 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuneAhead: Predicting Fine-tuning Performance Before Full Training Begins
Jun 16, 2026Fine-tuning large language models (LLMs) is compute-intensive and error-prone: model performance depends sensitively on data quality and hyperparameter choices, and naïve runs can even degrade model performance. This raises a practical question:can we predict fine-tuning performance before committing to a full training run? We present TUNEAHEAD, a lightweight framework for pre-hoc prediction of fine-tuning performance. TUNEAHEAD encodes each candidate run as a meta-feature vector that combines static dataset descriptors with dynamic probe features from a short standardized probe. A predictor maps these features to performance estimates, while SHAP-based attributions provide interpretable diagnostics that reveal which specific features drive the prediction. Across 1,300+ fine-tuning runs on Qwen2.5-7B-Instruct, TUNEAHEAD consistently outperforms strong baselines such as Early-Stop Extrapolation and ProxyLM. On a held-out test set of 370 runs, TUNEAHEAD achieves an RMSE of 1.47 percentage points and places 95.1% of predictions within +3/-3 percentage points of the true score. These accurate continuous predictions support practical go/no-go screening policies that can reduce unnecessary full fine-tuning while retaining most promising runs.
Time Travel is Cheating: Going Live with DeepFund for Real-Time Fund Investment Benchmarking
May 16, 2025Large Language Models (LLMs) have demonstrated notable capabilities across financial tasks, including financial report summarization, earnings call transcript analysis, and asset classification. However, their real-world effectiveness in managing complex fund investment remains inadequately assessed. A fundamental limitation of existing benchmarks for evaluating LLM-driven trading strategies is their reliance on historical back-testing, inadvertently enabling LLMs to "time travel"-leveraging future information embedded in their training corpora, thus resulting in possible information leakage and overly optimistic performance estimates. To address this issue, we introduce DeepFund, a live fund benchmark tool designed to rigorously evaluate LLM in real-time market conditions. Utilizing a multi-agent architecture, DeepFund connects directly with real-time stock market data-specifically data published after each model pretraining cutoff-to ensure fair and leakage-free evaluations. Empirical tests on nine flagship LLMs from leading global institutions across multiple investment dimensions-including ticker-level analysis, investment decision-making, portfolio management, and risk control-reveal significant practical challenges. Notably, even cutting-edge models such as DeepSeek-V3 and Claude-3.7-Sonnet incur net trading losses within DeepFund real-time evaluation environment, underscoring the present limitations of LLMs for active fund management. Our code is available at https://github.com/HKUSTDial/DeepFund.
Multi-Agent Coordination across Diverse Applications: A Survey
Feb 21, 2025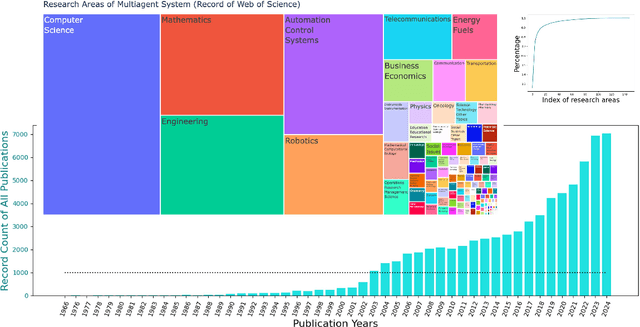
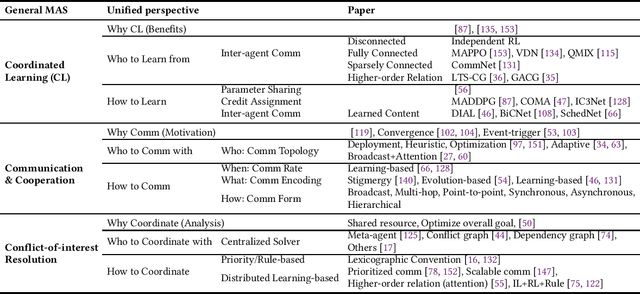
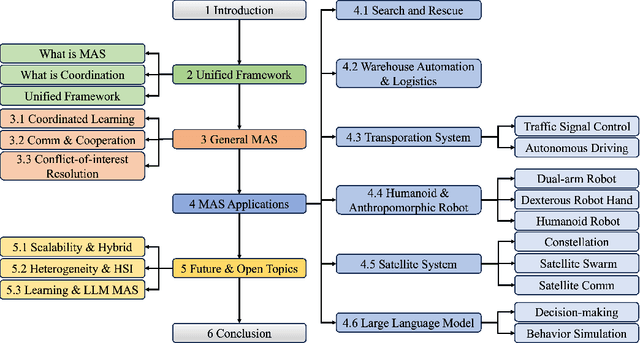
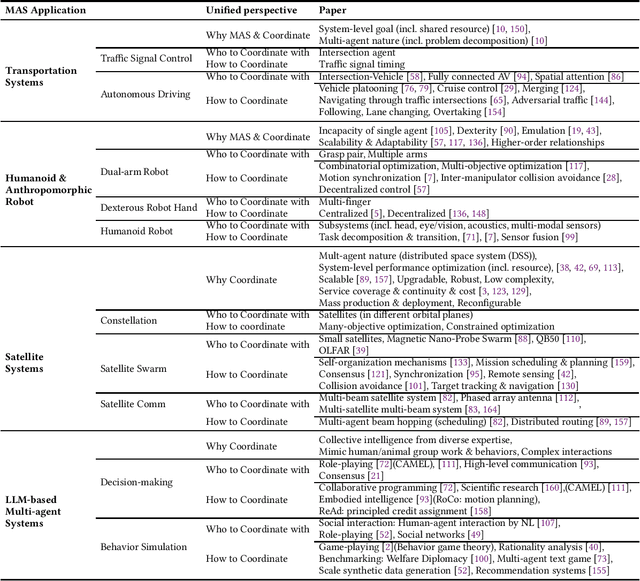
Multi-agent coordination studies the underlying mechanism enabling the trending spread of diverse multi-agent systems (MAS) and has received increasing attention, driven by the expansion of emerging applications and rapid AI advances. This survey outlines the current state of coordination research across applications through a unified understanding that answers four fundamental coordination questions: (1) what is coordination; (2) why coordination; (3) who to coordinate with; and (4) how to coordinate. Our purpose is to explore existing ideas and expertise in coordination and their connections across diverse applications, while identifying and highlighting emerging and promising research directions. First, general coordination problems that are essential to varied applications are identified and analyzed. Second, a number of MAS applications are surveyed, ranging from widely studied domains, e.g., search and rescue, warehouse automation and logistics, and transportation systems, to emerging fields including humanoid and anthropomorphic robots, satellite systems, and large language models (LLMs). Finally, open challenges about the scalability, heterogeneity, and learning mechanisms of MAS are analyzed and discussed. In particular, we identify the hybridization of hierarchical and decentralized coordination, human-MAS coordination, and LLM-based MAS as promising future directions.
Exploring Accuracy-Fairness Trade-off in Large Language Models
Nov 21, 2024



Large Language Models (LLMs) have made significant strides in the field of artificial intelligence, showcasing their ability to interact with humans and influence human cognition through information dissemination. However, recent studies have brought to light instances of bias inherent within these LLMs, presenting a critical issue that demands attention. In our research, we delve deeper into the intricate challenge of harmonising accuracy and fairness in the enhancement of LLMs. While improving accuracy can indeed enhance overall LLM performance, it often occurs at the expense of fairness. Overemphasising optimisation of one metric invariably leads to a significant degradation of the other. This underscores the necessity of taking into account multiple considerations during the design and optimisation phases of LLMs. Therefore, we advocate for reformulating the LLM training process as a multi-objective learning task. Our investigation reveals that multi-objective evolutionary learning (MOEL) methodologies offer promising avenues for tackling this challenge. Our MOEL framework enables the simultaneous optimisation of both accuracy and fairness metrics, resulting in a Pareto-optimal set of LLMs. In summary, our study sheds valuable lights on the delicate equilibrium between accuracy and fairness within LLMs, which is increasingly significant for their real-world applications. By harnessing MOEL, we present a promising pathway towards fairer and more efficacious AI technologies.
Automated Metaheuristic Algorithm Design with Autoregressive Learning
May 06, 2024



Automated design of metaheuristic algorithms offers an attractive avenue to reduce human effort and gain enhanced performance beyond human intuition. Current automated methods design algorithms within a fixed structure and operate from scratch. This poses a clear gap towards fully discovering potentials over the metaheuristic family and fertilizing from prior design experience. To bridge the gap, this paper proposes an autoregressive learning-based designer for automated design of metaheuristic algorithms. Our designer formulates metaheuristic algorithm design as a sequence generation task, and harnesses an autoregressive generative network to handle the task. This offers two advances. First, through autoregressive inference, the designer generates algorithms with diverse lengths and structures, enabling to fully discover potentials over the metaheuristic family. Second, prior design knowledge learned and accumulated in neurons of the designer can be retrieved for designing algorithms for future problems, paving the way to continual design of algorithms for open-ended problem-solving. Extensive experiments on numeral benchmarks and real-world problems reveal that the proposed designer generates algorithms that outperform all human-created baselines on 24 out of 25 test problems. The generated algorithms display various structures and behaviors, reasonably fitting for different problem-solving contexts. Code will be released after paper publication.
Distributed Evolution Strategies with Multi-Level Learning for Large-Scale Black-Box Optimization
Oct 10, 2023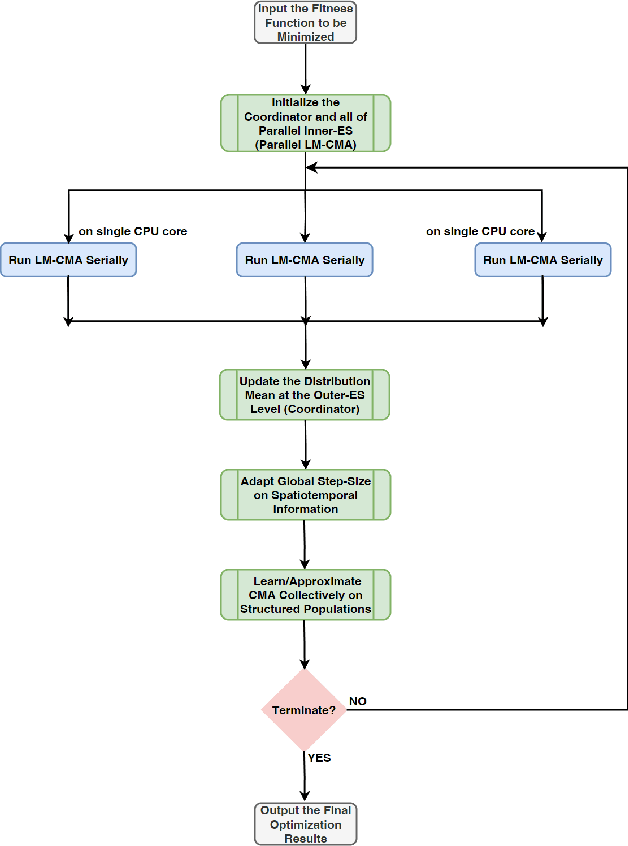
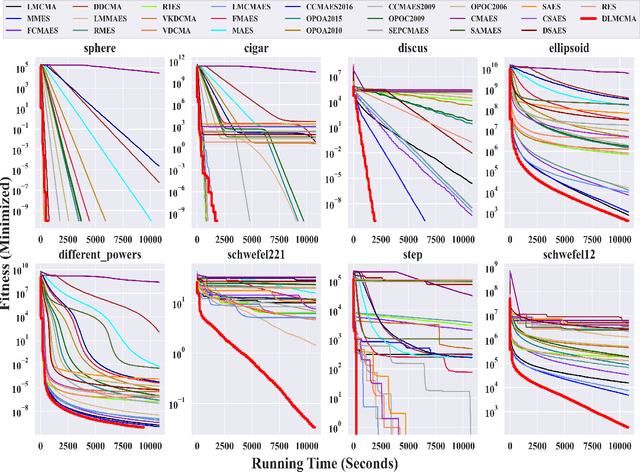
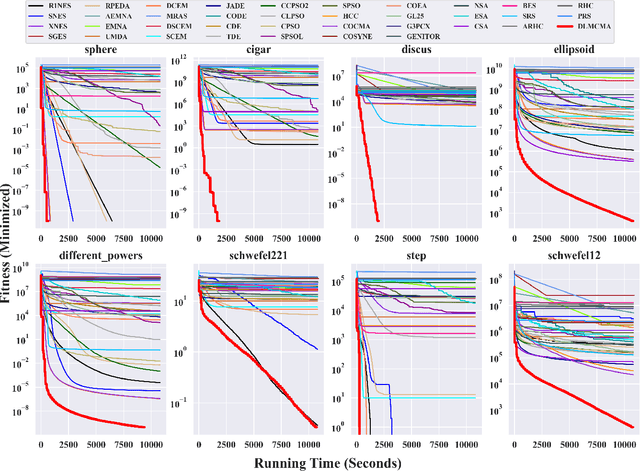

In the post-Moore era, the main performance gains of black-box optimizers are increasingly depending upon parallelism, especially for large-scale optimization (LSO). In this paper, we propose to parallelize the well-established covariance matrix adaptation evolution strategy (CMA-ES) and in particular its one latest variant called limited-memory CMA (LM-CMA) for LSO. To achieve scalability while maintaining the invariance property as much as possible, we present a multilevel learning-based meta-framework. Owing to its hierarchically organized structure, Meta-ES is well-suited to implement our distributed meta-framework, wherein the outer-ES controls strategy parameters while all parallel inner-ESs run the serial LM-CMA with different settings. For the distribution mean update of the outer-ES, both the elitist and multi-recombination strategy are used in parallel to avoid stagnation and regression, respectively. To exploit spatiotemporal information, the global step-size adaptation combines Meta-ES with the parallel cumulative step-size adaptation. After each isolation time, our meta-framework employs both the structure and parameter learning strategy to combine aligned evolution paths for CMA reconstruction. Experiments on a set of large-scale benchmarking functions with memory-intensive evaluations, arguably reflecting many data-driven optimization problems, validate the benefits (e.g., scalability w.r.t. CPU cores, effectiveness w.r.t. solution quality, and adaptability w.r.t. second-order learning) and costs of our meta-framework.
Cooperative Coevolution for Non-Separable Large-Scale Black-Box Optimization: Convergence Analyses and Distributed Accelerations
Apr 11, 2023



Given the ubiquity of non-separable optimization problems in real worlds, in this paper we analyze and extend the large-scale version of the well-known cooperative coevolution (CC), a divide-and-conquer optimization framework, on non-separable functions. First, we reveal empirical reasons of why decomposition-based methods are preferred or not in practice on some non-separable large-scale problems, which have not been clearly pointed out in many previous CC papers. Then, we formalize CC to a continuous game model via simplification, but without losing its essential property. Different from previous evolutionary game theory for CC, our new model provides a much simpler but useful viewpoint to analyze its convergence, since only the pure Nash equilibrium concept is needed and more general fitness landscapes can be explicitly considered. Based on convergence analyses, we propose a hierarchical decomposition strategy for better generalization, as for any decomposition there is a risk of getting trapped into a suboptimal Nash equilibrium. Finally, we use powerful distributed computing to accelerate it under the multi-level learning framework, which combines the fine-tuning ability from decomposition with the invariance property of CMA-ES. Experiments on a set of high-dimensional functions validate both its search performance and scalability (w.r.t. CPU cores) on a clustering computing platform with 400 CPU cores.
A Survey on Automated Design of Metaheuristic Algorithms
Mar 12, 2023



Metaheuristic algorithms have attracted wide attention from academia and industry due to their capability of conducting search independent of problem structures and problem domains. Often, human experts are requested to manually tailor algorithms to fit for solving a targeted problem. The manual tailoring process may be laborious, error-prone, and require intensive specialized knowledge. This gives rise to increasing interests and demands for automated design of metaheuristic algorithms with less human intervention. The automated design could make high-performance algorithms accessible to a much broader range of researchers and practitioners; and by leveraging computing power to fully explore the potential design choices, automated design could reach or even surpass human-level design. This paper presents a broad picture of the formalization, methodologies, challenges, and research trends of automated design of metaheuristic algorithms, by conducting a survey on the common grounds and representative techniques in this field. In the survey, we first present the concept of automated design of metaheuristic algorithms and provide a taxonomy by abstracting the automated design process into four parts, i.e., design space, design strategies, performance evaluation strategies, and targeted problems. Then, we overview the techniques concerning the four parts of the taxonomy and discuss their strengths, weaknesses, challenges, and usability, respectively. Finally, we present research trends in this field.
PyPop7: A Pure-Python Library for Population-Based Black-Box Optimization
Dec 12, 2022In this paper, we present a pure-Python open-source library, called PyPop7, for black-box optimization (BBO). It provides a unified and modular interface for more than 60 versions and variants of different black-box optimization algorithms, particularly population-based optimizers, which can be classified into 12 popular families: Evolution Strategies (ES), Natural Evolution Strategies (NES), Estimation of Distribution Algorithms (EDA), Cross-Entropy Method (CEM), Differential Evolution (DE), Particle Swarm Optimizer (PSO), Cooperative Coevolution (CC), Simulated Annealing (SA), Genetic Algorithms (GA), Evolutionary Programming (EP), Pattern Search (PS), and Random Search (RS). It also provides many examples, interesting tutorials, and full-fledged API documentations. Through this new library, we expect to provide a well-designed platform for benchmarking of optimizers and promote their real-world applications, especially for large-scale BBO. Its source code and documentations are available at https://github.com/Evolutionary-Intelligence/pypop and https://pypop.readthedocs.io/en/latest, respectively.
Representation Learning for Heterogeneous Information Networks via Embedding Events
Jan 29, 2019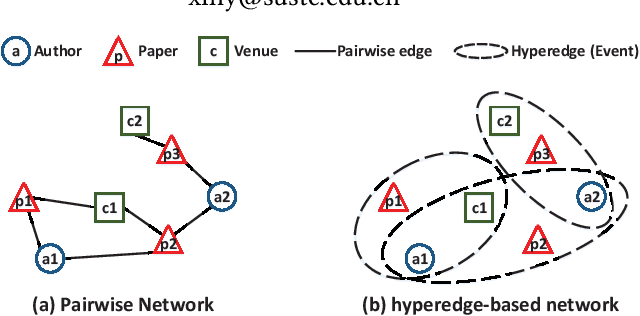

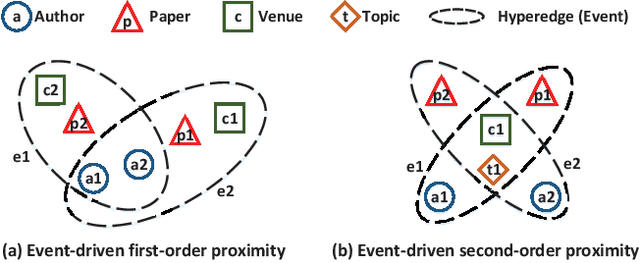
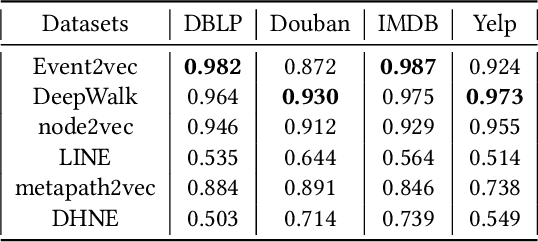
Network representation learning (NRL) has been widely used to help analyze large-scale networks through mapping original networks into a low-dimensional vector space. However, existing NRL methods ignore the impact of properties of relations on the object relevance in heterogeneous information networks (HINs). To tackle this issue, this paper proposes a new NRL framework, called Event2vec, for HINs to consider both quantities and properties of relations during the representation learning process. Specifically, an event (i.e., a complete semantic unit) is used to represent the relation among multiple objects, and both event-driven first-order and second-order proximities are defined to measure the object relevance according to the quantities and properties of relations. We theoretically prove how event-driven proximities can be preserved in the embedding space by Event2vec, which utilizes event embeddings to facilitate learning the object embeddings. Experimental studies demonstrate the advantages of Event2vec over state-of-the-art algorithms on four real-world datasets and three network analysis tasks (including network reconstruction, link prediction, and node classification).