning for Chinese Scholarly Text Classification
Jun 02, 2026Scholarly text classification supports literature organization, subject indexing, and research intelligence, but Chinese scholarly corpora often contain imbalanced and semantically adjacent disciplinary labels. We propose AutoTail-BSFGM, a class-balance-aware fine-tuning method that combines an automatically gated tail-prior adjustment, a weak Balanced Softmax auxiliary loss, and Fast Gradient Method adversarial regularization. The method changes only the training objective and procedure; inference uses the same single base-size encoder and linear classifier as the corresponding label-smoothed baseline. We evaluate the method on two CSL-based tasks: an abstract-to-discipline task with 67 labels and a title-to-category task with 13 categories. On the primary abstract task, AutoTail-BSFGM improves validation and lockbox accuracy under both Chinese RoBERTa-WWM and MacBERT-base. With MacBERT-base, validation accuracy increases by 0.83 percentage points and lockbox accuracy by 0.49 points, with a pooled paired McNemar signal on validation (p = 0.023). On the title task, the method improves validation accuracy by 0.70 points and validation balanced accuracy by 2.64 points; lockbox accuracy is approximately neutral while lockbox balanced accuracy improves by 1.22 points. The results support a bounded contribution: AutoTail-BSFGM improves class-balance-sensitive behavior and yields consistent gains for abstract-based scholarly classification, without uniformly improving every metric on every split.
Learning to Perceive "Where": Spatial Pretext Tasks for Robust Self-Supervised Learning
May 11, 2026Existing self-supervised learning (SSL) methods primarily learn object-invariant representations but often neglect the spatial structure and relationships among object parts. To address this limitation, we introduce Spatial Prediction (SP), a spatially aware pretext regression task that predicts the relative position and scale between a pair of disentangled local views from the same image. By modeling part-to-part relationships in a continuous geometric space, SP encourages representations to capture fine-grained spatial dependencies beyond invariant categorical semantics, thereby learning the compositional structure of visual scenes. SP is implemented as a decoupled plug-in and can be seamlessly integrated into diverse SSL frameworks. Extensive experiments show consistent improvements across image recognition, fine-grained classification, semantic segmentation, and depth estimation, as well as substantial gains in out-of-distribution robustness for object recognition. To evaluate spatial reasoning, we introduce (1) a position and scale prediction task on image patch pairs and (2) a jigsaw understanding task requiring patch reordering and recognition after reconstruction. Strong performance on these tasks indicates improved spatial structure and geometric awareness. Overall, explicitly modeling spatial information provides an effective inductive bias for SSL, leading to more structured representations and better generalization. Code and models will be released.
An Empirical Study of Multi-Agent Collaboration for Automated Research
Mar 31, 2026As AI agents evolve, the community is rapidly shifting from single Large Language Models (LLMs) to Multi-Agent Systems (MAS) to overcome cognitive bottlenecks in automated research. However, the optimal multi-agent coordination framework for these autonomous agents remains largely unexplored. In this paper, we present a systematic empirical study investigating the comparative efficacy of distinct multi-agent structures for automated machine learning optimization. Utilizing a rigorously controlled, execution-based testbed equipped with Git worktree isolation and explicit global memory, we benchmark a single-agent baseline against two multi-agent paradigms: a subagent architecture (parallel exploration with post-hoc consolidation) and an agent team architecture (experts with pre-execution handoffs). By evaluating these systems under strictly fixed computational time budgets, our findings reveal a fundamental trade-off between operational stability and theoretical deliberation. The subagent mode functions as a highly resilient, high-throughput search engine optimal for broad, shallow optimizations under strict time constraints. Conversely, the agent team topology exhibits higher operational fragility due to multi-author code generation but achieves the deep theoretical alignment necessary for complex architectural refactoring given extended compute budgets. These empirical insights provide actionable guidelines for designing future autoresearch systems, advocating for dynamically routed architectures that adapt their collaborative structures to real-time task complexity.
AesRec: A Dataset for Aesthetics-Aligned Clothing Outfit Recommendation
Feb 03, 2026Clothing recommendation extends beyond merely generating personalized outfits; it serves as a crucial medium for aesthetic guidance. However, existing methods predominantly rely on user-item-outfit interaction behaviors while overlooking explicit representations of clothing aesthetics. To bridge this gap, we present the AesRec benchmark dataset featuring systematic quantitative aesthetic annotations, thereby enabling the development of aesthetics-aligned recommendation systems. Grounded in professional apparel quality standards and fashion aesthetic principles, we define a multidimensional set of indicators. At the item level, six dimensions are independently assessed: silhouette, chromaticity, materiality, craftsmanship, wearability, and item-level impression. Transitioning to the outfit level, the evaluation retains the first five core attributes while introducing stylistic synergy, visual harmony, and outfit-level impression as distinct metrics to capture the collective aesthetic impact. Given the increasing human-like proficiency of Vision-Language Models in multimodal understanding and interaction, we leverage them for large-scale aesthetic scoring. We conduct rigorous human-machine consistency validation on a fashion dataset, confirming the reliability of the generated ratings. Experimental results based on AesRec further demonstrate that integrating quantified aesthetic information into clothing recommendation models can provide aesthetic guidance for users while fulfilling their personalized requirements.
BrainStack: Neuro-MoE with Functionally Guided Expert Routing for EEG-Based Language Decoding
Jan 29, 2026Decoding linguistic information from electroencephalography (EEG) remains challenging due to the brain's distributed and nonlinear organization. We present BrainStack, a functionally guided neuro-mixture-of-experts (Neuro-MoE) framework that models the brain's modular functional architecture through anatomically partitioned expert networks. Each functional region is represented by a specialized expert that learns localized neural dynamics, while a transformer-based global expert captures cross-regional dependencies. A learnable routing gate adaptively aggregates these heterogeneous experts, enabling context-dependent expert coordination and selective fusion. To promote coherent representation across the hierarchy, we introduce cross-regional distillation, where the global expert provides top-down regularization to the regional experts. We further release SilentSpeech-EEG (SS-EEG), a large-scale benchmark comprising over 120 hours of EEG recordings from 12 subjects performing 24 silent words, the largest dataset of its kind. Experiments demonstrate that BrainStack consistently outperforms state-of-the-art models, achieving superior accuracy and generalization across subjects. Our results establish BrainStack as a functionally modular, neuro-inspired MoE paradigm that unifies neuroscientific priors with adaptive expert routing, paving the way for scalable and interpretable brain-language decoding.
HyCoRA: Hyper-Contrastive Role-Adaptive Learning for Role-Playing
Nov 11, 2025Multi-character role-playing aims to equip models with the capability to simulate diverse roles. Existing methods either use one shared parameterized module across all roles or assign a separate parameterized module to each role. However, the role-shared module may ignore distinct traits of each role, weakening personality learning, while the role-specific module may overlook shared traits across multiple roles, hindering commonality modeling. In this paper, we propose a novel HyCoRA: Hyper-Contrastive Role-Adaptive learning framework, which efficiently improves multi-character role-playing ability by balancing the learning of distinct and shared traits. Specifically, we propose a Hyper-Half Low-Rank Adaptation structure, where one half is a role-specific module generated by a lightweight hyper-network, and the other half is a trainable role-shared module. The role-specific module is devised to represent distinct persona signatures, while the role-shared module serves to capture common traits. Moreover, to better reflect distinct personalities across different roles, we design a hyper-contrastive learning mechanism to help the hyper-network distinguish their unique characteristics. Extensive experimental results on both English and Chinese available benchmarks demonstrate the superiority of our framework. Further GPT-4 evaluations and visual analyses also verify the capability of HyCoRA to capture role characteristics.
Efficient Token Compression for Vision Transformer with Spatial Information Preserved
Mar 30, 2025



Token compression is essential for reducing the computational and memory requirements of transformer models, enabling their deployment in resource-constrained environments. In this work, we propose an efficient and hardware-compatible token compression method called Prune and Merge. Our approach integrates token pruning and merging operations within transformer models to achieve layer-wise token compression. By introducing trainable merge and reconstruct matrices and utilizing shortcut connections, we efficiently merge tokens while preserving important information and enabling the restoration of pruned tokens. Additionally, we introduce a novel gradient-weighted attention scoring mechanism that computes token importance scores during the training phase, eliminating the need for separate computations during inference and enhancing compression efficiency. We also leverage gradient information to capture the global impact of tokens and automatically identify optimal compression structures. Extensive experiments on the ImageNet-1k and ADE20K datasets validate the effectiveness of our approach, achieving significant speed-ups with minimal accuracy degradation compared to state-of-the-art methods. For instance, on DeiT-Small, we achieve a 1.64$\times$ speed-up with only a 0.2\% drop in accuracy on ImageNet-1k. Moreover, by compressing segmenter models and comparing with existing methods, we demonstrate the superior performance of our approach in terms of efficiency and effectiveness. Code and models have been made available at https://github.com/NUST-Machine-Intelligence-Laboratory/prune_and_merge.
LatexBlend: Scaling Multi-concept Customized Generation with Latent Textual Blending
Mar 10, 2025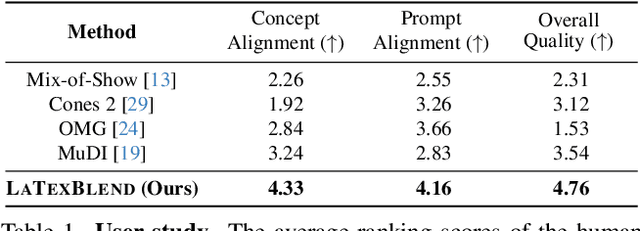
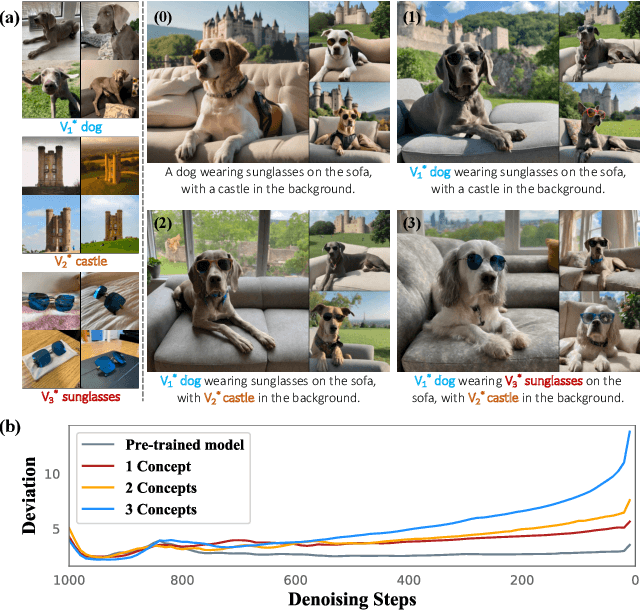
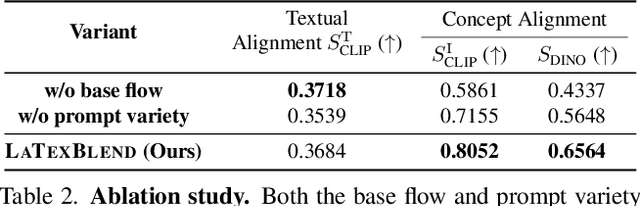
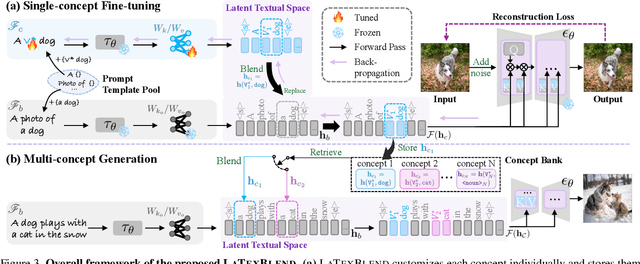
Customized text-to-image generation renders user-specified concepts into novel contexts based on textual prompts. Scaling the number of concepts in customized generation meets a broader demand for user creation, whereas existing methods face challenges with generation quality and computational efficiency. In this paper, we propose LaTexBlend, a novel framework for effectively and efficiently scaling multi-concept customized generation. The core idea of LaTexBlend is to represent single concepts and blend multiple concepts within a Latent Textual space, which is positioned after the text encoder and a linear projection. LaTexBlend customizes each concept individually, storing them in a concept bank with a compact representation of latent textual features that captures sufficient concept information to ensure high fidelity. At inference, concepts from the bank can be freely and seamlessly combined in the latent textual space, offering two key merits for multi-concept generation: 1) excellent scalability, and 2) significant reduction of denoising deviation, preserving coherent layouts. Extensive experiments demonstrate that LaTexBlend can flexibly integrate multiple customized concepts with harmonious structures and high subject fidelity, substantially outperforming baselines in both generation quality and computational efficiency. Our code will be publicly available.
Multi-Agent Coordination across Diverse Applications: A Survey
Feb 21, 2025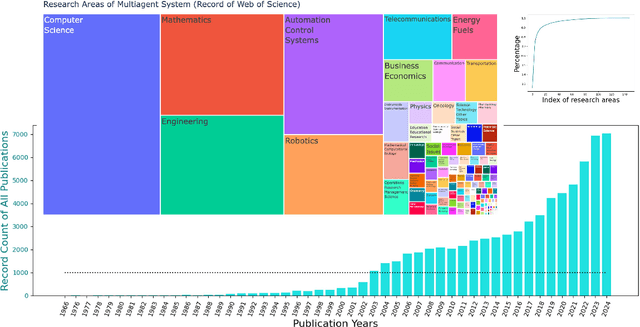
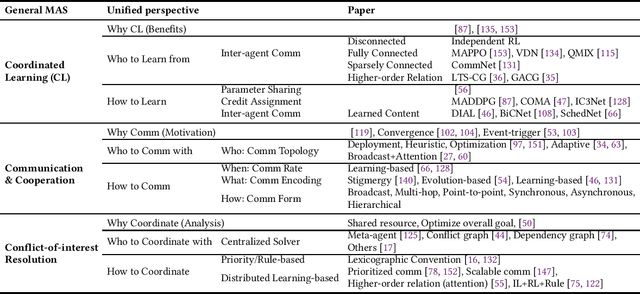
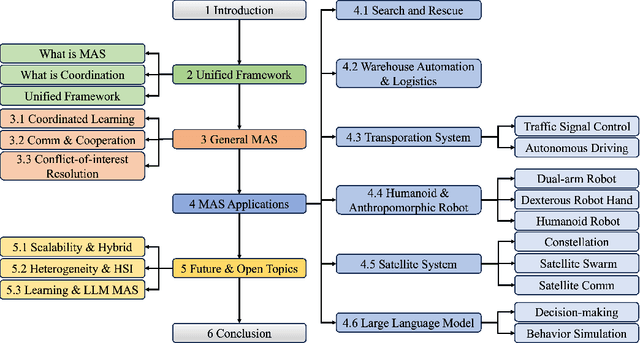
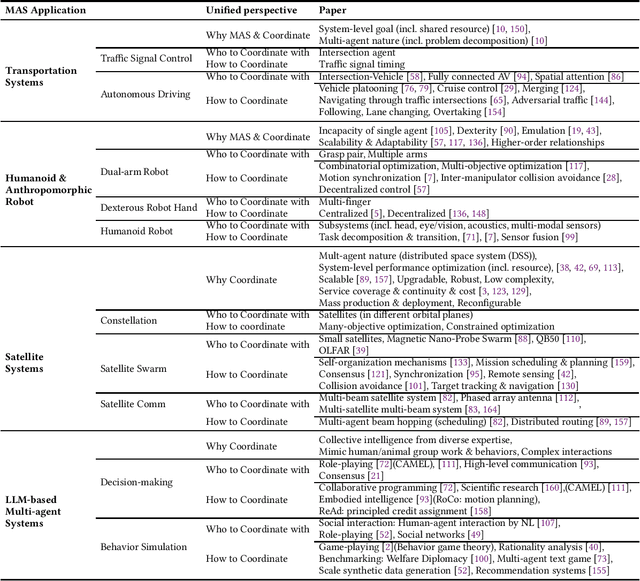
Multi-agent coordination studies the underlying mechanism enabling the trending spread of diverse multi-agent systems (MAS) and has received increasing attention, driven by the expansion of emerging applications and rapid AI advances. This survey outlines the current state of coordination research across applications through a unified understanding that answers four fundamental coordination questions: (1) what is coordination; (2) why coordination; (3) who to coordinate with; and (4) how to coordinate. Our purpose is to explore existing ideas and expertise in coordination and their connections across diverse applications, while identifying and highlighting emerging and promising research directions. First, general coordination problems that are essential to varied applications are identified and analyzed. Second, a number of MAS applications are surveyed, ranging from widely studied domains, e.g., search and rescue, warehouse automation and logistics, and transportation systems, to emerging fields including humanoid and anthropomorphic robots, satellite systems, and large language models (LLMs). Finally, open challenges about the scalability, heterogeneity, and learning mechanisms of MAS are analyzed and discussed. In particular, we identify the hybridization of hierarchical and decentralized coordination, human-MAS coordination, and LLM-based MAS as promising future directions.
Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization
Dec 25, 2024


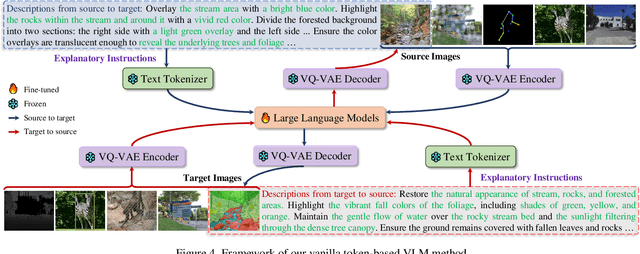
Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.